2023 Edge AI Technology Report. Chapter V: TinyML
A Deep Dive Into Edge AI in Energy-Constrained Environments

2023 Edge AI Technology Report. Chapter V: TinyML
Edge AI, empowered by the recent advancements in Artificial Intelligence, is driving significant shifts in today's technology landscape. By enabling computation near the data source, Edge AI enhances responsiveness, boosts security and privacy, promotes scalability, enables distributed computing, and improves cost efficiency.
Wevolver has partnered with industry experts, researchers, and tech providers to create a detailed report on the current state of Edge AI. This document covers its technical aspects, applications, challenges, and future trends. It merges practical and technical insights from industry professionals, helping readers understand and navigate the evolving Edge AI landscape.

Introducing TinyML
Edge AI systems can be deployed in various configurations and across many different types of devices and data sources. For instance, a typical Edge AI configuration involves deploying machine learning models in local clusters of computers, Internet of Things (IoT) gateways, and fog nodes. Such configurations deliver most of the benefits of the Edge AI paradigm, as they improve the latency, performance, energy efficiency, and security of AI applications.
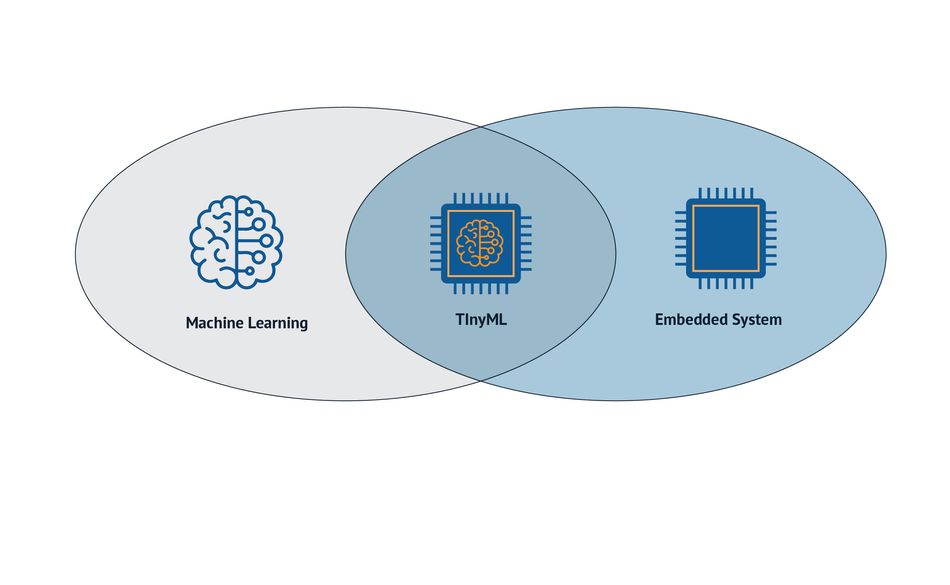
However, there are also Edge AI applications that deploy machine learning models within embedded systems, such as IoT devices. Such configurations fall into the realm of embedded machine learning.
Embedded systems are typically part of another device (e.g., an automobile GPS unit or a smart home device) and perform specialized functions within those products. Embedded machine learning can therefore enhance the intelligence of such functions.
In recent years, there has been a growing interest in TinyML, a novel class of embedded machine learning systems that deploy AI models on microchips and microcontrollers (MCUs) to enable extremely low-power on-device data analytics. MCUs are small single-board computers built around one or more processors with limited memory and computing capacity.
As Martin Croome, VP of Marketing at GreenWaves Technologies, explains, “TinyML targets devices and applications that are extremely energy-constrained. Generally, the device is expected to run on a milliwatt or lower power range.” Devices of this type may be powered by batteries or energy harvesting and are expected to have long battery lives. The specific power constraints drive a broad range of technologies in algorithms, software tools, specific hardware, and sensor technologies. Very often, the requirement for TinyML is combined with a need for ultra-low-power digital signal processing. Examples can range from sensors that are expected to last for several years on batteries to medical devices like pill cameras or consumer products like earbuds, which have tiny batteries that need to last for hours.
With Tiny, it is possible to execute sophisticated machine learning models such as deep neural networks on them. This enables a variety of innovative and always-on use cases, such as on-device image recognition, object tracking, and real-time event detection for security applications. In IoT sensor applications, TinyML is used to interpret rich data sources such as images, sounds, or vibrations. Doing inference on-device reduces the large amounts of data down to compressed metadata such as the presence of and location of a specific object in a picture or a specific sound type. This alleviates the need to transmit the original raw sensor data off of the device, which reduces energy consumption (allowing battery operation) and improves security and privacy. In some cases, the latency required between ‘seeing’ a particular event and taking action precludes transmitting and processing data off of the device.
TinyML is also used in consumer electronics devices such as earbuds. Here more sophisticated deep learning models can be used to analyze incoming sounds, such as the user's voice, and generate filters that can remove unwanted and disturbing noise during calls. This type of neural network belongs to a class that is capable of separating different signals from a mix, such as removing the vocals or lead instruments from a song or separating different speakers.
TinyML techniques are also integrated into products with larger power sources to reduce energy consumption when in standby or idle modes.
TinyML Advantages and Challenges
The power consumption of TinyML deployments is in the order of milli-Watts (mW). This is usually the factor differentiating them from other instances of embedded machine learning. Hence, TinyML deployments drive the benefits of Edge AI to the extreme. Specifically, they tend to outperform other Edge AI deployments in the following aspects:
Latency: TinyML systems do not transfer data to any server for inference, as machine learning functions are executed on the device itself. Thus, they save data transfer time, which optimizes latency as much as possible. Also, this makes TinyML very appropriate for certain types of real-time applications that require immediate feedback.
Power savings: MCUs are extremely low-power devices that can operate for long periods of time without an energy source. This reduces the power needed for executing TinyML operations. Furthermore, these operations are remarkably power-efficient, given the lack of data transfers and I/O operations. These factors make TinyML deployments much more energy-efficient than other forms of Edge AI.
Bandwidth savings: Unlike other Edge AI configurations, TinyML deployments do not rely on internet connectivity for inference. Data are captured and processed on the device rather than transferred to some server. Thus, TinyML systems end up being extremely bandwidth-efficient, as well.
Stronger Privacy and Data Protection: In the scope of a TinyML deployment, there are no data on fog nodes and other servers. This makes it impossible for malicious actors to access sensitive information by hacking edge servers or networking devices. Overall, the execution of machine learning models on an embedded device leads to stronger data privacy guarantees.
Increased Efficiency and Flexibility: MCUs and other embedded devices are smaller in size than servers and personal computers. This means they require much less space and power while providing increased deployment flexibility. For instance, TinyML systems offer one of the best ways to deploy machine learning models in places where there is not enough space for bulky equipment.
Nonetheless, a few challenges and limitations still take place when developing, deploying, and running machine learning on embedded devices and microcontrollers. One of the main challenges relates to data collection processes. Given the limited amount of power available, it is quite difficult to collect large amounts of data for TinyML training tasks. This is also why there is limited availability of datasets for embedded machine learning and TinyML tasks.
Another challenge is the lack of computing capacity and memory for processing large amounts of information. This is generally a setback to implementing certain tasks (e.g., video scene analysis) within MCUs and other embedded systems.
TinyML deployments are also associated with a skill-gap challenge. Developing and deploying TinyML applications require multi-disciplinary teams that combine embedded systems and data science expertise. This is a challenging combination, considering the proclaimed gap in data science and embedded systems development skills.
Tools and Techniques for TinyML Development
The key algorithmic technologies for TinyML cover techniques to run large machine-learning models efficiently. These techniques cover model compression (reducing the size of the model) and model optimization (arranging the computation of the model in ways that reduce power consumption). Dedicated hardware is used to minimize computational energy use and costly movement of data. The interaction between sensor data collection, preprocessing, and inference in different applications and the speed of change in techniques means that there is a large need for hardware that preserves flexibility in the approach used to implement TinyML applications.
State-of-the-art TinyML processors and their toolchains are able to process deep neural networks such as object detectors that previously consumed 100s of milliwatts or even watts at power levels below a milliwatt.
The development and deployment of TinyML applications are based on machine learning, data science, and embedded systems programming tools. In principle, popular data science tools (e.g., Jupyter Notebooks, Python libraries, and tools) are used to train a machine learning model. Accordingly, the model is shrunk in size to fit the embedded device. In this direction, many popular machine learning tools offer options and features for embedded development.
As a prominent example, a special edition of the popular TensorFlow suite of ML tools is designed for inference on devices with limited computing capacity, such as phones, tablets, and other embedded devices. This edition is called TensorFlow Lite, which is Google’s lightweight, low-power version of TensorFlow.
Another special version of TensorFlow Lite for microcontrollers, namely TensorFlow Lite Micro, enables the deployment of models on microcontrollers and other devices with only a few kilobytes of memory. For instance, the core runtime of TensorFlow Lite Micro can fit in just 16 KB on an Arm Cortex M3.
Furthermore, embedded systems tools like the Arduino IDE can be used to transfer and execute small-sized models on the embedded device.
The training and development of TinyML pipelines are generally subject to the same model performance criteria as other ML pipelines. Nevertheless, TinyML developers must also consider additional factors prior to deploying a model to production.
For instance, they must consider whether the model’s size fits the available memory and how well it performs in terms of execution speed. Likewise, they may also have to assess its impact on the device’s battery life.
TinyML in Action: How GreenWaves Enable Next-Generation ProductsCombining homogeneous processing units with integrated hardware acceleration blocks is designed to achieve a perfect balance between ultra-low power consumption, latency, flexibility, and ease of programming. GAP9 from GreenWaves Technologies is a combination of a robust low-power microcontroller, a programmable compute cluster with a hardware neural network accelerator, and a sample-by-sample audio filtering unit. The compute cluster is perfectly adapted to handling combinations of neural network and digital signal processing tasks delivering programmable compute power at extreme energy efficiency. Its architecture employs adjustable dynamic frequency and voltage domains and automatic clock gating to tune the available compute resources and energy consumed to the exact requirements at a particular point in time. GAP9’s unique Smart Filtering Unit is perfectly adapted to ultra-low latency (1uS) PDM to PDM filtering tasks but so flexible that it can simultaneously be used as a block filtering coprocessor for tasks executing on the cores. The SFU is linked to GAP9’s 3 Serial Audio Interfaces, capable of handling up to 48 incoming or outgoing audio signals. Its SDK allows a simple path from NN development packages, such as TensorFlow and PyTorch to C code running on GAP9. GAP9’s hierarchical and demand-driven architecture is focused on bringing signal processing with embedded artificial intelligence into the next generation of hearable products and applications for battery-powered smart sensors. |
The New Kid on the Block
The rising popularity of TinyML has given rise to more sophisticated application development and deployment tools. For instance, many hardware vendors and OEMs (Original Equipment Manufacturers) offer visual AutoML (Automatic Machine Learning) tools, which ease the process of developing and deploying TinyML pipelines. In several cases, these tools offer options for monitoring the power consumption, performance, and speed of the TinyML deployment while facilitating their integration into other Edge AI systems in the cloud/edge computing computing continuum.
Shay Kamin Braun of Synaptics explains that TinyML has gained this popularity due to the potential advantages it brings to the industry and to various players in terms of application, design, and usability. As it is suitable for resource-constrained environments in both memory and processing power, TinyML allows us to design smaller products with lower costs and lower power consumption. “The lower costs of TinyML,” clarifies Kamin Braun, “is enabled by utilizing lower-performance processors. And very importantly, lower power consumption leads to the ability to design devices that run on batteries and last a long time (i.e., multiple years, depending on the application).”
Nonetheless, TinyML is still in its infancy. As Kamin Braun told Wevolver, “We will see more of it in the near future, with applications in command detection (Wake word and phrase detection models), acoustic event detection (for security, smart homes, and industrial applications), and Vision AI (detecting people, objects, and movement) despite its minimal implementation today.” TinyML’s rather huge potential is the main reason for its popularity as compared to its actual implementation.
“We’re just seeing the tip of the iceberg now. We expect exponential growth as more and more companies are creating small, high-performance models. Fast, low-cost deployment is slowly coming but not in mass yet. Maybe it will in a year or so.” - Shay Kamin Braun, Director of Product Marketing, Synaptics.
The 2023 Edge AI Technology Report
The guide to understanding the state of the art in hardware & software in Edge AI.
Click through to read each of the report's chapters.
Chapter I: Overview of Industries and Application Use Cases
Chapter II: Advantages of Edge AI
Chapter III: Edge AI Platforms
Chapter IV: Hardware and Software Selection
Chapter V: Tiny ML
Chapter VI: Edge AI Algorithms
Chapter VII: Sensing Modalities
Chapter VIII: Case Studies
Chapter IX: Challenges of Edge AI
Chapter X: The Future of Edge AI and Conclusion
The report sponsors:
