Did you check for potential errors in the labeled training dataset?
Attention: Don’t presume human or model-generated labels to be the growth truth for machine learning deployment in autonomous vehicular systems.

14 Feb, 2022. 4 minutes read
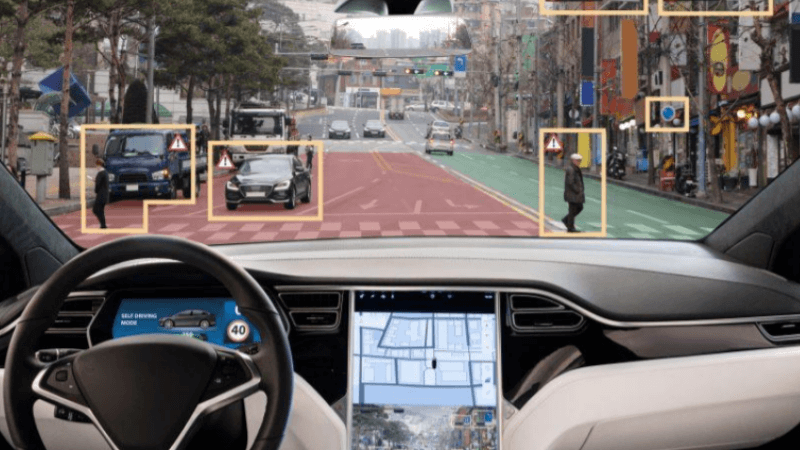
Potential Errors in Training Dataset
An autonomous vehicular system requires efficient machine learning models with minimum error and high accuracy– to reduce the number of accidents caused due to the falsely labeled training data. For machine learning models implemented in edge AI applications, these errors can create significant accuracy drop– defying the whole purpose of mobile computing. There are a lot of uncertainties associated with the labeled dataset that can have impactful consequences.
In today’s scenario, several vendors often provide inaccurately labeled datasets, which require validation before deploying them in mission-critical applications. These errors have created a big loophole in the ML deployment systems that are yet to be discovered by researchers. However, emerging work has shown that one of the most important aspects of the ML deployment pipeline– training data has a significant impact on the results. The recent research proposes model assertions (MAs) [1] indicate when there is an error in the ML model prediction or labels. However, the method has faced several challenges:
For complex ML deployments, it is difficult for the user to manually specify model assertions.
Adjusting the severity score can be challenging at times as higher severity scores indicate a higher chance of error.
The ad-hoc methods used to specify severity scores can ignore organizational resources that are already present– large amounts of labels and existing ML models.
Labeling dataset– not the ground truth
Presuming labeled training data to be the ground truth has caused major problems that can result in impactful consequences. In the research article, “Finding Label and Model Errors in Perception Data with Learned Observation Assertions,” the scientists proposed a probabilistic domain-specific language (DSL), Learned Observation Assertion (LOA) and implemented it in a system– FIXY [2]. Exploiting existing organizational resources including the labeled dataset and previously trained ML models to learn a probabilistic model for finding errors. These errors are determined by likely and unlikely values for a certain parameter in the dataset. For example, a speed of 30mph is possible but 300mph is unlikely.
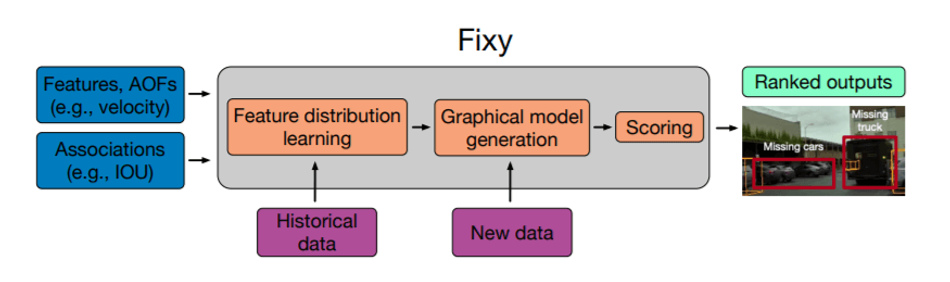
To solve the above-mentioned challenges, the LOA is implemented in a prototype system, FIXY, embedded in Python that can be easily integrated within the machine learning ecosystem. The contribution from this methodology comes in three components: data association, feature distribution and application objective functions. The two-stage FIXY has an offline phase concerned about learning, which data points are likely errors and the online phase to rank new potential errors. The offline phase will learn the feature distribution that is later used in the online phase. By using feature distribution and new data as input, there will be automatic error detection.
“LOA can be used to specify assertions without ad-hoc code or severity scores by automatically transforming the specification into a probabilistic graphical model and scoring data components, producing statistically grounded severity scores,” the team explains in the research article. “Users specify features over data, which are used to automatically generate feature distributions, and application objective functions (AOFs) to guide the search for errors”
Determine potential errors in the real dataset
The proposed system is evaluated on two real-work autonomous vehicular (AV) datasets, one publicly available Lyft Level 5 perception dataset and one internally collected. Both of these datasets were annotated by a commercial labeling vendor. There still exist errors in the labeled dataset even after best efforts from the commercial vendor– all these errors could lead to safety violations.

Surprisingly, in the model run on the Lyft validation dataset, more than 70% of the scenes contained at least one missing object. In the Lyft dataset, the model found errors in 32 of the 46 scenes. LOA found errors in 100% of the scenes in the top 10 ranked errors. “LOA was also able to find errors in every single validation scene that had an error, which shows the utility of using a tool like LOA,” the team writes in the blog post. In the preliminary evaluation of a scene taken from the Toyota Research Institute's internal dataset, FIXY achieved up to 75% of the errors in the given scene (18 out of 24 errors).
This research article is available for public view on Cornell University’s Computer Science database. The developed code is provided by the research team on the Stanford GitHub repository.
References
[1] Daniel Kang, Deepti Raghavan, Peter Bailis, and Matei Zaharia. 2020. Model Assertions for Monitoring and Improving ML Model. MLSys (2020).
[2] Daniel Kang, Nikos Arechiga, Sudeep Pillai, Peter Bailis, Matei Zaharia: Finding Label and Model Errors in Perception Data with Learned Observation Assertions. DOI arXiv.2201.05797 [cs.DB]