DOT-HAZMAT: An Android application for detection of hazardous materials (HAZMAT)
A student article showcasing an Android application called DOT-HAZMAT based on Machine Learning and Computer Vision that locates and categorizes HAZMAT placards in perilous rescue operations.

23 Jul, 2022. 18 minutes read

Representational image of soldiers participating in toxic industrial chemical protection and detection equipment training. Source: USArmy-Flickr
This article was first published on
www.flickr.comThis article is a part of our University Technology Exposure Program. The program aims to recognize and reward innovation from engineering students and researchers across the globe.
Introduction
The inspiration for the project stems from the fact that the HAZMAT signs play a crucial role in rescue operations and hence require an accurate detection tool in cases of accidents caused by hazardous materials. They are considered to be important in pursuing rescue operations efficiently.
Accordingly, in our project, we propose a DOT HAZMAT (Detection of Threat: Hazardous Materials) Android application to detect the presence of these signs regardless of the particular lighting situation, over a wide range of distances and under varying degrees of rotation and to also detect occluded, overlapped, and partially visible signs since each sign must be detected and interpreted to take a swift action immediately in order to ensure safety.
Furthermore, having learned about the predictions made by deep-learning-based object detection models [1], it only seemed fair to put theory to practical usage by building a tool to aid first responders and rescue teams in on-ground operations. [12] To put it briefly, the DOT-HAZMAT application was built by performing the following steps in order:
Creating a training dataset
Training the dataset with YOLOv5-CNN Architecture
Weights Conversion and Model Optimization for Android
Increasing the scope of detections with OCR
Android App Design and Deployment
The paper further in its sections would provide details on the approach taken by us to build the model and integration of feature services in the application. The overall idea of building a HAZMAT sign detection tool was to explore the maximal potential of what neural networks can offer and open-source libraries can do with computer vision for solving problems of extreme importance.
Related Works
Developing a HAZMAT sign detection pipeline that accurately gives results is a difficult undertaking. Although each sign is vibrant and easily identifiable, in cases of calamities the sign might not be properly visible even to the naked human eye. There has been significant research when it comes to studying sign detection models with various algorithms and techniques in multiple domains. Many authors have carried out experiments on the topic, with attempts made to solve the aforementioned issue.
There are several approaches and methods for HAZMAT sign detection. The literature survey we carried out focused upon color-based, shape-based, and deep learning-based methods. After understanding the limitations and weaknesses of the first two methods, we finalized the latter. The paper [1] deals with the development of a robotic machine vision system for hazmat label recognition. They implemented classical computer vision methods and state-of-the-art deep learning-based detection algorithms to detect hazmat signs. The algorithms employed were also thoroughly evaluated. The authors aimed to train a deep neural network model; however, the proposed model failed to detect HAZMAT signs in complex backgrounds. Special focus was put on the robustness of detection and recognition with limited hardware resources and the influence of background image structures and light conditions. This paper formed the basis of the project.
The first and most significant step of any deep learning project is to determine the architectural framework of the model. In concurrence with our problem statement, a paper [2] proposed an improved method for the detection of planar objects, which rectifies images with geometric information to compensate for the perspective distortion before feeding it to the CNN detector module, typically a CNN-based detector like YOLO or MASK- RCNN. The proposed method computes the homography to transfer between 3D and 2D perspective images. Following that, they rectify the image to cope with the distortion effects, and the resulting images are fed to a CNN detector. By dealing with the perspective distortion in advance, they eliminated the need for the CNN detector to learn that. Besides, the method also effectively reduced the number of training images required. The advantage of this approach is the ability to detect the HAZMAT signs at various angles but it requires a very high computational cost. Therefore, this system is also not feasible for real-time performances. Furthermore, it needs additional sensors than common HAZMAT detection systems.
Since in the papers before, execution speed and detection accuracy of existing CNN models cannot be achieved at the same time which increases the detection cost, this paper [3] proposed a new YOLO model and improved CNN model. Traffic Sign Detection is a hotspot in autonomous driving and assisted driving research. They introduced batch normalization and RPN networks and improved the network structure for traffic sign detection tasks to optimize the YOLO neural network detection. The results showed that the proposed method was of great help to improve the accuracy and detection speed of traffic sign detection and to reduce the hardware requirements of the detection system.
Proposed System
The proposed deep learning model will detect thirteen HAZMAT signs which essentially includes a YOLOv5-CNN model [6] trained in Pytorch and deployed on Android via Tensorflow Lite to predict classes with optimized accuracy and confidence. Along with this, the DOT-HAZMAT Android application also offers real-time optical character recognition service for detecting text of HAZMAT signs via Google’s ML Kit Public Text Recognizer API to also include the relative words of globally recognized HAZMAT signs within the scope of accurate detection.
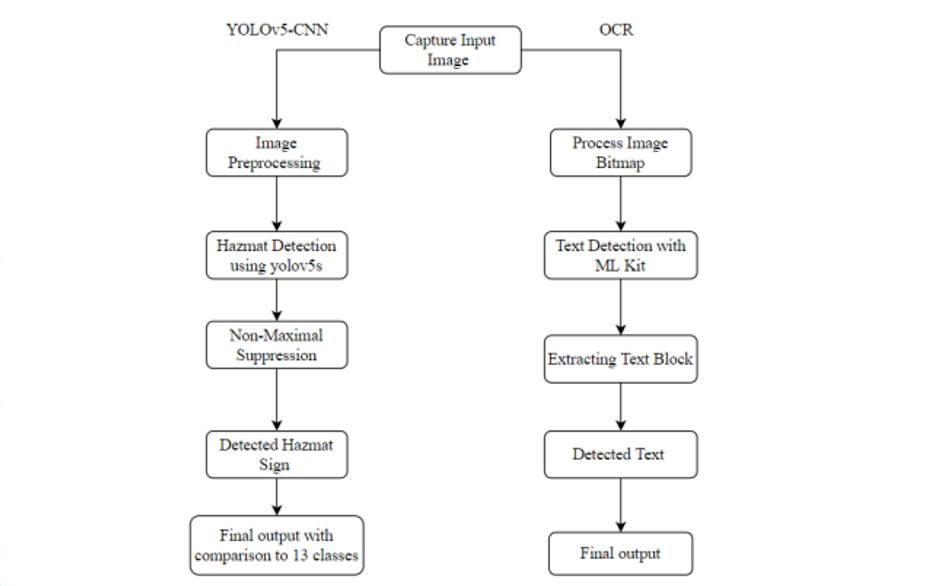
Fig 1: Conceptual Diagram for the App Model Framework
As evident in Fig1 the model takes into account the test image and runs preprocessing on the image before executing detection using YOLOv5.
Developing a HAZMAT sign detection pipeline that accurately gives results is a difficult undertaking. Although each sign is vibrant and easily identifiable, in cases of calamities the sign might not be properly visible even to the naked human eye. There has been significant research when it comes to studying sign detection models with various algorithms and techniques in multiple domains. Many authors have carried out experiments on the topic, with attempts made to solve the aforementioned issue.
There are several approaches and methods for HAZMAT sign detection. The literature survey we carried out focused upon color-based, shape-based, and deep learning-based methods. After understanding the limitations and weaknesses of the first two methods, we finalized the latter. The paper [1] deals with the development of a robotic machine vision system for hazmat label recognition. They implemented classical computer vision methods and state-of-the-art deep learning-based detection algorithms to detect hazmat signs. The algorithms employed were also thoroughly evaluated. The authors aimed to train a deep neural network model; however, the proposed model failed to detect HAZMAT signs in complex backgrounds. Special focus was put on the robustness of detection and recognition with limited hardware resources and the influence of background image structures and light conditions. This paper formed the basis of the project.
The first and most significant step of any deep learning project is to determine the architectural framework of the model. In concurrence with our problem statement, a paper [2] proposed an improved method for the detection of planar objects, which rectifies images with geometric information to compensate for the perspective distortion before feeding it to the CNN detector module, typically a CNN-based detector like YOLO or MASK- RCNN. The proposed method computes the homography to transfer between 3D and 2D perspective images. Following that, they rectify the image to cope with the distortion effects, and the resulting images are fed to a CNN detector. By dealing with the perspective distortion in advance, they eliminated the need for the CNN detector to learn that. Besides, the method also effectively reduced the number of training images required. The advantage of this approach is the ability to detect the HAZMAT signs at various angles but it requires a very high computational cost. Therefore, this system is also not feasible for real-time performances. Furthermore, it needs additional sensors than common HAZMAT detection systems.
Since in the papers before, execution speed and detection accuracy of existing CNN models cannot be achieved at the same time which increases the detection cost, this paper [3] proposed a new YOLO model and improved CNN model. Traffic Sign Detection is a hotspot in autonomous driving and assisted driving research. They introduced batch normalization and RPN networks and improved the network structure for traffic sign detection tasks to optimize the YOLO neural network detection. The results showed that the proposed method was of great help to improve the accuracy and detection speed of traffic sign detection and to reduce the hardware requirements of the detection system.
Following that the Non-Maximal Suppression suppresses all the redundant bounding boxes and keeps the boxes with maximum confidence per class fetching the region of interest in the image. Later, image is then classified into one of the 13 classes. In cases of low confidence, this image can also then be passed to the OCR to confirm the detection results. This helps to achieve higher confidence about the detected class, detailed information about the classified sign by analyzing the text, and also can help to cross verify the output from the CNN pipeline.
The services DOT-HAZMAT Application offers are
1. Yolov5 Object Detection with NMS (Non Maximal Suppression)
2. Optical Character Recognition for Text Detection
Methodology
In this section, we would discuss in detail the five steps involved in building the DOT-HAZMAT Application.
Dataset
For any deep-learning model, the most important factor defining the quality and behavior of networks is a well-structured dataset consisting of all possible diverse scenarios. [8]
We have implemented Convolutional Neural Networks (i.e YOLO here) in a supervised learning approach. For that, we had to prepare and provide labeled images constituting the ground truth data for training the neural network. Accordingly, having reviewed all the publicly released datasets, we realized that there isn’t a detailed dataset covering images of as many as possible varied conditions such as noise, exposure levels, rotation, lighting situation, etc. Therefore, we tried to incorporate a variety of images from different scenarios to achieve a quality dataset for training the DOT-HAZMAT YOLO-CNN model as the dataset plays a significant role in determining the accuracy of the model.

Fig.2: 13 HAZMAT signs present in the dataset [1]
Hence, referring to the source of the publicly released dataset by [1], we took the original model of 1685 images annotated in PASCAL-VOC format and created an all-encompassing dataset of 15323 images.
The structure of the dataset was as follows:- Training: 80% i.e 12589 images
Validation: 10% i.e 1367 images
Testing: 10% i.e 1367 images
The images were resized as 416 × 416 into 13 HAZMAT Sign classes on RoboFlow and increased the number of images in the dataset by introducing the following data augmentation [7] properties:
2.5 px blur
5% noise
Exposure +20% -20%
Darken 20%
Rotation + 15 degrees -15 degrees

Fig.3: Sample dataset images with the above-mentioned augmentation properties.
Hereby, we publicly release our dataset hosted on Roboflow which can be accessed here.
Training with YOLOv5 and Comparison with other models
Firstly, with a number of state-of-the-art computer vision models for object detection, it became primary to analyze and identify the most optimal CNN (Convolutional Neural Network) Architecture for detecting HAZMAT signs. Out of the three most
promising models in the market - SSD (Single Shot Detection), YOLO (You Only Look Once) [13] [14], and Faster R-CNN (Region-based Convolutional Neural Network), considering the research so far, YOLO model with its improved modifications was the fastest and rated highest inaccuracy with SSD following closely and Faster RCNN coming in the last place. [16]
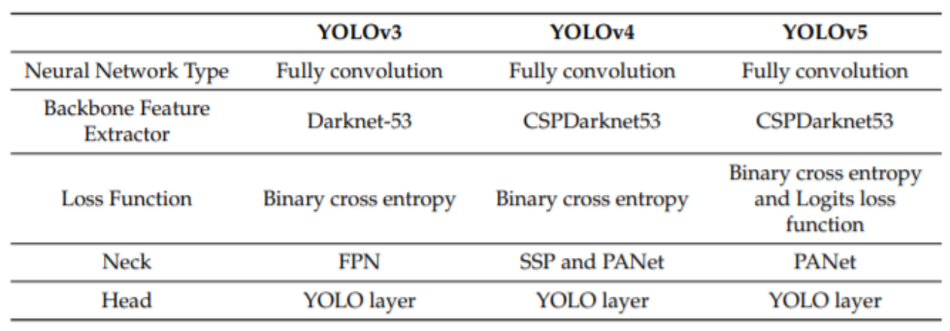
Lastly, taking into consideration the new and recent versions of the YOLO model, a comparative study was performed to identify the features of the YOLO Version 3, Version 4, and Version 5 (small and large). Out of all the available models, YOLOv5 stood out as the most optimum choice considering its newly modified PANet neck and focus structure layer with CSPdarknet53 as a backbone offering maximal feature extraction for input images at real-time detection.
YOLOv5 Architecture
The input, backbone, neck, and output components make up the YOLOv5 architecture. The input terminal is mostly used for data preprocessing, such as mosaic data augmentation and adaptive image filling. To adapt to a variety of datasets, YOLOv5 uses adaptive anchor frame computation on the input, which allows it to automatically set the initial anchor frame size when the dataset changes.
Through a cross-stage partial network (CSP) and spatial pyramid pooling(SPP), the backbone network extracts feature maps of various sizes from the input image using multiple convolution and pooling. The SPP structure realizes feature extraction from different scales for the same feature map and can generate three-scale feature maps, which helps to improve detection accuracy. BottleneckCSP is used to reduce the amount of calculation and increase the speed of inference, whereas the SPP structure realizes feature extraction from different scales for the same feature map and can generate three-scale feature maps, which helps improve detection accuracy.
FPN and PAN feature pyramid structures are employed in the neck network. The FPN structure is used to send strong semantic features from the top feature maps to the bottom feature maps. Simultaneously, the PAN structure transports strong localization features from lower to higher feature maps. By merging the features generated from different network levels in Backbone fusion, these two structures work together to improve detection capability. The head output is mostly used to predict targets of various sizes on feature maps as a final detection step.
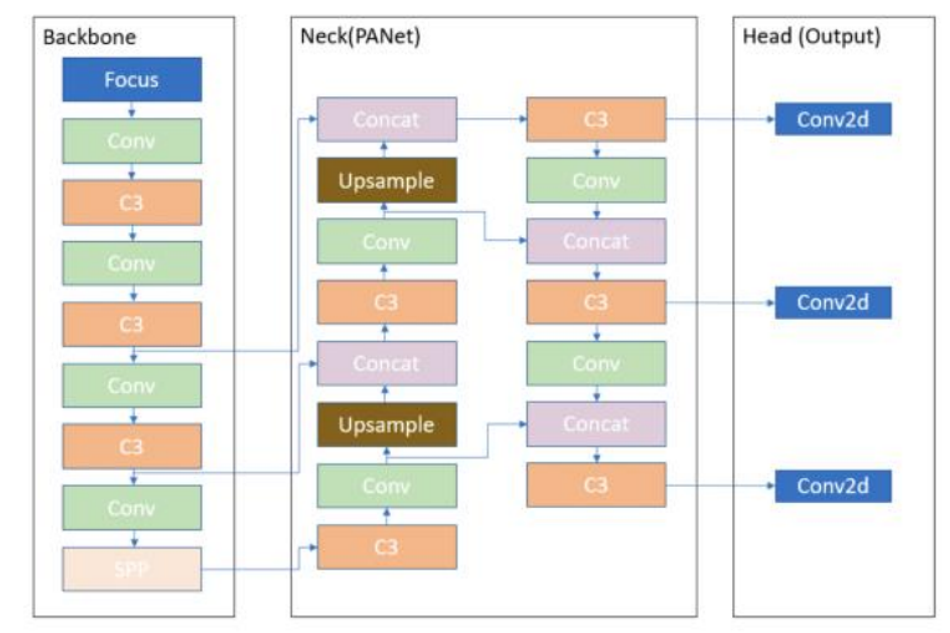
Fig.5: The architecture of YOLOv5 model [5] The YOLOv5 consists of four architectures, named YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. The main difference between them lies in the number of feature extraction modules and convolution kernels at specific locations in the network.

To add on, YOLOv5 is currently a developing opensource repository on Github authored primarily by Glenn Jocher and published through Ultralytics with detailed documentation. Following that, two training sessions were conducted to build the custom model for detecting HAZMAT signs in YOLOv5s and YOLOv5l on an online browser-based platform i.e Google Colab Pro, which provided an Intel (R) Xeon (R) CPU @ 2.30GHz CPU, 25 GB of Memory and K80, P100, T4 GPU for building the custom model.
TABLE 1: Training parameters for the two models
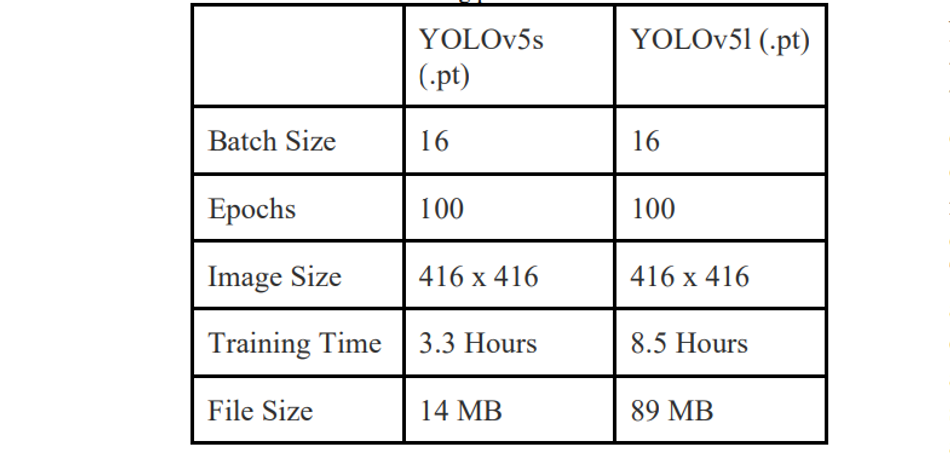
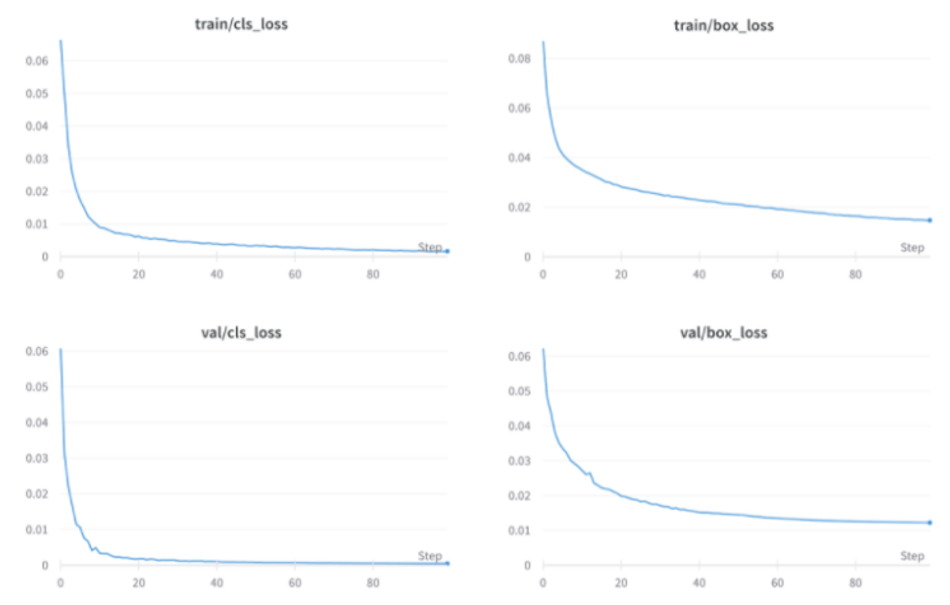
Fig. 7: Training loss for classes and bounding boxes over 100 epochs (YOLOv5s)
The results obtained by running YOLOv5s.pt on test images demonstrated exemplary detections with the model being able to detect HAZMAT signs even in very poor lighting situations, rotated and noisy backgrounds, as shown below.


Fig.8: Test images with detections performed by YOLOv5s.pt 2.2 Non-Maximal Suppression NMS (Non Maximum Suppression) is a computer vision approach that is utilized to filter a number of bounding boxes. It's a class of algorithms for picking one thing bounding box out of the many overlapping ones. Most object detectors utilize windowing at the most basic level, resulting in hundreds of thousands of windows (anchors) of varied sizes and shapes. These windows are said to contain only one object, and each class is assigned a probability/score by a classifier. Generally, some sort of probability number and some form of overlap measure are used as selection criteria (e.g. Intersection over Union) to achieve results.
Non-Maximal Suppression Algorithm (Pseudocode) :
Step 1: Select the box with highest objectiveness score
Step 2: Then, compare the overlap (intersection over union) of this box with other boxes
Step 3: Remove the bounding boxes with overlap (intersection over union) >50%
Step 4: Then, move to the next highest objectiveness score
Step 5: Finally, repeat steps 2 through 4
Generally, NMS is employed in most Object Detection networks as their final step of detection and so does YOLOv5 in the Pytorch framework. But, the current Ultralytics YOLOv5 Github repo does not support this conversion for object detection models in exported models frameworks such as Tensorflow Lite since it’s a developing repository. One can see more details of all the limitations and experiments for exported models in this Github thread discussion.
Hence, we decided to integrate NMS explicitly in the DOT-HAZMAT Android project later to improve real-time detections with YOLOv5.
Weights Conversion and Model Optimization
Now, to achieve an optimized model which could be deployed on Android, post-training hybrid quantization was performed. The weights built after training in Pytorch (.pt file) were converted into Tensorflow Lite (.tflite file).and inferences were run to check their accuracy after conversion.
The conversion of weights from Pytorch to tflilte witnessed the following changes in the behavior of the model:
The real-time quantized tflite model in FP16 was smaller and more optimized than the original model.
The tflite model suffered a slight loss of accuracy and increased latency.
Essentially, to ensure that model could run detections with even minimum computational resources on Android applications, we made a trade-off between accuracy and efficiency. Later, the tflite weights file along with the custom YOLOv5.yaml architecture file were integrated with the Android project for detection of HAZMAT signs.
Optical Character Recognition (OCR) Test
To the best of our knowledge, text detection has not been implemented so far by any of the proposed work until now and also since the model conversion from Pytorch to TensorFlow Lite for mobile applications suffered a loss in accuracy, we decided to include OCR [9] as a feature for detection in DOT-HAZMAT application.
It was included to provide the users with an alternative and to further scale the accuracy and to reduce the cases of incorrect labeling. This was achieved by integrating Google ML Kit’s mobile SDK via Firebase to DOT-HAZMAT Android’s application project that brings Google's on-device machine learning techniques to Android and iOS applications and implementing detections via its Text Recognizer API.
Steps for Integration of Google ML-Kit’s Text Recognizer to predict text in captured images :
A TextRecognizer instance is created.
Next, an InputImage object is generated from image Bitmap to recognise text in an image.
Then, the InputImage object is passed to the TextRecognizer's processImage method.
Following that, a Text object is delivered to the success listener if the text recognition process succeeds. (The whole text identified in the image is contained in a Text object, which also contains zero or more TextBlock objects. Each TextBlock represents a rectangular block of text, which contains zero or more Line objects. There are zero or more Element objects in each Line object, which represent words and word-like elements.)
For each TextBlock, Line, and Element object, the text recognized in the region and the bounding coordinates of the region are obtained.
The final results are then displayed on the Text Detector screen of the application.
This feature also helped to increase the scope of detection beyond the thirteen specified classes’ names on which the YOLO-CNN model was trained and included near-relative words of the HAZMAT signs.

Fig.9: Example HAZMAT signs of the same class, but with different texts.[1]
It must be noted that to run accurate text detections via Google ML Kit’s Text Recognizer, the user must have Google Play Store (recommended latest version) installed on their local Android device.
Android Application Design and Deployment
Having trained the model in both YOLOv5s and YOLOv5l frameworks, we observed that the improvement in evaluation metrics from small to large model wasn’t significant enough to allow a 4x bigger model file to be deployed on the Android application. Hence, we integrated the YOLOv5s model in the Android project followed by NonMaximal Suppression and OCR as an independent feature service in the application [11].
The Application Design is fairly simple and involves three screens on a whole.
All the screenshots of the DOT-HAZMAT Application attached below were captured from app testing on Android Emulator Pixel 4 (1080x2280 resolution and 440dpi density) (Google Play) API 32 [15].
1) Home Page
The Homepage of the application offers three services via buttons as mentioned.
a) Detect: It allows the user to run detection on the test image available in the frame above to understand how the detection results look.
b) Camera: It allows the user to detect the HAZMAT sign via rear camera on device or Webcam on Desktop. It directs to the second screen of the application.
c) OCR: As the name suggests, it allows the user to perform text detections. It directs to the third screen of the application.
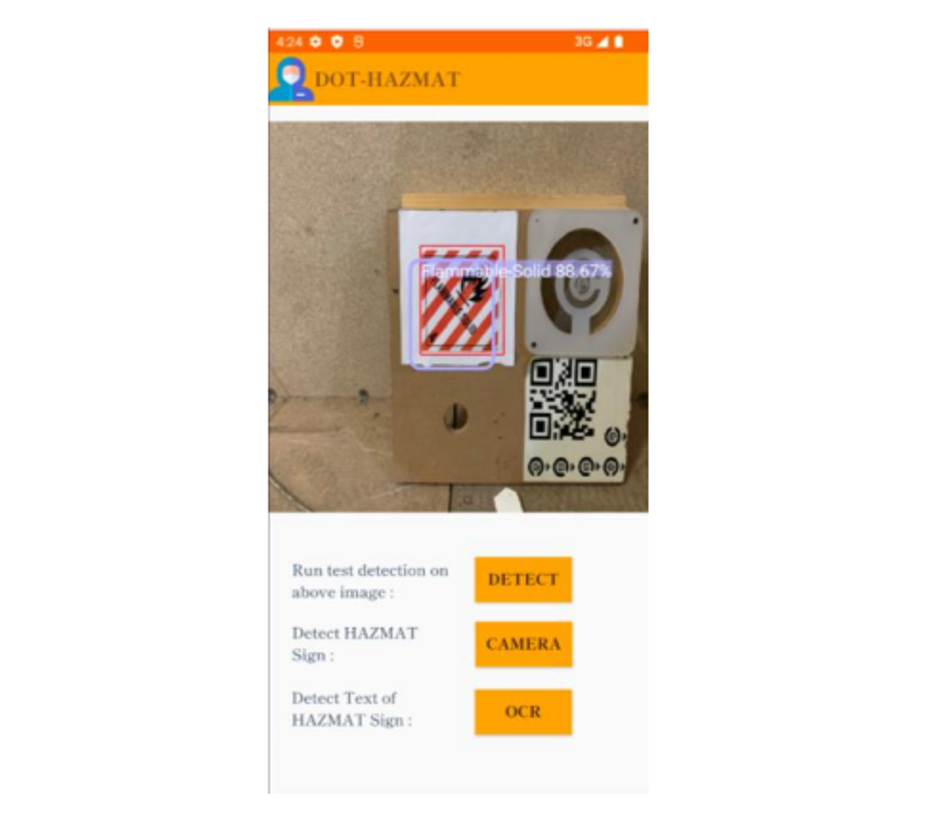
Fig.10: Application User Interface (Home page) with detected sign output of on test image by ‘Detect’ Button.
2) Real-time Detector Page via Camera/Webcam
Here, as one can witness the YOLOv5s model makes an accurate detection of multiple HAZMAT signs in picture with an average run-time accuracy of around 85% for that very instance with stable positioning and resolution.
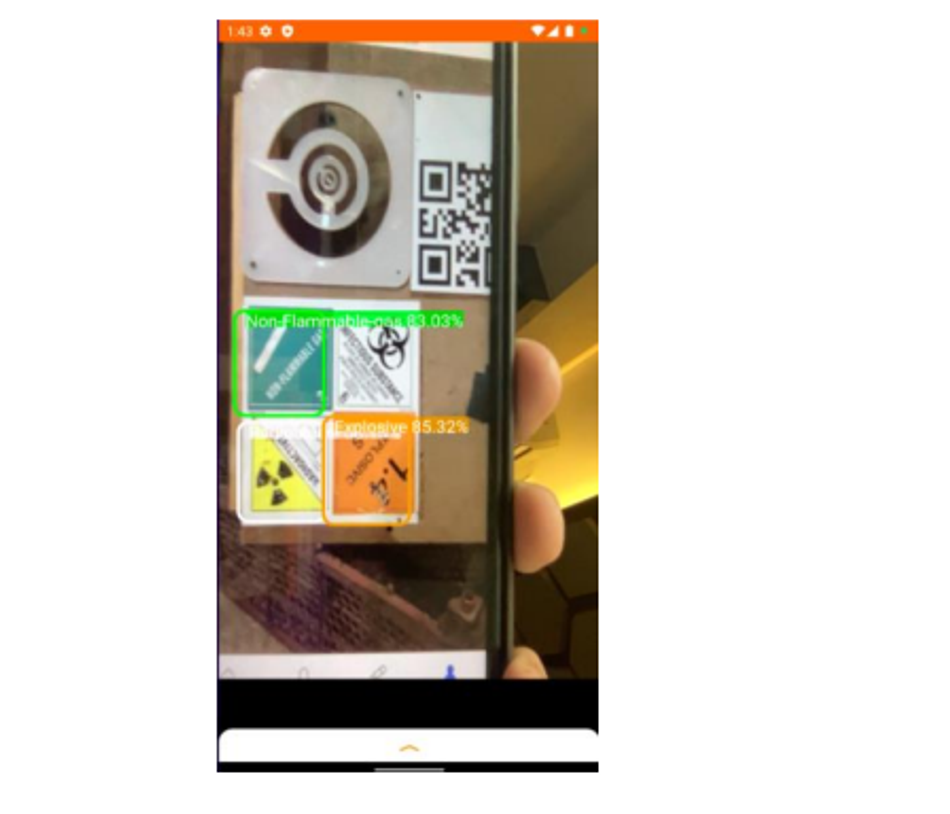
Fig.11: Detection carried out in Application through the deployed Tensorflow Lite YOLOv5s model.
3) Text Detector Page:
For the text detector, initially one needs to click on the ‘Capture’ button which prompts the Android device to open its camera and click a picture with HAZMAT sign in sight with good pixel resolution. And later, tap on the ‘Detect Text’ button for triggering the Google ML Kit API to run and display results in the box above. In cases of unclear images or no text in sight, the application would request the user to capture a new image.
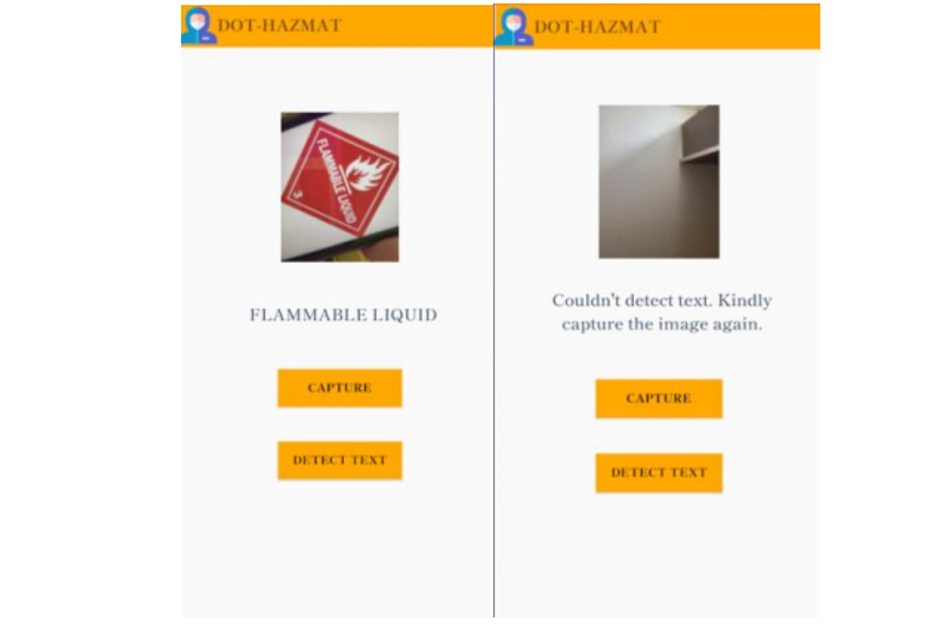
Fig.12: Text Detection Interface in action with recognized text on screen.
Along with this, Firebase as an interface for tracing the user activities on the application with respect to detections and location has been integrated in the DOT-HAZMAT application in an effort to perform future analytics.
Fig.13: Analytics Dashboard for the DOT-HAZMAT App hosted via Firebase Console
Results
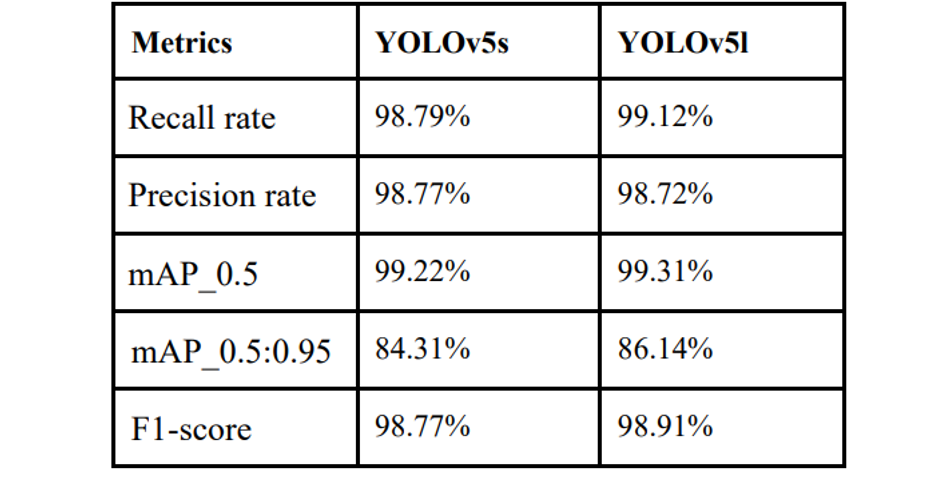
This section includes the evaluation of YOLOv5s (Pytorch) model on key evaluation metrics and affirms the accuracy of the model.
Evaluation Metrics
1) Precision Rate: Precision, also called positive predictive value, is the fraction of relevant instances among the retrieved instances.
Precision rate achieved by the DOT-HAZMAT YOLOv5s is 0.9877
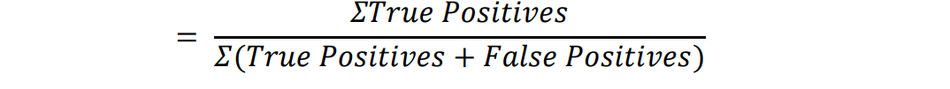
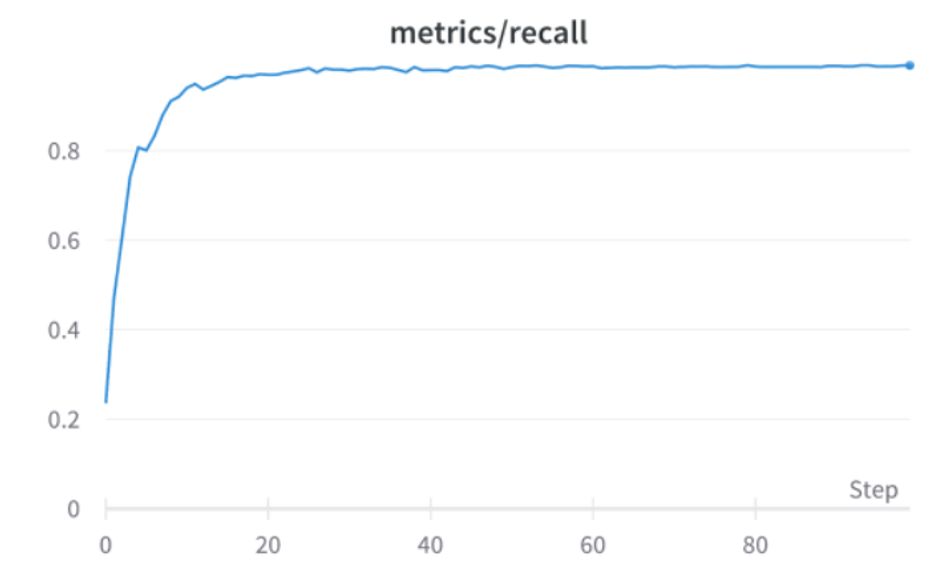
Fig 14: Recall Graph of DOT-HAZMAT over 100 epochs
2) Recall Rate: Recall, also called sensitivity, is the fraction of relevant instances that were retrieved.
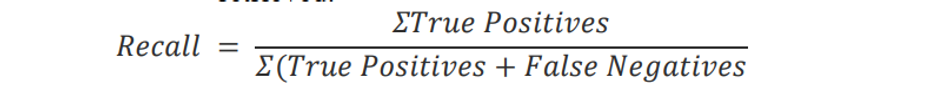
Recall rate achieved by the DOT-HAZMAT YOLOv5s is 0.9879
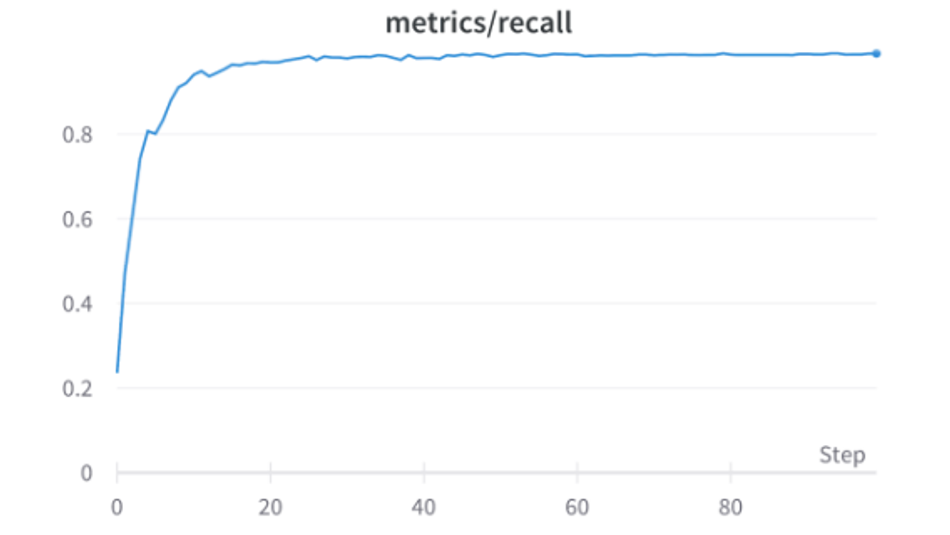
Fig 14: Recall Graph of DOT-HAZMAT over 100 epochs
3) mAP_0.5: mAP(mean average precision) is a metric that is used to evaluate object detection models like YOLO. The calculation of mAP requires Intersection Over Union, Precision, Recall, Precision Recall Curve, and AP.
IOU - Intersection Over Union (IOU) is used to determine if the bounding box was correctly predicted. The IOU indicates the overlap regions between the bounding boxes. In the case of an exact match, the ratio of bounding boxes becomes exactly 1.0 and if there is no overlap the ratio is 0.0. It is crucial to determine how much bounding box overlap with regard to the ground truth data should be deemed successful recognition when evaluating object detection models.
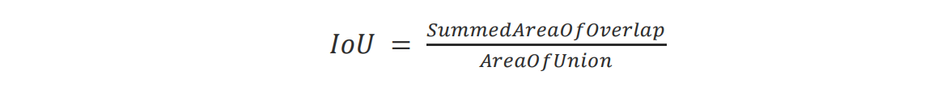
mAP50 is the accuracy when IOU=50, ie, if there is more than 50% overlap, the detection is considered successful. The greater the IOU, the more precise the bounding box must be detected, making it more challenging.

mAP_0.5 rate achieved by the DOT-HAZMAT YOLOv5s is 0.9922
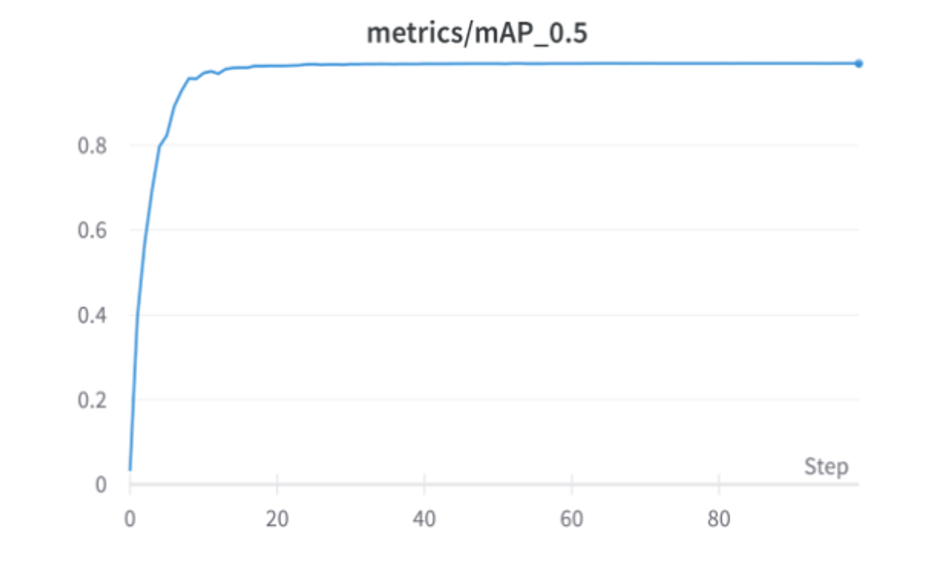
Fig 15: mAP_0.5 Graph of DOT-HAZMAT over 100 epochs.
4) mAP_0.5:0.95 : mAP_0.5:0.95 means average mAP at various IoU thresholds, ranging from 0.5 to 0.95, with a 0.05 step (0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95)
mAP_0.5:0.95 achieved by the DOT-HAZMAT YOLOv5 is 0.8431
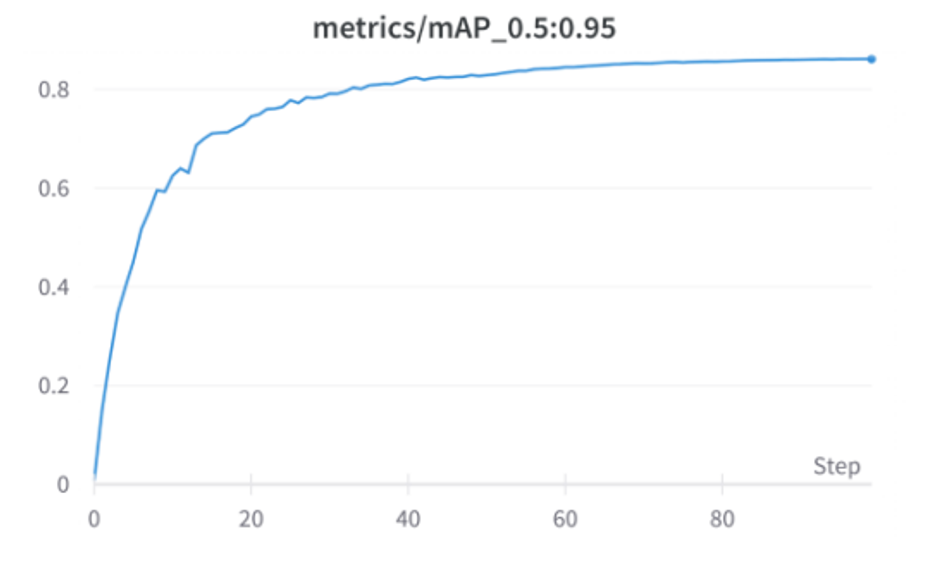
Fig 16: mAP_0.5:0.95 Graph of DOT-HAZMAT over 100 epochs
5) F1-Score: F1-score, is a measure of a model's accuracy on a dataset. It is used to evaluate binary classification systems, which classify examples into 'positive' or 'negative'.
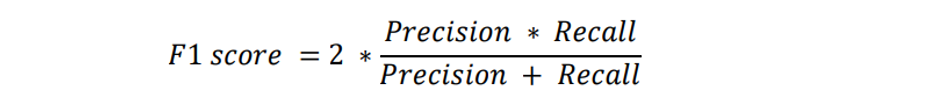

Fig.17: F1 curve of DOT-HAZMAT
TABLE 2: Evaluation metrics for the two models
6) Confusion Matrix: The model’s accuracy for each class is displayed through the confusion matrix. The actual labels are displayed on the horizontal axis, while the anticipated labels are displayed on the vertical. As it can be observed that for the majority of classes, the model predicts and classifies the images correctly with 100% accuracy. Besides this, the confusion matrix shows there are significantly low numbers of cases when the model misclassified a few classes such as explosives and gave false positives for the background. A similar kind of miniscule error in classification is seen in inhalation hazard and a few others in smaller numbers.
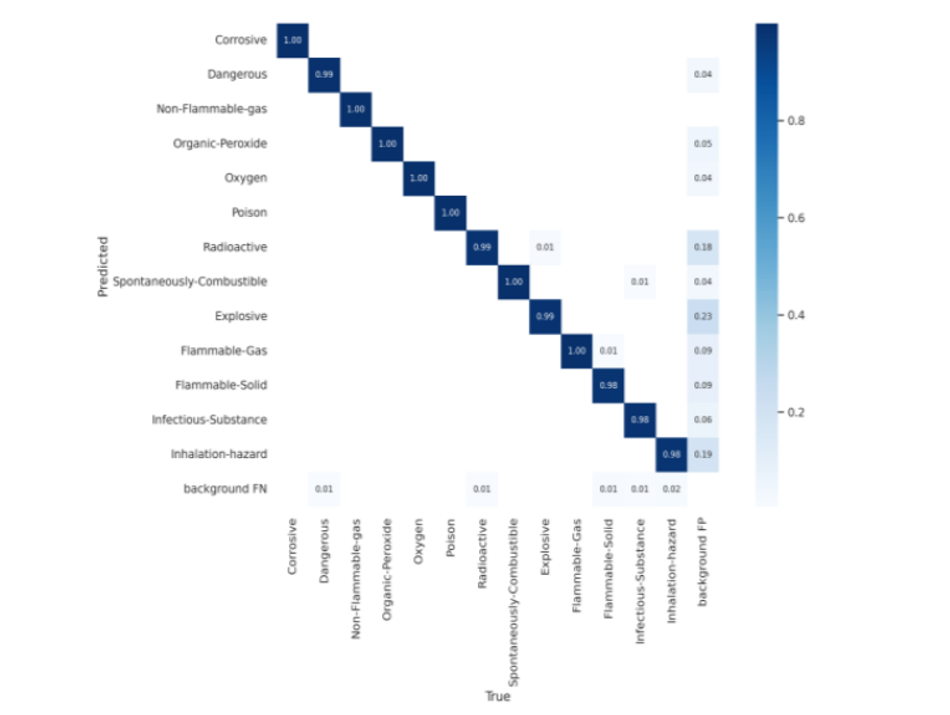
Fig.18: Confusion Matrix
LIMITATIONS AND CHALLENGES We have observed certain limitations and gaps in our model which could be covered and implemented in future research studies:
The accuracy of the quantized TensorflowLite FP-16 model can be certainly improved while keeping the file size to the minimum.
The ML Kit’s Text Recognizer fails to predict text accurately in cases of lower input image pixel resolution.
The HAZMAT sign detection model can be merged with segmentation and text detection algorithms to generate more accurate results while performing real-time detections.
Conclusion
In this paper, we offered an Android application called DOT-HAZMAT based on Machine Learning and Computer Vision that can locate and categorize HAZMAT placards in perilous rescue operations. In the approach, we were able to accurately identify the presence of HAZMAT signs across a broad range of distances and rotations using the suggested approach, independent of the illumination environment, occlusion, noise, and blurriness in the background. Doing so, we have also publicly released our multivaried dataset via Roboflow. The developed Android application can be downloaded locally on devices and is efficient enough to run detections along with text to help first responders in rescue operations and users in cases of need. As for possible future work, we have highlighted the limitations in the project and suggest an integrated model involving text and object detection simultaneously for improved real-time results.
References
[1] A. Sharifi, A. Zibaei and M.Rezaei, “A deep learning based hazardous materials (HAZMAT) sign detection robot with restricted computational resources”, Machine Learning with Applications (MLWA) Volume 6, 100104. https://doi.org/10.1016/j.mlwa.2021.100104 (2021).
[2] Cai Jianxiong, Hou Jiawe, Lu Yiren, Chen Hongyu, Kneip Laurent and Schwertfeger Sören, “Improving CNN-based Planar Object Detection with Geometric Prior Knowledge.”, IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), https://ieeexplore.ieee.org/document/9292601 (2020)
[3] Z. Wang and H. Guo, “Research on Traffic Sign Detection Based on Convolutional Neural Network”, VINCI 2019: Proceedings of the 12th International Symposium on Visual Information Communication and Interaction, Article No.: 35, Pages 1–5 https://doi.org/10.1145/3356422.3356457 (2019)
[4] Q. Chen, Q. Xu, L. Li and B. Luo, "Optimal bounding box and Grabcut for weakly supervised segmentation," 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), 2019, pp. 1765-1770, doi: https://doi.org/10.1109/EITCE47263.2019.9094973 .
[5] Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. https://doi.org/10.3390/s22020464
[6] G. Jocher, “ultralytics/yolov5: v6.1 - TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference”. Zenodo, Feb. 22, 2022. doi: https://doi.org/10.5281/zenodo.6222936 .
[7] C. Shorten, T. M. Khoshgoftaar, “A survey on Image Data Augmentation for Deep Learning.”, J Big Data 6, 60 (2019). https://doi.org/10.1186/s40537-019-0197-0 (why data augmentation)
[8] Rezaei M., Shahidi M. “Zero-shot learning and its applications from autonomous vehicles to COVID-19 diagnosis: A review Intelligence-Based Medicine, 3–4 (2020), Article 100005, 10.1016/j.ibmed.2020.100005
[9] J. Memon, M. Sami, R. A. Khan and M. Uddin, "Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR)," in IEEE Access, vol. 8, pp. 142642-142668, 2020, doi: https://doi.org/10.1109/ACCESS.2020.3012542 .
About the University Technology Exposure Program 2022
Wevolver, in partnership with Mouser Electronics and Ansys, is excited to announce the launch of the University Technology Exposure Program 2022. The program aims to recognize and reward innovation from engineering students and researchers across the globe. Learn more about the program here.
