How to Overcome Data Leakage in Machine Learning (ML)
The accuracy of predictive modeling depends on the sample data's quality, and a robust model learned from that data. Data leakage may occur when the test and training data are shared in a model, resulting in either poor generalization or over-estimating a machine learning model's performance.

27 Jan, 2021. 4 minutes read

AITS Journal
Data leakage happens when the data an engineer used during training time becomes unavailable at the inference time. It can lead to over-optimistic predicted error rates because the data unavailable during inference time is considered predictive while undergoing the training process. The estimated error rates can misguide data scientists into implementing models that fail to meet acceptable accuracy thresholds. As a result, such models explicitly fail to perform accurate runtime predictions. Thus, engineers should put systems in place to monitor and debug the deployed models. If the models are giving predictions, they may fail to identify any data leakages in machine learning models.
Data Leakage: What Does It Have To Do With Machine Learning?
Data leakage and machine learning are quite inter-linked. When engineers train a machine learning model, they aim for a model that scores high in specific metrics i.e. accuracy. Naturally, if they train a model and it scores well on a test data-set, they finalize the well-performing model.
However, the engineers often encounter situations when the model gives good results while testing, but it doesn't achieve a similar performance level during real-world usage. For example, suppose a model achieves 99% accuracy in testing but fails to get anywhere near after getting productized when it acts on actual data sets. Such disparity in test and real-world performance is linked to data leakage.
Understanding The Key Reasons Behind The Data Leakage?
Checking the machine learning model if it is achieving performance, which seems too good to be true, is the first step to detect data leakage. Some reasons for the same are:
- Use of duplicate data sets: It is common in models to feed data-sets from real-world, noisy data. Data duplication occurs in data-sets containing many points of nearly identical or identical data.
- Data Mismatch: A mismatch between training data and production data can also result in data leakage in machine learning models.
- Temporary data in processing: Although engineers may not explicitly leak information, they will still experience data leakage due to the training and test data sets' dependencies. A typical example is temporal data sets where time is a crucial factor, like the time-series data.
- Preprocessing Steps of ML: Most engineers make the mistake of leaking data during the pre-processing stage of machine learning. They should provide such transformations the knowledge of the training set only and not the testing set.
- Leaky Predictors: Engineers sometimes fail to exclude the updated features after realizing the target value during feature engineering. Thus, they encounter data leakage because when they make new predictions with this model, the data is not available to the model.Image courtesy of Kaggle.

How Can Engineers Minimize Data Leakage When Building Machine Learning Models?
Data leakage tends to occur when the model unintentionally has access to data during model training, which it will not have in the real-world. Understand that there is no one-size-fits-all solution. Engineers should carry out a proactive analysis for the potentially predictive variables and continuously monitor their models' output distributions. They can analyze the ground-truth signal shortly after generating predictions. Thus, to minimize data leakage when building machine learning models, they must take the following steps.
- Avoid over-optimistic evaluations of the models: The engineers must analyze the data generating process and know these pointers:
- What data is getting generated?
- Where is it coming from?
- When is it generated?
- And how is it generated?
Including random fields in the model can prove detrimental as it becomes difficult to detect it until it's too late.
- Split the training data-set into validation and train sets. It will prevent overfitting (or having too optimistic model performance evaluation), and they can avoid deploying underperforming models.
- Temporal cutoff means removing all the data before the event in question. It helps engineers focus on the time of learning for observation rather than the time of occurrence of the observation.
- Adding random noise in the input data can smoothen the effects of leaky variables.
- Remove a variable if they suspect it is leaky.
- Use pipeline architectures heavily, which allow them to perform a series of data preparation steps within the cross-validation folds - for example, scikit-learn pipelines and R caret package.
- Hold an unseen validation data-set, which will act as a final check of the model before finalizing it. As a thumb rule, the engineers can split the training data-set into validation and train sets, and then, they can hold back the validation data-set.
- After completing the modeling process and before finalization, they can evaluate their model on the validation data-set. It will help them determine if they have made overly optimistic assumptions, and there is data leakage in their machine learning model.
- If the validation of the model is based on a train-test split, then it is prudent to exclude validation data from any form of the fitting, which includes fitting the pre-processing steps. For cross-validation, they can ensure that they perform preprocessing inside the pipeline.
- Although it requires huge data engineering infrastructure investments to capture, store and query the data, engineers must train their models on historical data snapshots.
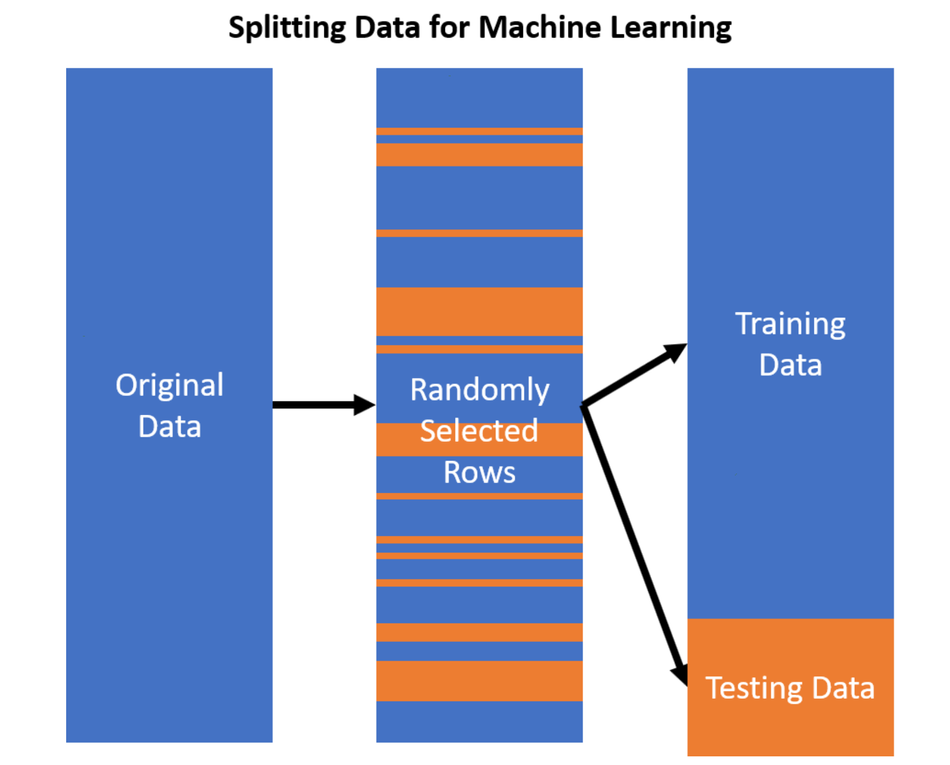
Data leakage is a detrimental issue that can result in lost profits, suboptimal user experiences, and life-threatening situations! If you think the assumption is far-fetched, consider the example of machine learning models deployed in hospitals to predict patient outcomes based on medical conditions. Hence, it becomes imperative for data engineers to prevent data leakage before finalizing their machine learning models.
Sources & Further Reading
Understanding Pipelines, Learn Machine Learning series by Kaggle, https://www.kaggle.com/dansbecker/pipelines
Avoiding Data Leakage in Machine Learning, Stephen Nawara, PhD., https://conlanscientific.com/posts/category/blog/post/avoiding-data-leakage-machine-learning/
Ask a Data Scientist: Data Leakage, Daniel Gutierrez, https://insidebigdata.com/2014/11/26/ask-data-scientist-data-leakage/