RAG vs Fine-Tuning: Differences, Benefits, and Use Cases Explained
Fine-tuning large language models adapts pre-trained models to specific tasks or domains using tailored datasets, while Retrieval-Augmented Generation (RAG) combines retrieval systems with generative models to dynamically incorporate external, up-to-date knowledge into outputs.

02 Dec, 2024. 18 min read

Introduction
As gen AI and natural language processing (NLP) continue to evolve, the demand for more capable and efficient models has grown exponentially. From chatbots and virtual assistants to sophisticated content generation and search systems, NLP applications are becoming increasingly integral to modern technology. However, with this growing demand comes the challenge of improving the performance and adaptability of these systems, especially in complex and dynamic environments.
Two prominent approaches to enhancing NLP models are Retrieval-Augmented Generation (RAG) and fine tuning. While fine tuning has long been a staple in the machine learning world, allowing models to adapt to specific tasks by learning from additional data, RAG introduces an innovative paradigm. By combining the strengths of retrieval systems with generation models, RAG creates a dynamic mechanism for handling tasks that require large-scale information access and context sensitivity.AI engineers often face a challenging decision when choosing between RAG and fine-tuning for their projects. Each approach offers unique advantages and trade-offs, necessitating a thorough understanding of their respective strengths, limitations, and optimal use cases. This comprehensive article aims to equip readers with the knowledge needed to make informed decisions and leverage these powerful techniques effectively in their work.
Recommended reading: Artificial Intelligence: A Comprehensive Guide to its Engineering Principles and Applications
Background on NLP Techniques
The journey of NLP has been shaped by a series of innovations aimed at enabling machines to understand and generate human language with precision and nuance. Early approaches, such as rule-based systems and statistical models, relied on handcrafted features and domain-specific rules. However, these methods often struggled with scalability and generalization.
The advent of deep learning marked a turning point in NLP, introducing neural network architectures capable of capturing complex patterns in large datasets. Models like word2vec and GloVe pioneered embedding models to represent words in dense vector spaces, enabling better contextual understanding. The introduction of transformer-based large language models (LLMs), such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformer (GPT) by OpenAI, revolutionized the field by enabling contextual understanding of text through self-attention mechanisms.
Despite these advancements, challenges remained. Models trained on large corpora often performed well on generic tasks but lacked adaptability for domain-specific applications or evolving datasets. This gap led to the development of techniques like fine tuning, where pre-trained models are refined using additional, task-specific data. Fine tuning proved highly effective but often required significant computational resources and time.
More recently, RAG emerged as a complementary approach. By integrating retrieval systems with generative models, RAG bypasses the need for extensive retraining, enabling models to access external knowledge bases dynamically. This innovation provides a compelling alternative to traditional fine tuning for tasks requiring real-time access to up-to-date or domain-specific knowledge and information.
Recommended reading: Edge AI Technology Report: Generative AI Edition
Decoding the Foundations: RAG and Fine-Tuning Unveiled
Retrieval-Augmented Generation (RAG) Explained
RAG is an innovative approach in NLP that combines the power of information retrieval with language generation. At its core, RAG enhances the capabilities of large language models by enabling them to access and utilize external knowledge dynamically during the generation process.
The RAG architecture consists of two primary components: the retriever and the generator. The retriever is responsible for searching and extracting relevant information from a large corpus of documents or a knowledge base. This component typically employs advanced information retrieval techniques, such as dense vector representations and efficient similarity search algorithms, to identify the most pertinent pieces of information for a given query or context.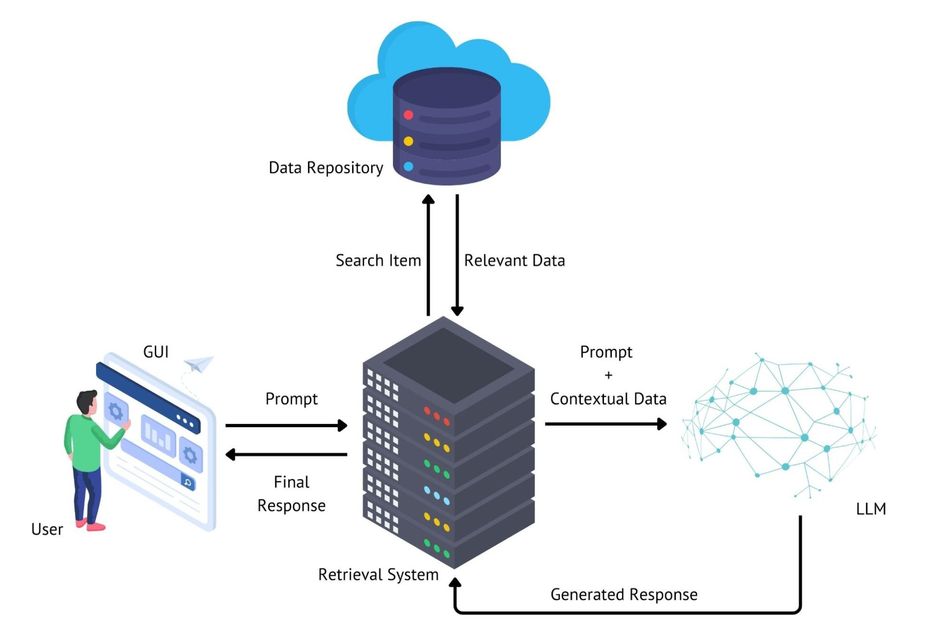
The generator, on the other hand, is a language model that takes the retrieved information and the original input to produce coherent and contextually appropriate and accurate responses. This component leverages the power of pre-trained language models, such as GPT or BART, to generate human-like text while incorporating the external knowledge provided by the retriever.
RAG integrates external knowledge into language models by conditioning the generation process on the retrieved information. This approach allows the model to access up-to-date and task-specific information that may not have been present in its initial training data. As a result, RAG-enhanced models can provide more accurate, updated, informed, and contextually relevant responses across a wide range of tasks and domains.
Key components of a RAG system include:
Knowledge Base: This could be a large corpus of documents, structured data containing the external information, or the complete internet.
Retriever: The module responsible for searching and extracting relevant information from the knowledge base.
Encoder: A component that converts input queries and documents into dense vector representations.
Similarity Search: An algorithm that identifies the most relevant documents based on vector similarity.
Generator: The language model that produces the final output using the retrieved information and input context.
Fusion Mechanism: A method for combining the retrieved information with the input to guide the generation process.
Fine-Tuning Demystified
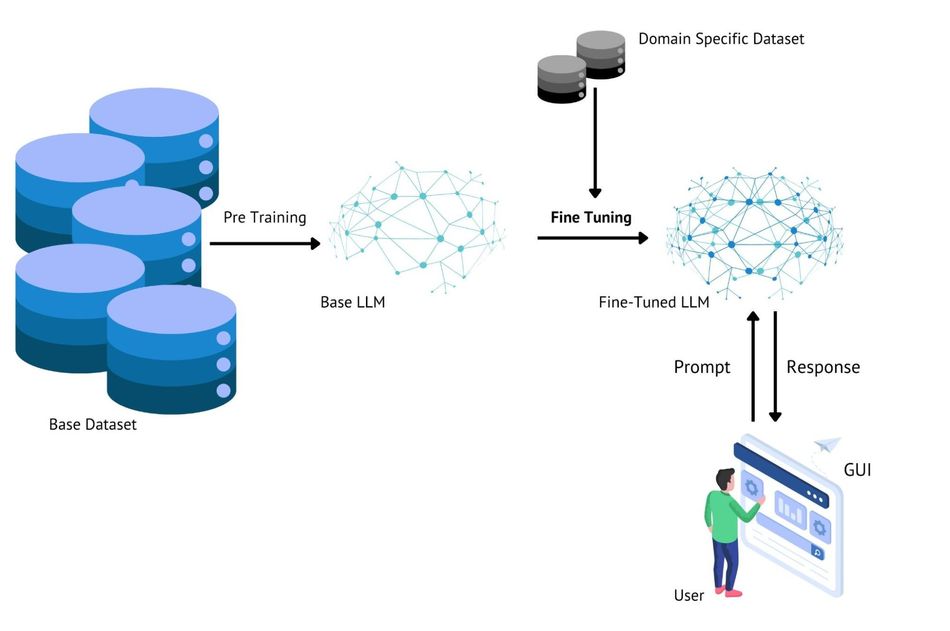
Fine-tuning is a powerful technique in NLP that involves adapting and further training a pre-trained language model to perform specific tasks or operate in specialized domains. This process leverages the knowledge and capabilities of large, general-purpose models and tailors them to meet particular requirements, resulting in improved performance on targeted applications.
At its core, fine-tuning builds upon the concept of transfer learning, which allows models to apply knowledge gained from one task to another related task. In the context of language models, this means that the general language understanding and generation capabilities acquired during pre-training can be refined and specialized for specific use cases. This approach significantly reduces the amount of task-specific training data required and accelerates the development of high-performance models for various applications.
Recommended Reading: LLM Training: Mastering the Art of Language Model Development
The fine-tuning process involves exposing the pre-trained model to a carefully curated dataset representative of the target task or domain. During this phase, the model's parameters are adjusted to optimize performance on the new task while retaining the foundational knowledge acquired during pre-training. This delicate balance allows the model to leverage its broad understanding of language while developing specialized capabilities for the intended application.
Steps involved in fine-tuning a model:
Select an appropriate pre-trained model as the starting point
Prepare a high-quality, task-specific dataset for fine-tuning
Define the task-specific architecture (e.g., adding classification layers)
Configure hyperparameters for the fine-tuning process
Train the model on the new dataset, updating model parameters
Evaluate the fine-tuned model's performance on a held-out test set
Iterate and refine the process as needed to achieve desired results
Fine-tuning enables developers to create specialized models for a wide range of applications, such as sentiment analysis, named entity recognition, and question-answering systems, without the need for extensive computational resources or massive datasets. This approach has democratized access to state-of-the-art language models and accelerated the development of AI-powered solutions across various industries.
RAG vs Fine-Tuning Face-Off: Performance Meterics
Accuracy and Precision
When evaluating the performance of RAG and fine-tuning approaches, accuracy and precision are crucial metrics that vary significantly depending on the task at hand. RAG excels in scenarios requiring up-to-date or specialized knowledge, while fine-tuning shines in tasks with well-defined patterns and consistent data distributions.Several factors influence the accuracy of each approach. For RAG, the quality and relevance of the external knowledge base play a crucial role. The effectiveness of the retrieval mechanism and the ability to integrate retrieved information with the generation process also significantly impact accuracy. Additionally, the diversity and coverage of the knowledge base affect RAG's performance across different domains.
In the case of fine-tuning, the quality and quantity of task-specific training data are of great importance. The similarity between the pre-training domain and the target task domain also influences accuracy. The choice of hyperparameters, such as learning rate and number of training epochs, can significantly affect the fine-tuned model's performance.
RAG typically outperforms fine-tuning in scenarios requiring access to extensive, up-to-date information. For example, in open-domain question answering tasks, RAG can leverage its vast knowledge base to provide more accurate answers, especially for questions about recent events or specialized topics not covered in the original training data.
Conversely, fine-tuning often excels in tasks with well-defined patterns and consistent data distributions. In named entity recognition or sentiment analysis, where the task structure remains relatively stable across different texts, fine-tuned models can achieve higher accuracy by specializing in the specific patterns and nuances of the task.
Fact-checking is another area where RAG demonstrates superior accuracy. By accessing and cross-referencing information from multiple sources in its knowledge base, RAG can provide more reliable fact verification compared to fine-tuned models, which are limited to the information encoded in their parameters during training.
However, fine-tuning can outperform RAG in tasks that require deep understanding of specific domain jargon or highly specialized language patterns. For instance, in legal document analysis or medical report generation, a fine-tuned model trained on domain-specific data may achieve higher accuracy than a RAG system, especially if the external knowledge base lacks comprehensive coverage of the specialized domain.
Adaptability and Generalization
Adaptability and generalization are crucial aspects of AI models, determining their ability to perform well on new, unseen data and tasks. RAG and fine-tuned models exhibit different characteristics in these areas, each with its own strengths and limitations.
RAG models demonstrate superior adaptability to new information and scenarios. By leveraging an external knowledge base, RAG can incorporate up-to-date information without requiring retraining. This allows RAG models to stay current and relevant in dynamic environments where information changes rapidly.
Fine-tuned models, while highly specialized for specific tasks, often struggle with adaptability. They are prone to a phenomenon known as catastrophic forgetting, where the model loses previously learned information as it adapts to new tasks or data. This occurs because fine-tuning adjusts the model's parameters to optimize performance on the new task, potentially overwriting knowledge relevant to previous tasks.
RAG addresses the issue of catastrophic forgetting by maintaining a separate, updateable knowledge base. Instead of modifying the model's internal parameters, RAG retrieves relevant information from this external source, allowing it to adapt to new data without compromising its performance on previously learned tasks.
Generalization is important in tasks such as:
Open-domain question answering: RAG excels here by accessing a broad knowledge base, allowing it to answer questions on diverse topics, even those not encountered during training.
Zero-shot learning: RAG can perform reasonably well on tasks it hasn't been explicitly trained for by leveraging relevant information from its knowledge base.
Cross-lingual tasks: Fine-tuned models may struggle when encountering languages or dialects not present in their training data, while RAG can potentially retrieve and utilize multilingual information.
Temporal reasoning: RAG can incorporate the latest information, making it better suited for tasks involving current events or evolving knowledge.
Key differences in adaptability between RAG and fine-tuning:
Knowledge Integration: RAG dynamically integrates new information, while fine-tuned models require retraining.
Catastrophic Forgetting: RAG largely avoids this issue, whereas fine-tuned models are susceptible to it.
Task Flexibility: RAG can adapt to a wider range of tasks without retraining, while fine-tuned models are more task-specific.
Continuous Learning: RAG supports continuous learning through knowledge base updates, fine-tuned models typically have fixed knowledge after training.
Generalization to Unseen Data: RAG often performs better on entirely new scenarios due to its broad general knowledge access.
Recommended reading: Generative AI vs Predictive AI: Unveiling the Titans of Artificial Intelligence
Resource Requirements and Computational Demands
The computational requirements for RAG and fine-tuning models vary significantly, impacting their deployment and scalability in real-world applications. RAG models generally demand more computational resources due to their need to maintain and query large external knowledge bases in real-time.
For GPU/TPU usage, fine-tuning typically requires intensive resources during the training phase but can be more efficient during inference. RAG models, while less demanding during initial setup, require consistent GPU/TPU power for real-time retrieval and integration of information during inference.
Memory requirements also differ substantially. Fine-tuned models store all information within their parameters, leading to larger model sizes but potentially faster inference times. RAG models have smaller core models but require additional memory to store and access their external knowledge bases.
Scalability presents unique challenges for each approach. Fine-tuned models scale well for specific tasks but may require retraining or separate models for different domains. RAG systems offer better scalability across diverse tasks due to their modular nature, allowing for updates to the knowledge base without altering the core model.
Model Size | Task | RAG Computational Cost | Fine-Tuning Computational Cost |
Small | Question Answering | Medium | Low |
Medium | Named Entity Recognition | High | Medium |
Large | Summarization | Very High | High |
To optimize resource usage for RAG systems:
Implement efficient indexing and retrieval algorithms.
Use caching mechanisms for frequently accessed information.
Employ distributed computing for large-scale knowledge bases.
For fine-tuning optimization:
Utilize parameter-efficient fine-tuning techniques like adapter layers.
Implement quantization and pruning to reduce model size.
Leverage transfer learning to minimize training time on new tasks.
Both approaches benefit from hardware acceleration and optimized inference engines. The choice between RAG and fine-tuning often involves balancing the trade-offs between computational demands, task flexibility, and performance requirements specific to each application scenario.
Inference Speed and Latency
RAG models, while flexible and capable of accessing dynamic, real-time information, are inherently slow. The high latency in RAG models is primarily due to the retrieval process. Before generating a response, RAG must search its knowledge base, retrieve relevant information, and integrate it with the user’s query. While this additional step enhances the model's access to up-to-date information, it introduces a significant time overhead.
Computational requirements during inference also differ between the two approaches. Fine-tuned models, having incorporated task-specific knowledge into their parameters, typically require less computational power during inference. They operate solely on the input, leveraging their pre-trained and fine-tuned weights. In contrast, RAG models need to maintain and query a large external knowledge base, which can be computationally intensive and may require additional hardware resources.
The choice between RAG and fine-tuning for deployment scenarios depends on the specific requirements of the application. Time-sensitive tasks such as real-time chatbots or automated trading systems might benefit from the lower latency of fine-tuned models. However, applications where up-to-date information is crucial, such as news summarization or dynamic fact-checking, may find the additional latency of RAG acceptable given its ability to access and incorporate current information.
Implementation Strategies: Bringing RAG and Fine-Tuning to Life
RAG Implementation Blueprint
Implementing a RAG system involves several key steps, each crucial for creating an effective and efficient model. The process begins with data preparation, where a diverse and high-quality corpus is collected and preprocessed. This data forms the foundation of the knowledge base that the RAG system will query during operation.
Next, the retriever component is trained. This typically involves retriever components in RAG utilizing embedding models to encode queries and documents into dense vector representations for similarity searches. Popular approaches include using transformer-based models like BERT or DPR (Dense Passage Retriever) to encode documents and queries into a shared vector space.
The integration of the retriever with the generator is a critical step. This involves designing a pipeline that can efficiently retrieve relevant information based on an input query and seamlessly incorporate this information into the generation process. The generator, often a pre-trained language model like GPT, is then fine-tuned to effectively utilize the retrieved information.
Popular frameworks and tools for RAG implementation include:
Haystack: An end-to-end framework for building RAG systems, offering components for document stores, retrievers, and readers.
Langchain: A library that simplifies the process of combining LLMs with external data sources and other computation.
Hugging Face Transformers: Provides pre-trained models and tools for both retrieval and generation tasks.
Here's a simplified pseudocode for a basic RAG system:
def rag_system(query, knowledge_base): # Retrieve relevant documents relevant_docs = retriever.get_relevant_documents(query, knowledge_base) # Prepare context by concatenating retrieved documents context = " ".join(relevant_docs) # Generate response using the query and context response = generator.generate(query + context) return response # Usage query = "What is the capital of France?" response = rag_system(query, knowledge_base) print(response)
Best practices for RAG implementation:
Ensure a diverse and high-quality knowledge base to cover a wide range of topics.
Regularly update the knowledge base to maintain accuracy and relevance.
Implement efficient indexing and retrieval mechanisms to minimize latency.
Fine-tune the generator on task-specific data to improve coherence and relevance of outputs.
Implement a robust evaluation pipeline to assess the quality of retrieved information and generated responses.
Consider implementing a re-ranking step after initial retrieval to improve relevance.
Experiment with different retrieval and generation models to find the optimal combination for your specific use case.
Fine-Tuning Implementation Blueprint
Implementing fine-tuning for a pre-trained language model involves a systematic approach that ensures the model adapts effectively to the desired task or domain. The process begins with data preparation, where a high-quality, domain-specific dataset is collected, cleaned, and annotated as needed. This dataset serves as the foundation for training the model to specialize in the specific task.
Next, the model selection phase involves choosing an appropriate pre-trained model, such as BERT, GPT, or T5, that aligns with the task requirements. The model architecture may need slight modifications, such as adding task-specific layers, depending on the application (e.g., classification, summarization, or question answering).
Once the dataset and model are prepared, the fine-tuning process begins. The model is trained on the task-specific dataset using suitable hyperparameters, loss functions, and optimizers. Regular evaluations on a validation set ensure that the model is learning effectively and helps avoid overfitting.
Popular frameworks and tools for fine-tuning include:
Hugging Face Transformers: Offers pre-trained models, tokenizers, and fine-tuning utilities for a variety of NLP tasks.
PyTorch and TensorFlow: Widely used machine learning frameworks that provide flexibility for implementing and fine-tuning custom models.
Google Colab and Kaggle: Cloud-based platforms with free GPUs for fine-tuning smaller models.
Here’s a simplified pseudocode for fine-tuning a model for sentiment analysis:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments # Load pre-trained model and tokenizer model_name = "bert-base-uncased" model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2) tokenizer = AutoTokenizer.from_pretrained(model_name) # Prepare dataset def preprocess_function(examples): return tokenizer(examples["text"], truncation=True, padding=True) tokenized_datasets = raw_datasets.map(preprocess_function, batched=True) # Training arguments training_args = TrainingArguments( output_dir="./results", evaluation_strategy="epoch", save_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3, weight_decay=0.01, ) # Define Trainer trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"], ) # Train model trainer.train()
Best Practices for Fine-Tuning Implementation
Task-Specific Dataset Quality: Ensure the dataset is clean, annotated accurately, and representative of the desired domain or task.
Hyperparameter Tuning: Experiment with learning rates, batch sizes, and training epochs to optimize performance.
Avoid Overfitting: Use techniques like dropout, early stopping, or regularization to improve generalization.
Evaluate Regularly: Monitor performance on a validation set during training to ensure the model is learning effectively.
Leverage Pre-Trained Layers: Use the frozen base model and fine-tune task-specific layers for resource efficiency.
Efficient Resource Usage: Utilize cloud-based resources like GPUs or TPUs and batch training for faster fine-tuning.
Continuous Updating: Periodically retrain the model with new data to maintain relevance and accuracy.
By following this blueprint, you can successfully implement fine-tuning for a wide range of NLP tasks, ensuring high task-specific performance with efficient resource usage.
Choosing the Right AI Model Enhancement Technique for the Job
When RAG Shines
RAG demonstrates superior performance in scenarios that require access to vast, up-to-date information and the ability to adapt to new data without retraining. This makes RAG effective in domains where knowledge is constantly evolving or where the scope of information is too broad to be effectively captured in a single model's parameters.
One prime example of RAG's effectiveness is in open-domain question answering systems. Unlike fine-tuned models that are limited to the knowledge embedded in their parameters, RAG can dynamically retrieve and incorporate the latest information from its knowledge base. This capability is crucial for applications like virtual assistants or customer support chatbots that need to provide accurate, up-to-date responses across a wide range of topics.
Another area where RAG excels is in content generation tasks that require factual accuracy and diversity. For instance, in automated news summarization or report generation, RAG can pull in the most recent data and statistics, ensuring that the generated content is both current and factually correct. This dynamic knowledge integration is valuable in fields like finance, where market conditions and company information change rapidly.
RAG's ability to handle frequently updated information is a significant advantage in many real-world applications. In the medical field, for example, RAG-based systems can stay current with the latest research findings, treatment protocols, and drug information without the need for constant model retraining. This ensures that healthcare professionals have access to the most recent and relevant information when making critical decisions.
Key use cases for RAG include:
Open-domain question answering and chatbots
Real-time news summarization and analysis
Scientific literature review and research assistance
Financial market analysis and reporting
Educational tools and interactive learning platforms
Fact-checking and misinformation detection systems
In these scenarios, RAG's ability to combine the generalization capabilities of large language models with the precision and timeliness of information retrieval systems makes it a powerful tool for handling complex, knowledge-intensive tasks that require both breadth and depth of information.
Where Fine Tuning Shines
Fine tuning works in scenarios where task-specific optimization and low-latency performance are critical. One key area where fine tuning shines is in domain-specific natural language processing tasks. For instance, in legal, medical, or technical document analysis, fine-tuned models can outperform generic models by leveraging their specialized training to understand jargon, context, and nuances.
Task-specific performance optimization is another strength of fine tuning. In applications such as sentiment analysis, spam detection, or named entity recognition, fine-tuned models deliver exceptional performance by focusing on task-specific datasets. This targeted training ensures that the models are not only accurate but also robust in handling domain-specific subtleties.
Fine tuning also excels in low-latency environments, where response time is critical. Since fine-tuned models do not depend on external retrieval mechanisms, they can generate outputs more quickly than retrieval-augmented systems like RAG. This makes fine-tuning ideal for real-time applications such as chatbots, voice assistants, and live translation systems, where speed is as important as accuracy.
In environments where data privacy is paramount, such as healthcare or finance, fine-tuned models offer an additional advantage. By embedding task-specific knowledge directly into the model, fine-tuning minimizes the need for external data retrieval, reducing the risk of data leakage or privacy breaches.
Key use cases for fine tuning include:
Sentiment analysis in social media or customer feedback
Legal and medical document analysis
Personalized recommendations and user profiling
Fraud detection and risk assessment in financial systems
Low-latency customer service chatbots
Task-specific summarization and report generation
Domain-specific translation and language models
Technical support and troubleshooting assistants
In these scenarios, fine tuning's ability to specialize in specific tasks and its efficiency in delivering quick responses make it an invaluable approach. Its reliance on stable datasets and embedded knowledge ensures that fine-tuned models remain highly effective in predictable, task-focused applications.Hybrid Approaches: Best of Both Worlds
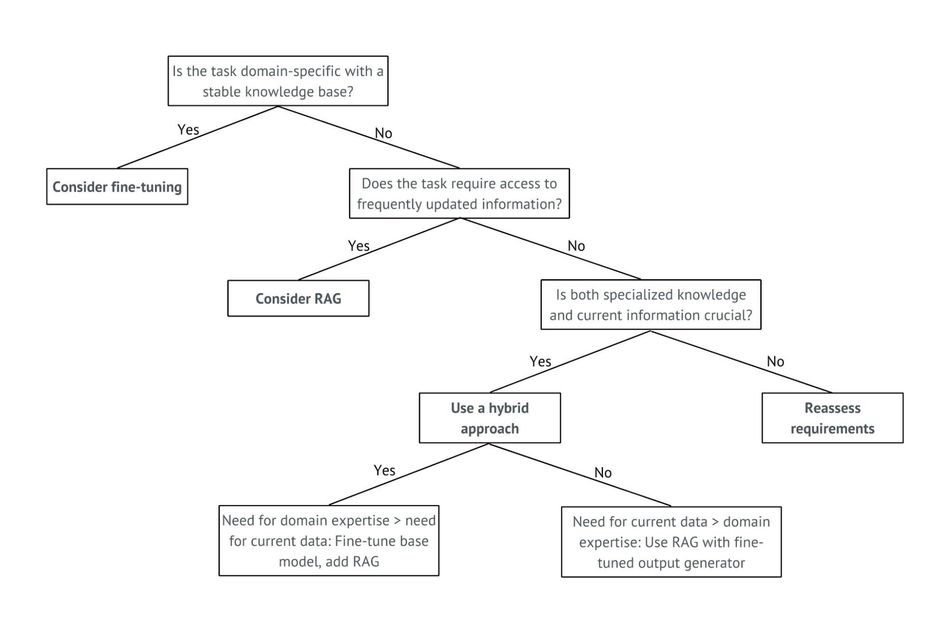
Hybrid approaches combining RAG and fine-tuning offer a powerful solution for scenarios requiring both up-to-date information retrieval and task-specific optimization. These approaches leverage the strengths of both methods to create more versatile and efficient AI systems.
One effective strategy for integrating RAG and fine-tuning is to use a fine-tuned model as the base for a RAG system. This allows the model to have specialized knowledge for a particular domain while still being able to access and incorporate external information. For instance, in a medical diagnosis system, the base model could be fine-tuned on medical terminology and common diagnostic procedures, while RAG capabilities allow it to retrieve the latest research findings or rare case studies.
Another approach is to use RAG for initial information retrieval and then fine-tune the output generation process. This can be useful in content creation tasks where factual accuracy and stylistic consistency are both important. For example, a news summarization system could use RAG to gather relevant facts and then employ a fine-tuned language model to generate summaries in a specific journalistic style.
Real-world applications of hybrid approaches include:
Legal research tools that combine fine-tuned models for legal language understanding with RAG for accessing up-to-date case law and statutes.
Educational platforms that use fine-tuning for personalized instruction and RAG for retrieving diverse, current learning materials.
Financial analysis systems that employ fine-tuned models for market trend prediction and RAG for incorporating real-time economic data.
This decision tree guides practitioners in selecting the most appropriate approach based on their specific use case, balancing the need for specialized knowledge with the requirement for up-to-date information.
Recommended reading: 2024 State of Edge AI Report
Conclusion
RAG and fine-tuning represent two distinct approaches to enhancing AI model performance, each with its own strengths and limitations. RAG excels in scenarios requiring access to large, frequently updated knowledge bases, offering flexibility and adaptability to new information without retraining. Fine-tuning, on the other hand, shines in task-specific applications where deep specialization is crucial, providing faster inference times and more compact models.
When choosing between RAG and fine-tuning, consider factors such as the nature of the task, the frequency of data updates, computational resources, and the need for explainability. RAG is particularly suitable for open-domain tasks and applications requiring up-to-date information, while fine-tuning is ideal for specialized, well-defined tasks with stable knowledge requirements.
Aligning the chosen method with specific project requirements and constraints is critical. Consider the trade-offs between inference speed, model size, adaptability, and the need for external knowledge bases. In some cases, a hybrid approach combining elements of both RAG and fine-tuning may offer the best solution.
Practitioners are encouraged to experiment with both approaches to gain hands-on experience.
Frequently Asked Questions
- How do RAG and fine-tuning compare in terms of inference speed?
Fine-tuned models generally offer faster inference speeds compared to RAG models. The graph shows that across all model sizes (small, medium, large), fine-tuned models consistently have lower inference times. - What are the main challenges in implementing RAG systems?
Key challenges include building and maintaining a large, up-to-date knowledge base, implementing efficient retrieval mechanisms, and balancing the trade-off between retrieval accuracy and speed. Additionally, ensuring the relevance of retrieved information and its seamless integration with the generation process can be complex. - How can I determine if fine-tuning is sufficient for my task, or if I should consider RAG?
Consider fine-tuning if your task is well-defined, has a stable knowledge domain, and doesn't require frequent updates. Opt for RAG if your application needs access to a broad, frequently updated knowledge base, or if you need to handle queries outside the scope of the original training data. - Can RAG and fine-tuning be combined effectively?
Yes, hybrid approaches can be very effective. For example, you can use a fine-tuned model as the base for a RAG system, combining specialized knowledge with the ability to retrieve external information. Alternatively, you can use RAG for initial information retrieval and then fine-tune the output generation process for specific tasks or styles. - How do RAG and fine-tuning compare in terms of model interpretability and explainability?
RAG often offers better interpretability as it can provide the sources of retrieved information, making it easier to trace the model's decision-making process. Fine-tuned models, while potentially more accurate for specific tasks, may be less transparent in their reasoning process. - What future developments or trends are emerging in model enhancement techniques beyond RAG and fine-tuning?
Emerging trends include: continual learning techniques that allow models to update their knowledge without full retraining, more efficient parameter-efficient fine-tuning methods, improved retrieval mechanisms using advanced neural architectures, and the development of models that can dynamically decide when to use internal knowledge versus external retrieval.
References
[1] Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. 2020. Available from: https://arxiv.org/abs/2005.11401
[2] Devlin J, Chang MW, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. p. 4171–86. Available from: https://arxiv.org/abs/1810.04805
[3] Lv K, et al. Full Parameter Fine-tuning for Large Language Models with Limited Resources. 2024. Available from: https://arxiv.org/abs/2306.09782
[4] Siriwardhana S, Weerasekera R, Wen E, Kaluarachchi T, Rana R, Nanayakkara S. Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering. Trans Assoc Comput Linguist. 2023;11:1–17. doi: 10.1162/tacl_a_00530. Available from: https://doi.org/10.1162/tacl_a_00530
Table of Contents
IntroductionBackground on NLP TechniquesDecoding the Foundations: RAG and Fine-Tuning UnveiledRetrieval-Augmented Generation (RAG) ExplainedFine-Tuning DemystifiedRAG vs Fine-Tuning Face-Off: Performance MetericsAccuracy and PrecisionAdaptability and GeneralizationResource Requirements and Computational DemandsInference Speed and LatencyImplementation Strategies: Bringing RAG and Fine-Tuning to LifeRAG Implementation BlueprintFine-Tuning Implementation BlueprintBest Practices for Fine-Tuning ImplementationChoosing the Right AI Model Enhancement Technique for the JobWhen RAG ShinesWhere Fine Tuning ShinesConclusionFrequently Asked Questions