NPU vs TPU: Understanding the Key Differences in AI Hardware Accelerators
NPUs are integrated units that excel in real-time AI tasks on edge devices like smartphones and IoT systems with low power consumption. TPUs are standalone processors designed for large-scale AI workloads in data centers, delivering exceptional performance in deep learning tasks.

27 Jan, 2025. 7 minutes read

Specialized hardware accelerators like Neural Processing Units (NPUs) and Tensor Processing Units (TPUs) have revolutionized artificial intelligence (AI) hardware by providing capabilities for accelerating machine learning tasks. Both are designed to optimize performance for tasks like machine learning, deep learning, and neural network computations, but they cater to distinct use cases and requirements.
This article discusses the difference in architectures, performance, practical applications, and challenges of these powerful processing units, offering actionable insights for professionals.
Recommended reading: TPU vs GPU in AI: A Comprehensive Guide to Their Roles and Impact on Artificial Intelligence
Introduction
The rapid advancement of AI has led to an increasing demand for specialized hardware capable of efficiently handling complex computations. NPUs and TPUs have emerged as pivotal technologies in this space, each tailored to optimize tasks involving complex machine learning algorithms in unique ways. NPUs, with their low-power design, enhance edge computing performance, making them indispensable for IoT and mobile devices. TPUs, on the other hand, excel in scaling deep learning workloads across massive datasets, driving breakthroughs in cloud-based AI.
This article aims to provide professionals with a detailed comparison of these technologies, offering practical insights into their architectures, applications, and limitations. Understanding these distinctions can guide informed decision-making and optimize AI deployments for diverse requirements.
What Are Neural Processing Units (NPUs)?
NPUs are specialized processors designed to optimize computations for neural networks, enabling efficient processing in real-time. With their ability to efficiently handle workloads like image recognition, voice processing, and natural language tasks, NPUs are an integral part of modern central processing units (CPUs) and System-on-Chip (SoC) designs. Companies like Huawei, Samsung, and Apple are leading the way in integrating NPUs into their devices to enhance AI capabilities without sacrificing power efficiency.

Recommended reading: NPU vs GPU: Understanding the Key Differences and Use Cases
What Are Tensor Processing Units (TPUs)?
TPUs are hardware AI accelerator application-specific integrated circuits (ASICs) developed by Google to accelerate tensor-based computations, which are foundational to deep learning. Their design is optimized for mathematical operations like matrix-multiplication and parallel computing, making them ideal for tasks such as training large-scale neural networks and performing batch processing.
Here is a block diagram showcasing the architecture of TPUs:
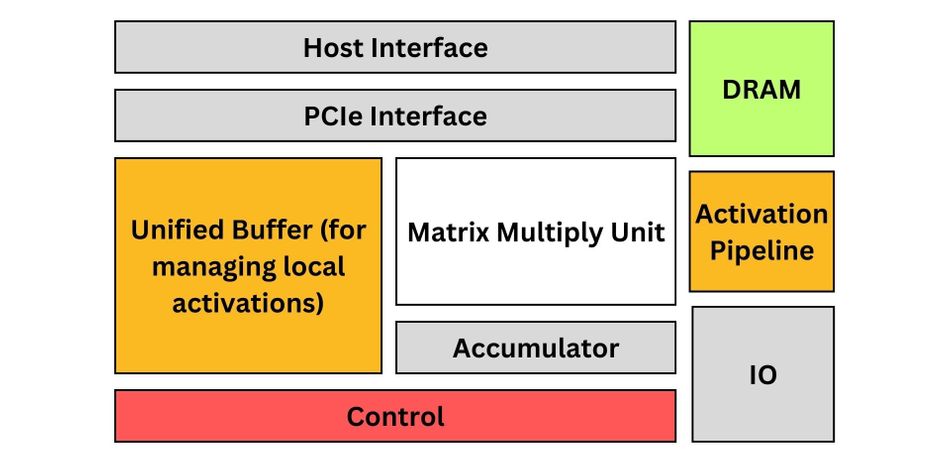
The TPU architecture is designed to optimize AI workloads by integrating specialized components for efficient computation, storage, and communication. At the core is the Matrix Multiply Unit, which performs rapid large-scale matrix operations critical for AI tasks. Data flows through the Unified Buffer, a local storage unit for managing activations, ensuring quick access and reducing dependency on external memory. The Control Unit orchestrates data movement and synchronizes operations between components. The PCIe Interface and Host Interface facilitate communication between the TPU and external systems, enabling smooth data transfer and coordination. The DRAM Ports provide access to external memory for managing large datasets that exceed the buffer's capacity. The Activation Pipeline processes intermediate results, applying transformations essential for refining AI computations. Additionally, the Accumulator stores partial computation results temporarily for aggregation and further processing. Finally, the Miscellaneous I/O manages input/output tasks, ensuring seamless integration with the broader system. This balanced architecture ensures high efficiency and performance for AI tasks in data centers.

Recommended reading: Tensor Cores vs CUDA Cores: The Powerhouses of GPU Computing from Nvidia
Comparing the Performance of NPUs vs TPUs
NPUs and TPUs exhibit distinct performance characteristics, making them suitable for different AI workloads. Following section compares both the AI chips based on different parameters.
Speed and Latency
NPUs are designed for real-time, low-latency tasks, making them ideal for edge computing scenarios where immediate responses are required. For instance, NPUs enable instant image processing in smartphones and IoT devices
TPUs often excel in speed and scalability for large datasets, leveraging their specialized architecture for tensor computations. They are optimized for throughput rather than latency, making them suitable for batch data processing tasks like training massive deep learning models. In contrast, NPUs are designed for real-time, low-latency tasks on the edge.
Power and Energy Efficiency
Power consumption is a critical factor for both NPUs and TPUs, but their optimization differs. NPUs provide better efficiency for edge computing and low-power applications, optimizing computing tasks with limited computational resources. This ensures extended battery life for small devices while performing complex AI tasks. TPUs, while efficient for their scale, are designed for environments like data centers where power availability is less constrained but efficiency remains essential for handling extensive computations.
Scalability and Flexibility
NPUs are less scalable compared to TPUs, as they are tailored for specific edge AI applications. However, their flexibility in real-time processing tasks makes them invaluable for localized AI workloads. TPUs, on the other hand, are built for scalability, capable of handling large-scale AI models and datasets in cloud-based or distributed environments.
Architectural Differences
Core Design
NPUs are engineered to handle neural network activations and real-time matrix computations with specialized cores that focus on efficient, localized processing. These cores typically feature lightweight architectures optimized for low power consumption and latency-sensitive tasks. TPUs, in contrast, utilize systolic array architectures with a high density of computational cores designed for parallel matrix multiplications.
Programming Frameworks and Ecosystem
NPUs are compatible with general-purpose AI frameworks such as TensorFlow, PyTorch, and ONNX, allowing developers to integrate AI tasks into various devices. As they are integrated within larger processors, they are more general-purpose and are compatible with a number of different computing tasks. TPUs, in contrast, are tightly integrated with Google’s TensorFlow ecosystem, making them an ideal choice for developers already working within Google’s AI infrastructure. The trade-off lies in flexibility versus specialization.

Use Cases and Practical Applications
NPUs and TPUs cater to distinct scenarios based on their specialized capabilities.
NPUs find their strengths in edge computing, enabling AI tasks directly on devices like smartphones, cameras, and IoT sensors. Examples of NPU Applications include:
Real-time object detection in edge devices, such as security cameras.
Voice recognition in smart assistants operating on low-power devices.
AI-powered healthcare devices for monitoring patient vitals and diagnosing conditions.
Industrial automation systems requiring real-time decision-making capabilities.
TPUs are the backbone of AI operations on large amounts of data. Examples of TPU Applications include:
Training large-scale machine learning models in cloud environments.
Batch processing for natural language understanding tasks in virtual assistants.
Optimizing recommendation systems in large-scale e-commerce platforms.
Enabling real-time analytics in large datasets for financial and scientific domains.
Challenges and Limitations of NPUs and TPUs
Engineering Challenges in Implementation
Deploying NPUs and TPUs presents several technical challenges, including:
Compatibility Issues: Existing software ecosystems, such as libraries and frameworks, often require extensive adaptation to fully leverage the capabilities of NPUs and TPUs.
Hardware Integration: Ensuring seamless integration with existing system architectures can be complex, particularly in legacy systems.
Optimization Challenges: AI models often need to be specifically optimized to achieve peak performance on these specialized processors.
Cost-Effectiveness: While powerful, the initial investment in NPU or TPU hardware can be prohibitive for smaller organizations.
Limitations in Real-World Applications
Despite their capabilities, NPUs and TPUs face limitations in specific environments:
Latency-Sensitive Systems: TPUs, designed for high-throughput batch processing, may not be ideal for real-time applications that demand low latency.
Hybrid Requirements: Certain applications, such as autonomous vehicles, may require a combination of TPU and graphics processing unit (GPU) capabilities to balance precision and speed effectively.
Scalability Constraints: While TPUs scale well in cloud environments, NPUs are less adaptable to large-scale deployments due to their edge-specific design.
Here is a table summarising the discussion on NPUs and TPUs:
Feature | NPUs | TPUs |
Primary Use Case | Real-time AI tasks on edge devices (e.g., smartphones, laptops, IoT, robotics) | Large-scale AI workloads in data centers (e.g., training deep learning models) |
Key Applications | Image recognition, natural language processing, voice recognition, augmented reality | Language models, natural language processing, large-scale image classification |
Architectural Focus | Low-latency, power-efficient processing for real-time AI tasks | High-performance parallel processing and matrix multiplication for deep learning |
Core Design | Lightweight architectures optimized for low power and real-time processing | Systolic array architectures optimized for massive parallel tensor operations |
Scalability | Limited scalability, designed for specific edge AI tasks | High scalability for training large datasets and deploying AI models |
Power Consumption | Optimized for energy efficiency in portable devices | Designed for efficiency in data centers with less strict power constraints |
Programming Ecosystem | Supports general-purpose AI frameworks (e.g., TensorFlow, PyTorch, ONNX) | Tightly integrated with TensorFlow and Google Cloud services |
Manufacturers | Companies like Apple (Neural Engine), Huawei, Samsung, and others | |
Integration | Embedded in SoC designs for smartphones and IoT devices | Used as standalone accelerators in server environments |
Key Strengths | Real-time processing, low latency, energy efficiency | Exceptional performance for large-scale AI training and inference |
Key Limitations | Less suited for large-scale AI workloads | Higher power requirements, less suited for edge applications |
Conclusion
NPUs and TPUs play complementary roles in the advancement of AI technology, each excelling in specific environments. While TPUs offer unparalleled performance for large-scale machine learning tasks in cloud environments, NPUs are perfect for real-time inference and energy-efficient edge applications.
Frequently Asked Questions
- What Is the Primary Difference Between NPUs and TPUs?
NPUs are specialized for low-power, real-time tasks, making them ideal for edge devices.
TPUs are optimized for large-scale tensor computations, excelling in cloud-based machine learning. - What Are the Key Roles of NPUs and TPUs in AI?
NPUs focus on real-time, low-power AI processing in edge devices like smartphones and IoT systems, enabling efficient inference for tasks such as image recognition and voice commands. TPUs specialize in high-performance, large-scale tensor computations, excelling in data centers for AI training and deployment. - How Do NPUs and TPUs Compare to GPUs?
NPUs are specialized for efficient AI/ML tasks, particularly inference, and are optimized for low-power edge devices like smartphones. TPUs excel in tensor-based operations for deep learning, offering high-speed training and inference, primarily in Google's ecosystem. GPUs, versatile in design, handle a wide range of workloads, including graphics rendering, ML training, and scientific computing, making them ideal for parallel processing. While GPUs are general-purpose, NPUs and TPUs focus on AI-centric optimizations.
Recommended reading: Understanding Nvidia CUDA Cores: A Comprehensive Guide
References
[1] Google. Cloud TPU documentation. Available from: https://cloud.google.com/tpu/docs
[2] Apple. Deploying Transformers on the Apple Neural Engine. Available from: https://machinelearning.apple.com/research/neural-engine-transformers
[3] Van Belle JL. Why neural processing units (NPUs) are the next Big Thing in AI. 2024. doi:10.13140/RG.2.2.35619.87845. Available from: https://www.researchgate.net/publication/383184868_Why_neural_processing_units_NPUs_are_the_next_Big_Thing_in_AI
[4] Sanmartín D, Prohaska V. Exploring TPUs for AI Applications. IE Robotics & AI Club, IE University, Madrid, Spain. arXiv preprint arXiv:2309.08918. Available from: https://arxiv.org/pdf/2309.08918.
in this article
1. Introduction2. What Are Neural Processing Units (NPUs)?3. What Are Tensor Processing Units (TPUs)?4. Comparing the Performance of NPUs vs TPUs5. Architectural Differences6. Use Cases and Practical Applications7. Challenges and Limitations of NPUs and TPUs8. Conclusion9. Frequently Asked Questions10. References