HyperTransformer bests rivals at few-shot learning - and takes advantage of unlabeled samples
Developed at Google Research, HyperTransformer decouples the task space and individual task complexity to generate all model weights in just one pass — while also offering support for unlabeled sample ingestion.

09 Feb, 2022. 4 minutes read
Designed for "extreme data scarcity," HyperTransformer's results show performance-boosting promise.
Machine learning holds the potential for rapidly solving problems which would take a trained individual hours, days, weeks, or even years to solve — but, just as with a human operator, it takes training. Techniques for reducing the training required by a machine learning system are, as a result, of considerable interest, and a trio of scientists at Google Research have come up with an approach of their own: HyperTransformer.
Designed around the concept of few-shot learning, whereby machine learning systems can be trained with particularly small data sets - “where,” the researchers note, “entire categories are introduced with just one or few examples” in what they describe as “extreme data scarcity” — HyperTransformer is made to “effectively decouple the complexity of the large task space from the complexity of individual tasks.”
The results, its creators say, are impressive — offering comparable or better results than the current state-of-the-art while generating weights in a single pass, even when HyperTransformer is only used to create the last layer of the model.
Decoupling complexity
The work detailed by Andrey Zhmoginov, Mark Sandler, and Max Vladymyrov in their paper is based on a transformer-based model which generates an entire inference model in a single pass — producing all model weights in one go. In doing so, its creators claim, HyperTransformer can “encode the intricacies of the available training data inside the transformer model.”
In effect, HyperTransformer takes advantage of a high-capacity model to encode task-dependent variations into the weights of a smaller model. The resulting convolutional neural network (CNN) models are compact and specialized enough to solve individual tasks. One impact of the HyperTransformer approach of note is that the computational overhead becomes shifted towards weight generation — meaning that for problem spaces where the task at hand changes only infrequently, it offers a lower overall computational cost than rival approaches.
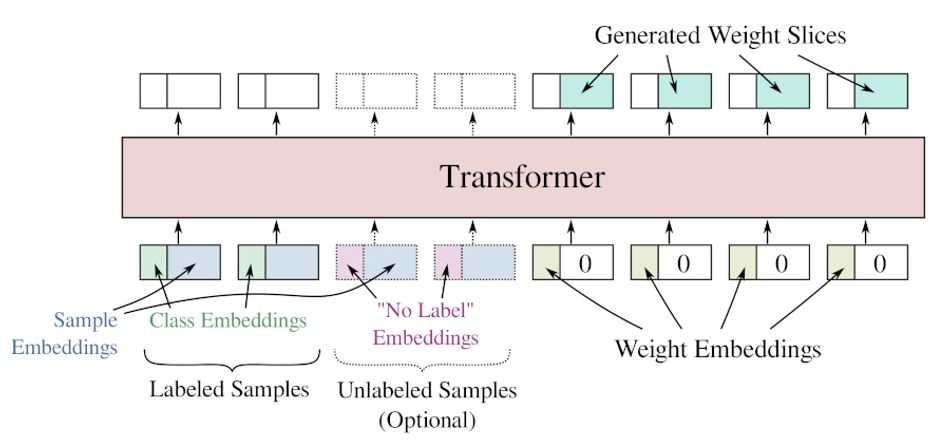
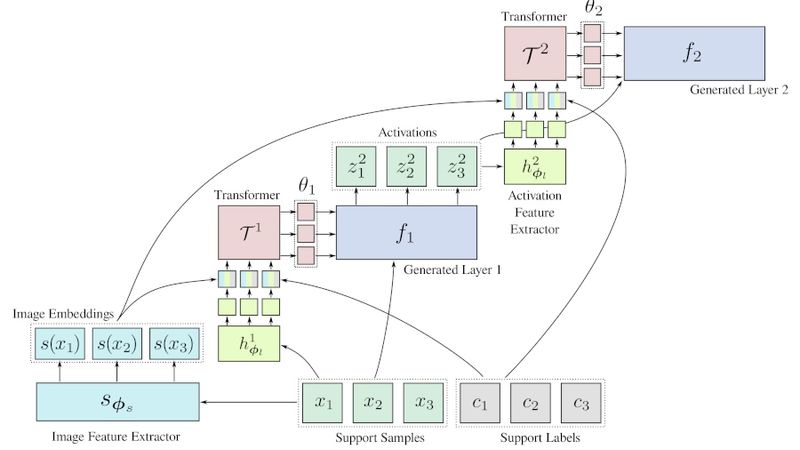
HyperTransformer brings with it other advantages, its creators claim: The addition of what they call a “special input token” extends the approach to support unlabeled samples, allowing the network to take sample images which have not been previously processed as additional training inputs — and considerably boosting the performance of the resulting model at a near-zero cost in human effort.
Interestingly, HyperTransformer appears to be able to deliver its benefits even when only used in part — providing the model is of a large enough size. For small models, the biggest benefits from HyperTransformer are felt when the system is used for generating all weights and adjusting all intermediate layers as well as the final logits layer; above a certain size, though, HyperTransformer delivers its benefits when used only to generate the final logits layer.
The final benefit claimed by the paper’s authors is in its simplicity: Where rival approaches rely on nested gradient optimization and other complex meta-learning techniques, HyperTransformer optimizes in a single transformer parameter update loop.
Boosted performance for reduced complexity
To prove their claims, the team set about benchmarking HyperTransformer against MAML++ (Model-Agnostic Meta-Learning Plus Plus) on the few-shot Omniglot, MiniImageNet, and TieredImageNet datasets.
The results impress: HyperTransformer delivered results which, in the majority, bested MAML++, particularly on smaller models, with the researchers pointing to “parameter disentanglement between the weight generator and the CNN model” as driving the improvement.
Experimentation with generation of the last logits layer did show up one interesting wrinkle: Tests on the five-shot MiniImageNet dataset, which is known to be prone to overfitting, saw training accuracy improve but test accuracy degrade as the transformer model complexity was increased — something they claim could be of practical application in cases where a client model must be adjusted to a particular set of most-widely-used known classes.
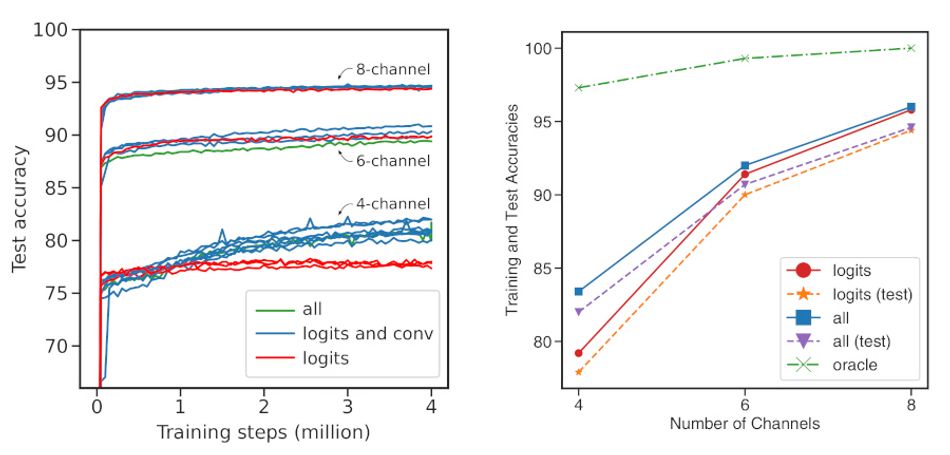
During testing of the suitability for HyperTransformer in creating the intermediate convolutional layers, in addition to the final logits layer, the team noted a “significant performance improvement” providing the CNN model did not exceed eight channels; for networks sized beyond this, performance was identical whether HyperTransformer was used for all layers or merely the final logits layer.
Finally, testing HyperTransformer’s ability to exploit unlabeled samples — extending the dataset available without the need for human or other-network intervention in classifying each sample image — revealed “a substantial increase of the final test accuracy,” the researchers noted, though peak accuracy required at least two self-attention layers in the encoder. It proved important to introduce the unlabeled samples incrementally, however, as simply dumping them all into the support set at the start “makes [HyperTransformer] more difficult to train and it gets stuck producing CNNs with essentially random outputs.”
The researchers have indicated they plan to progress HyperTransformer with future work including support for partially-known sample labels in addition to unlabeled data, generation of larger architectures including ResNet and WideResNet, and an analysis of more complex data augmentations and additional synthetic tasks for performance improvements.
The team’s work is available on Cornell’s arXiv.org preprint server.
Reference
Andrey Zhmoginov, Mark Sandler, Max Vladymyrov: HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning. DOI arXiv:2201.04182 [cs.LG].