How to simplify the inputs for better neural network performance?
Over the last decade, deep neural networks have emerged as the solution to several AI complex applications from speech recognition and object detection to autonomous vehicular systems.

Last updated on 22 Feb, 2022. 4 minutes read

SimpleBits framework for Simplifying of Inputs for Deep Neural Networks
Over the last decade, deep neural networks have emerged as the solution to several AI complex applications from speech recognition and object detection to autonomous vehicular systems. In essence, deep learning isn’t a single algorithm, but a family of algorithms with many layers that lack transparency, making it hard to understand the error, especially a downside for areas where these errors have a high cost. Most of the complexity in these deep neural networks comes from the input dataset which is used to make the training and inference faster and more efficient. Measuring input simplicity has been one of the lines of research that have caught the attention of AI architects to devise a framework that not only improves performance but also focuses on interpretability.
The removal of certain parameters from the input data was an essential part of the research work to understand the correlation of a particular input region or frequency on the output performance. However, most of the existing work depended on random removal or exploiting the domain knowledge that made the inputs simpler on which network performance was analyzed. A team of researchers from the University Medical Center Freiburg and Google Brain [1] proposed a technique for the model to synthesize the inputs that retrain prediction-relevant information. Through this, without relying on prior knowledge, the model can achieve a state of intuition for simplifying the input. Some of the findings reported [2,3] that in density-based anomaly detection, the generative image models usually assign higher probability densities and lower bits for visually simpler inputs.
What does simplification of input mean?
In the paper, “When less is more: Simplifying inputs aids neural network understanding,” the team designed SimpleBits, a framework that synthesizes the inputs to contain less information without affecting the output performance. The approach measures simplicity with the encoding bit size that is given to the pre-trained generative model and reduces the bit size to simplify the inputs. Additionally, the framework can be used to analyze the trade-off between the information content and the task performance. After training neural networks, SimpleBits can act as an analysis tool to understand what information was used by the model to make an optimized informed decision.
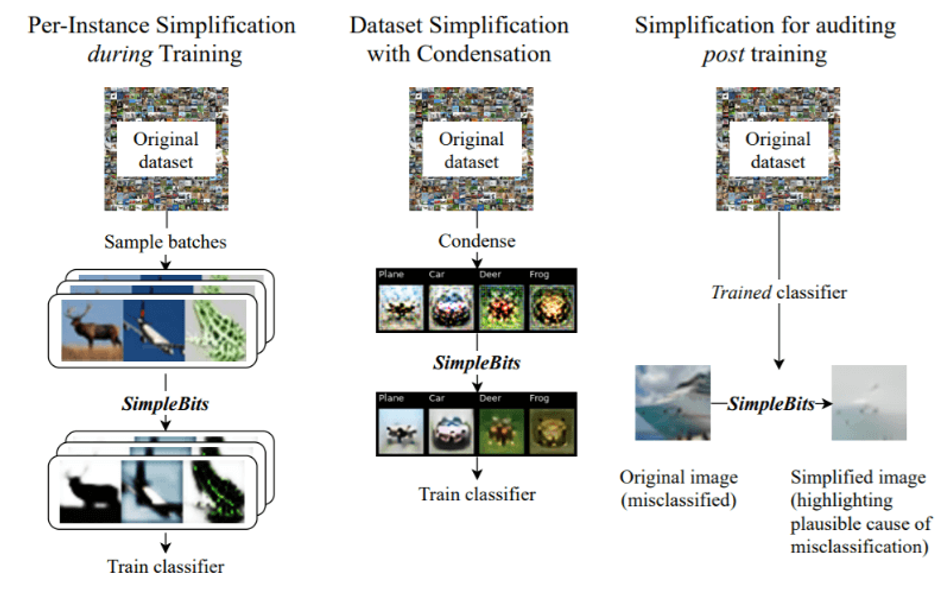
The evaluation of simplification of the inputs was performed in different settings: conventional training, dataset condensation and post-hoc analysis. The image above depicts the tasks covered in the paper, starting with SimpleBits acting as a per-instance simplifier during the training, where each image in the dataset is simplified but the total number of images remains unchanged. In simplifying the input, the framework removes superfluous information for tasks with injected distractors, while on a natural image dataset, the framework highlights task-relevant information. The chosen dataset contained both useful and redundant information for task learning, helping the researchers to evaluate the model accuracy over different datasets. By increasing the simplification process, the researchers noticed an accuracy drop reporting of the trade-off between input simplification and task performance for different setups.
For dataset simplifications with condensation, the dataset is compressed to a few samples per class which are simplified at the same time. In this setting, the training data are converted into a smaller set of synthetic images which are further simplified to reduce the encoding size without affecting the task performance. Finally, for the post-training setting, SimpleBits can act as a post-hoc analysis tool used for auditing processes. “Our exploration of SimpleBits guided audits suggests it can provide intuition into model behavior in individual examples, including finding features that may contribute to misclassifications,” the team notes.
Summary of simplified inputs that aid neural network understanding
An information-based method to simplify the inputs while maintaining the output performance and neural network accuracy. This can be done without any prior knowledge or expertise.
The framework is able to remove injected distractors, retaining accuracy while reducing the complexity of the input dataset images.
It can be used as an analysis tool to monitor the trade-off between task performance and input simplifications to check if any essential information is not removed.
References
[1] Robin Tibor Schirrmeister, Rosanne Liu, Sara Hooker, Tonio Ball: When less is more: Simplifying inputs aids neural network understanding. DOI arXiv.2201.05610 [cs.LG]
[2] Kirichenko, P., Izmailov, P., and Wilson, A. G. Why normalizing flows fail to detect out-of-distribution data. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
[3] Schirrmeister, R., Zhou, Y., Ball, T., and Zhang, D. Understanding anomaly detection with deep invertible networks through hierarchies of distributions and features. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.