Researchers point to pure-convolutional networks as a key for next-generation computer vision
Considered obsolete since the introduction of vision transformers, ConvNeXt proves there's life in convolution yet — outperforming its rivals by adopting some of their own tricks.

01 Feb, 2022. 4 min read

Traditional convolutional networks can beat their transformer successors at image processing tasks, researchers have found.
The field of machine learning is one of the most rapidly-evolving in computer science. Journals the world around are filled with papers detailing new breakthroughs and novel approaches to solving real-world problems. A team of scientists at Facebook AI Research (FAIR) and the University of California at Berkeley, however, believes that things may have branched off in a suboptimal direction in 2020 - and have the figures to prove that looking backwards may pay dividends.
Researchers Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trever Darrell, and Saining Xie have describe the current era as "the 'Roaring 20s' of visual recognition," a period which they say began with the introduction of Vision Transformers. Based on technology originally developed for natural language processing (NLP), Vision Transformers proved their worth for image classification in a 2020 paper by Alexey Dosovitskiy and colleagues.
In the paper "An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale," Dosovitskiy and colleagues demonstrated how Vision Transformers — ViTs — could outperform traditional convolutional networks — ConvNets — while delivering a dramatic reduction in the computational resources required for training.
It was a convincing argument, to the point that research focus shifted almost exclusively to ViTs. Abandoning ConvNets, though, may not have been the best approach, as Liu and colleagues demonstrate in their paper "A ConvNet for the 2020s."
What's Old is New Again
In the paper, the researchers detail a family of novel ConvNet models dubbed ConvNeXt. In much the same way as previous researchers have taken techniques developed for ConvNet models and applied them to ViTs to improve accuracy and performance for tasks including object detection and semantic segmentation, Liu and colleagues have taken improvements made to ViTs and applied them to ConvNets.
"Constructed entirely from standard ConvNet modules," the researchers explain in the abstract to their paper, "ConvNeXts compete favorably with Transformers in terms of accuracy and scalability."
To prove the potential of their next-generation ConvNet approach, the team looked to hybrid ViTs: Hierarchical Transformers, like the hugely successful Swin Transformer introduced in 2021. Using this as a base, the team was able to showcase how ConvNeXt — which is a purely convolutional network — could outperform what has become recognised as the state-of-the-art approach, and reduce computational complexity into the bargain.
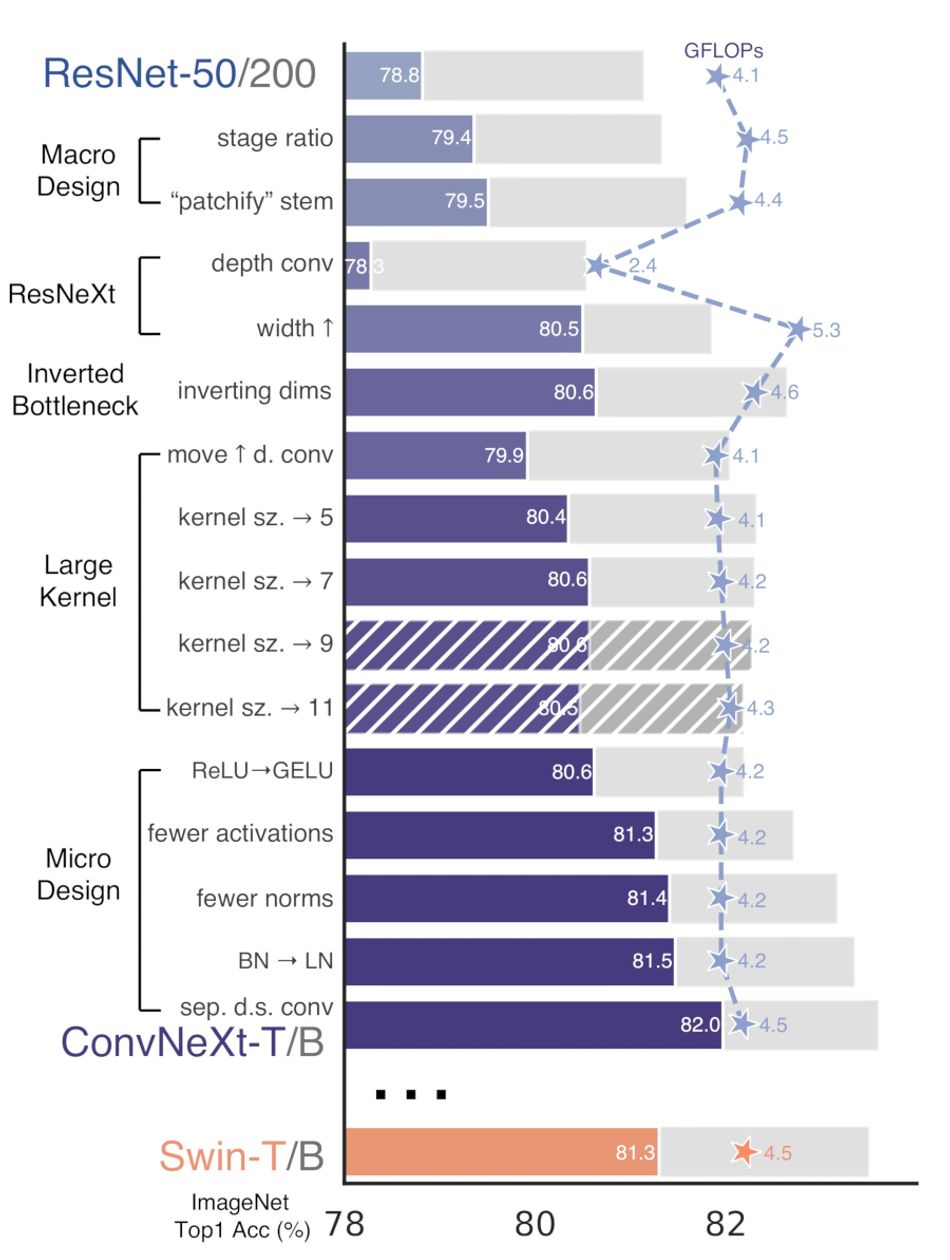
The ConvNeXt models were created using a five-stage design approach. The first stage, macro design, echoes parts of a Swin Transformer's macro network design with changes to the stage compute ratio and a shift to a "patchify" layer for the stem cell. The second, dubbed ResNexT-ify, tweaks the target ResNet model for an improved floating-point operations per second (FLOPs)/accuracy trade-off. The third, the inverted bottleneck, borrows another Transformer trick which reduces the overall FLOPs of the network but counter-intuitively boosts actual throughput.
The fourth tweak makes adjustments designed to use large kernel sizes rather than the small kernel sizes typically found in ConvNets. "Intriguingly," the researchers note in conclusion, "a significant portion of the design choices taken in a Vision Transformer may be mapped to ConvNet instantiations'' — allowing ConvNeXt to directly benefit from work done on improving the performance and accuracy of ViTs like the Swin Transformer.
A final design stage, micro design, makes other adjustments: Replacing the Rectified Linear Unit (ReLU) with the Gaussian Error Linear Unit (GELU), echoing a shift made in advanced Transformers; a move towards fewer activation functions and fewer normalization layers; a switch from BatchNorm, usually an essential component of ConvNets, to the simpler Layer Normalization; and the use of separate downsampling layers.
Proving the Performance
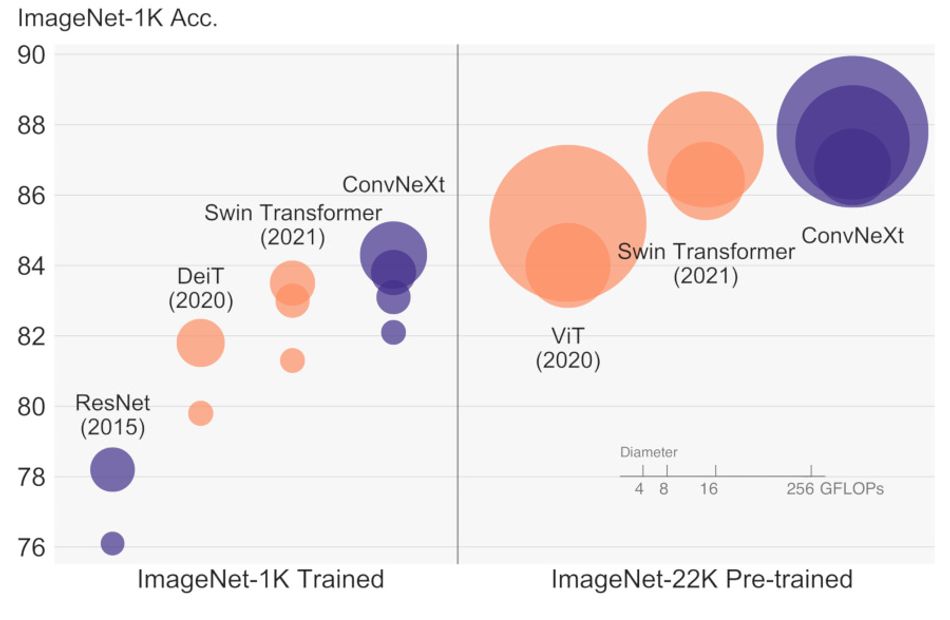
While each tweak made a relatively minor difference to performance or accuracy, taken as a whole it was enough to boost the capabilities of ConvNeXt considerably. In testing, using the ImageNet-1K dataset for training and fine-tuning and the ImageNet-22K dataset for pre-training, the team found ConvNeXt outperforming both the performance baselines — RegNet and EfficientNet — as well as a Swin Transformer of similar complexity, raising accuracy by as much as 0.8 per cent and throughput by up to 12.5 per cent compared with the latter.
Despite these improvements, which Liu and colleagues note increase as the network is scaled up, ConvNeXt also proved more efficient at the training stage, reducing the amount of memory required from 18.5GB for Swin-B to 17.4GB.
"In some ways, our observations are surprising while our ConvNeXt model itself is not completely new," Liu and colleagues write by way of conclusion. "Many design choices have all been examined separately over the last decade, but not collectively. We hope that the new results reported in this study will challenge several widely held views and prompt people to rethink the importance of convolution in computer vision."
The paper "A ConvNet for the 2020s'' is available under open-access terms on Cornell's arXiv.org preprint server. A PyTorch implementation of ConvNeXt is available on the Facebook Research GitHub repository, alongside pre-trained models, under the permissive MIT License.
References
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie: A ConvNet for the 2020s. DOI arXiv:2201.03545 [cs.CV]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. DOI arXiv:2010.11929 [cs.CV]