AI Infrastructure Engineering: Building Enterprise-Scale Machine Learning Systems
This article covers advanced architectural patterns, performance optimisation strategies, and critical operational considerations for building production-grade AI infrastructure systems!

11 Apr, 2025. 13 minutes read

AI Infrastructure Engineering: Building Enterprise-Scale Machine Learning Systems
No time now? Save for later.
We only use your email to send this link. Privacy Policy.
Introduction
Scaling AI workloads in enterprise environments requires more than powerful algorithms—it demands robust, enterprise-grade AI infrastructure. With the increase in data volumes and model complexities, the ability to efficiently manage compute, storage, and network resources becomes mission-critical.
AI Infrastructure plays a pivotal role in ensuring the success of machine learning operations. From provisioning specialised hardware like GPUs to implementing distributed systems for seamless data flow, the underlying architecture determines the efficiency, reliability, and scalability of AI applications. Strategic architectural decisions, such as adopting containerisation for flexibility or designing scalable storage solutions, can significantly impact overall performance.
This article explores the critical architectural components and operational strategies essential for enterprise-scale AI infrastructure systems. Designed for infrastructure engineers and ML platform architects, it offers practical guidance on resource orchestration, fault tolerance, and scalability—cornerstones of a future-proof AI infrastructure.
Core Architecture Components
Compute Resource Management
Modern GPUs are the backbone of AI workloads, offering massive parallelism and exceptional throughput needed for training and inference of Machine Learning and Deep Learning models. These processing units are specifically engineered to handle the compute-intensive operations required in AI infrastructure, such as matrix multiplications and convolutions.
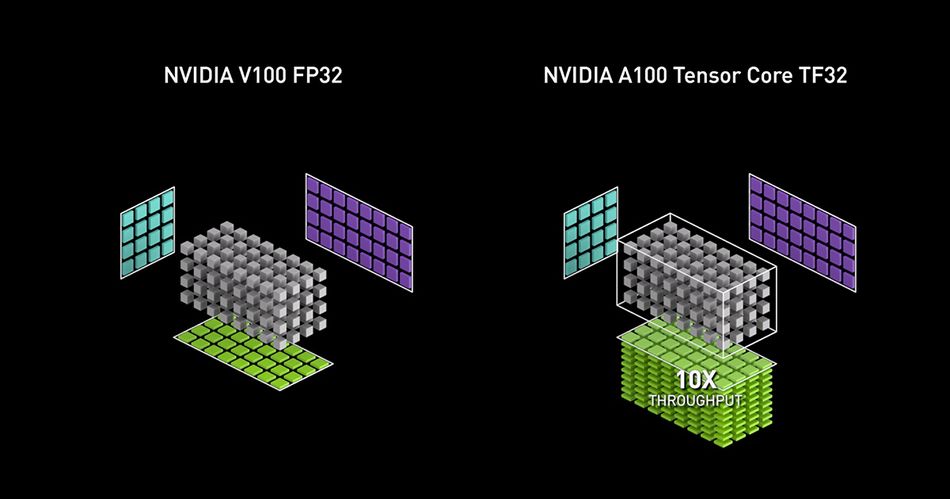
Key architectural advancements in modern GPUs include Tensor Cores for rapid matrix multiplications, high-bandwidth memory (HBM) for fast data transfer, and multi-GPU scaling technologies like NVLink and PCIe Gen5. [1] These features allow for the execution of large-scale machine learning models across distributed data Centers, making it possible to meet the growing computational demands of real-time inference systems and AI development pipelines.
Hardware Acceleration Requirements:
Artificial Intelligence systems benefit enormously from hardware acceleration, especially in large-scale model training tasks. Modern GPUs like NVIDIA A100, V100, and AMD MI250 are optimised for machine learning operations with capabilities such as tensor core acceleration, shared memory, and high-speed interconnects like NVLink. These features significantly reduce training time and improve overall throughput.
Below is the comparison of GPU architectures:
| GPU Model | Tensor Cores | Memory Bandwidth (GB/s) | Compute Performance (TFLOPS) |
| NVIDIA A100 | Yes | 1555 | 19.5 |
| NVIDIA V100 | Yes | 900 | 15.7 |
| AMD MI250 | No | 1638 | 22.0 |
| Google TPU v4 | N/A | N/A | 27.0 |
The choice of processing units significantly affects training time, inference speed, and cost optimization strategies. TPUs are often preferred for cloud-based environments and deep learning frameworks like TensorFlow, whereas GPUs are favored for broader support across platforms such as PyTorch.
Memory Specifications:
Minimum VRAM per GPU: 16 GB for medium complexity workloads; 40–80 GB for LLMs and generative AI
Shared Memory Pool for Multi-GPU Nodes: At least 512 GB RAM per node for optimal communication and memory sharing
Bandwidth Requirements: Above 800 GB/s recommended for model training of vision and language models
By leveraging specialised GPUs, memory-optimized configurations, and intelligent orchestration tools, enterprises can accelerate model development, reduce training time, and deploy high-performance AI applications at scale. With a solid compute architecture in place, the next step is to ensure data is fed into the system as efficiently as it's processed—enter distributed storage systems!
Recommended Reading: High Bandwidth Memory: Concepts, Architecture, and Applications
Distributed Storage Systems
Once AI systems are scaled, the underlying data storage architecture becomes increasingly critical. Distributed file systems are fundamental to supporting large-scale AI workloads, ensuring efficient data access and high throughput. Architectures like HDFS, Ceph, and Lustre provide robust mechanisms for data distribution, replication, and fault tolerance. [2] These systems utilise metadata servers to manage file allocation across storage nodes while maintaining scalability.
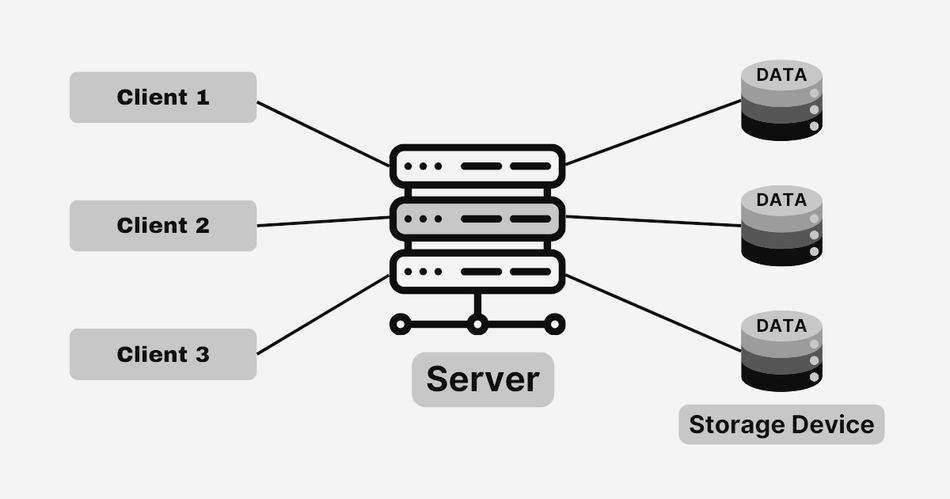
These storage architectures include metadata servers that handle namespace operations and multiple data nodes responsible for storing data chunks. Replication ensures redundancy, while data sharding and load balancing maintain performance at scale.
Data Locality Optimization Techniques:
Performance in AI workloads is tightly linked to the ability to reduce latency through optimisation of data locality. The techniques include:
Placing compute nodes near storage clusters
Using intelligent sharding algorithms to co-locate data with relevant compute
Adding caching layers using SSDs or NVMe to bring hot data closer to processing units
These techniques reduce network load and improve the efficiency of training pipelines, particularly in real-time applications like autonomous vehicles and fraud detection systems.
Performance Benchmarking Metrics:
Key metrics for assessing distributed storage systems include:
Throughput: Measured in MB/s or GB/s; essential for bulk data ingestion and model training
Latency: <10 ms for accessing critical training or inference files
IOPS: Thousands to millions of IOPS needed for random access during AI app deployment and MLOps pipelines
Specific Storage Requirements for Different ML Workloads:
Training Large Models: High-throughput NAS/SAN systems, RAID 10 configurations, redundant SSD clusters
Inference Systems: Low-latency SSDs, memory-tiered caching, pre-warmed model stores
Data Preprocessing Pipelines: Batch access to raw files, support for compression (e.g., gzip, parquet), and fast decompression engines
Distributed storage is all about performance, reliability, and alignment with AI workflows. The right system enables seamless data streaming to GPUs, supports large-scale model checkpoints, and powers AI tools through all phases of the AI lifecycle. With storage optimised, the final pillar of robust AI infrastructure is a resilient and low-latency network.
Recommended Reading: In Memory Compute: Transforming Data Processing for Speed and Scalability
Networking Infrastructure
In enterprise-scale AI systems, the network acts as the communication backbone—connecting compute nodes, storage systems, and orchestration layers that manage everything from model training to real-time inference. Poor network design can introduce bottlenecks that hinder scalability and degrade performance, especially in data centers running large-scale machine learning pipelines.
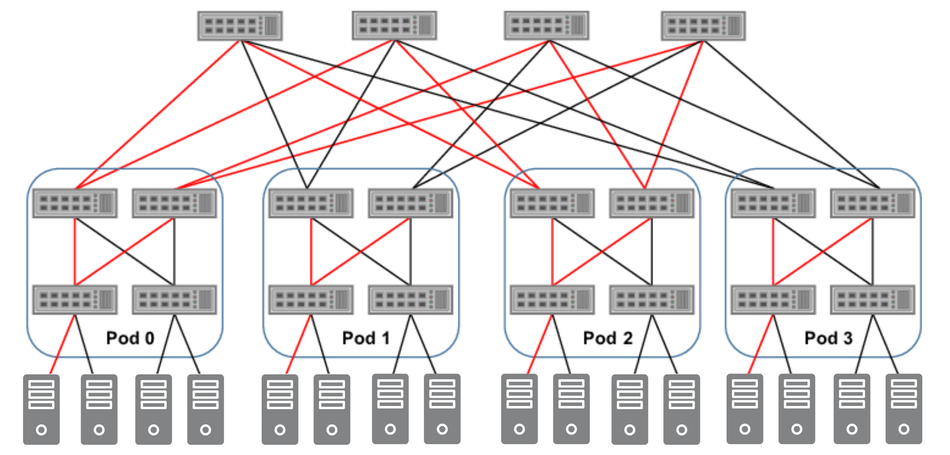
Modern topologies such as fat-tree, mesh, and leaf-spine are commonly deployed to support these demands. [3] Among them, fat-tree architectures are favored for their predictable performance and fault tolerance, making them ideal for scalable AI infrastructure that must handle millions of operations per second across apps, services, and users.
Bandwidth Optimization Techniques:
For high-speed distributed computing, bandwidth must be both abundant and intelligently allocated. The common optimization strategies include:
QoS policies prioritise traffic, such as parameter updates and checkpoint synchronisation
Adaptive load balancing ensures even data flow across high-capacity network paths
Compression and decompression algorithms reduce transmission sizes for bulk dataset transfers
Latency Considerations:
Low-latency networking is vital for synchronizing models in real-time and minimizing delays in AI applications. This requires:
Reducing node-to-node interconnection delay via top-of-rack and leaf-spine designs
Integrating smart NICs with RDMA (Remote Direct Memory Access) for zero-copy transfers
Deploying low-latency switches like InfiniBand for HPC clusters
Table of Network Protocols and Their Use Cases:
| Protocol | Use Case |
| TCP | Reliable data transfer for training |
| UDP | High-speed, low-latency data streams |
| RDMA | Direct memory access for High-Performance Computing (HPC) |
| gRPC | Communication between microservices |
| HTTP/HTTPS | Web-based AI services |
Technical Specifications for Network Requirements:
Bandwidth: Minimum 10 Gbps for inter-node communication, scaling up to 100 Gbps for high-performance systems.
Latency: Sub-millisecond latency for intra-cluster communication.
Packet Loss Rate: Below 0.01% to avoid significant performance degradation in distributed training tasks.
Jitter: Below 1 ms for consistent performance in real-time inference systems.
Additionally, for cloud-based AI platforms, providers often offer software-defined networking (SDN) solutions that enable dynamic scaling and isolation between tenants—critical for shared data center environments handling diverse use cases ranging from healthcare to autonomous driving.
Recommended Reading: HBM2 vs GDDR6: Engineering Deep Dive into High-Performance Memory Technologies
Implementation and Deployment
Containerization Strategies
Modern AI infrastructure heavily depends on containerization to abstract away system dependencies, isolate resources, and standardize deployments across environments. Containers provide lightweight, portable environments for running machine learning models, preprocessing jobs, and AI applications. The de facto orchestration tool for containerized systems is Kubernetes, which supports autoscaling, fault tolerance, and resource-aware scheduling—all essential for managing dynamic AI workloads.
Kubernetes also integrates seamlessly with CI/CD pipelines, MLOps platforms, and popular frameworks like TensorFlow Serving, TorchServe, and NVIDIA Triton Inference Server.
Kubernetes Configuration Examples:
Here’s a basic deployment manifest to run an AI workload using container orchestration:
apiVersion: apps/v1 kind: Deployment metadata: name: ai-workload spec: replicas: 3 selector: matchLabels: app: ai-model template: metadata: labels: app: ai-model spec: containers: - name: ai-container image: ai-model:latest resources: requests: memory: "4Gi" cpu: "2" limits: memory: "8Gi" cpu: "4"
This configuration ensures that AI apps have enough memory and CPU to run reliably while allowing Kubernetes to manage scaling and fault recovery across nodes.
Resource Quota Management:
Kubernetes ensures resource efficiency by defining quotas at the namespace level, allowing administrators to allocate compute and memory resources to specific applications. Here's how to define resource limits at the namespace level:
apiVersion: v1 kind: ResourceQuota metadata: name: compute-quota namespace: ai-namespace spec: hard: requests.cpu: "10" requests.memory: "20Gi" limits.cpu: "20" limits.memory: "40Gi"
Quotas help system administrators maintain fairness and predictability in shared AI systems, especially when running multiple concurrent AI workloads.
Optimizing Container Images:
One of the best practices in container optimization is reducing image size and runtime overhead. Here's an example using multi-stage builds in Docker:
# Stage 1: Build FROM python:3.8 AS builder WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt # Stage 2: Runtime FROM python:3.8-slim COPY --from=builder /app /app WORKDIR /app CMD ["python", "main.py"]
Using minimal base images (e.g., Alpine, Slim) and excluding build tools from the final image significantly reduces the attack surface and startup time—crucial for deploying real-time AI applications in production.
Containerization simplifies deployment, boosts reproducibility, and enhances scalability in modern AI systems! With Kubernetes at the center, organizations can deploy and manage containerized AI solutions with fine-grained control over resources and scaling policies. The next layer of operational maturity lies in managing complex workflows using structured orchestration tools that monitor and automate AI workloads end to end!
Pipeline Orchestration
In real-world AI infrastructure, a single training or inference job rarely operates in isolation. Instead, these tasks are part of a broader workflow that includes data ingestion, cleaning, transformation, model training, validation, deployment, and monitoring. Orchestration tools like Apache Airflow, Prefect, and Kubeflow Pipelines provide the framework for automating these pipelines. [4] This ensures that every stage executes in the right order, with built-in fault tolerance and real-time monitoring.
Data Pipeline Optimization Techniques:
To improve the efficiency and fault-tolerance of ML pipelines, follow these techniques:
Parallelization: Run multiple tasks concurrently (e.g., data slicing, hyperparameter tuning)
Checkpointing: Save intermediate states to avoid repeating completed steps in case of failure
Data Partitioning: Distribute large datasets across nodes to speed up data processing
These optimization strategies minimize runtime and increase resilience, especially for large-scale AI workloads.
Data Pipeline Optimization Techniques
Robust monitoring tools are essential to maintain reliability and traceability across AI pipelines. Key strategies include:
Real-time logging using tools like ELK Stack, Fluentd, or CloudWatch
Alerting and notifications for task failures or threshold breaches
Visual dashboards (e.g., Grafana, Airflow UI) to track execution flow, durations, and bottlenecks
These capabilities ensure visibility into the entire lifecycle of AI workloads, from development to deployment.
Code Example for Airflow DAG Configuration:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def preprocess_data():
# Data preprocessing logic here
pass
def train_model():
# Model training logic here
pass
def deploy_model():
# Deployment logic here
pass
define_args = {
'owner': 'airflow',
'start_date': datetime(2025, 1, 1),
'retries': 1
}
dag = DAG(
dag_id='ml_pipeline',
default_args=define_args,
schedule_interval='@daily',
)
preprocess_task = PythonOperator(
task_id='preprocess',
python_callable=preprocess_data,
dag=dag
)
train_task = PythonOperator(
task_id='train',
python_callable=train_model,
dag=dag
)
deploy_task = PythonOperator(
task_id='deploy',
python_callable=deploy_model,
dag=dag
)
preprocess_task >> train_task >> deploy_taskThis simple DAG outlines the modularity and reusability of workflow components, which are critical in AI initiatives focused on continuous training, deployment, and monitoring.
Recommended Reading: Leveraging Edge Computing for Generative AI
Performance Optimization
Resource Utilization
Effective resource utilization in AI systems relies on continuous monitoring, optimization, and adherence to key performance metrics. Implementing advanced techniques ensures that resources are used efficiently without sacrificing performance or scalability.

A well-optimized system maximizes output per unit resource while ensuring resilience and adaptability under fluctuating loads. This is key to supporting large-scale AI workloads, where real-time processing, framework compatibility, and GPU acceleration must operate in harmony.
Resource Monitoring Techniques:
Agent-Based Monitoring: Deploy agents such as NVIDIA DCGM, Node Exporter, or Kube-state metrics on each node to track usage of GPUs, CPUs, memory, disk I/O, and network bandwidth in real-time.
Logging and Visualization Tools: Use Prometheus, Grafana, and Loki to collect, store, and display telemetry data. Integrating these with Kubernetes clusters provides a bird's-eye view of resource consumption across services.
Threshold-Based Alerts: Configure alerts using tools like Alertmanager or Datadog to notify teams when compute, memory, or IOPS exceed defined thresholds—helping avoid performance degradation before it impacts users.
Optimization Algorithms:
1. Load Balancing:
Round-Robin: Distributes workloads sequentially, ideal for stateless AI applications.
Least Connections: Assigns tasks to the least-loaded server, perfect for real-time inference engines.
2. Task Scheduling:
Earliest Deadline First (EDF): Prioritizes tasks by their deadline, minimizing latency in real-time data processing.
Shortest Job First (SJF): Ideal for batch machine learning training jobs that can be parallelized.
3. Reinforcement Learning-Based Optimization:
Use RL agents trained to dynamically allocate GPUs, adjust resource limits, or reassign workloads based on observed performance—especially useful in cloud-based and on-premises hybrid environments.
Performance Metrics:
| Metric | Description |
| Compute Utilization | Percentage of CPU/GPU cycles actively used |
| Memory Usage | Active vs available memory footprint |
| Throughput | Number of successful executions per second |
| I/O Wait Time | Delay caused by pending I/O operations |
| Latency | Time taken from input to model prediction |
Technical Specifications for Resource Allocation:
CPU Allocation: Minimum of 4 cores per task, scaling to 32 cores for intensive computations.
GPU Allocation: 1 GPU per task for standard workloads; multi-GPU setups for high-performance training.
Memory Requirements: At least 8 GB per task, scaling to 64 GB for data-heavy operations.
Network Bandwidth: Minimum 10 Gbps for inter-node communication to avoid bottlenecks.
Recommended Reading: Revolutionizing Edge AI Model Training and Testing with Nvidia Omniverses Virtual Environments
Scaling Mechanisms
Scaling mechanisms ensure that computational resources grow or shrink to meet workload requirements, minimizing cost and maximizing availability. This capability is especially vital in cloud-based environments and intelligent edge systems where usage patterns can vary dramatically.
There are two primary forms of scaling:
Horizontal Scaling: Adds more instances/nodes to a cluster
Vertical Scaling: Increases capacity (CPU/GPU/RAM) of existing nodes
Both approaches are often implemented using autoscaling frameworks native to platforms like Kubernetes, AWS Auto Scaling, or GCP Autoscaler.
Load Balancing Strategies:
To ensure balanced usage and fault tolerance:
Round-Robin: Simple and effective in evenly distributing incoming requests.
Least-Response-Time: Routes new requests to nodes responding the fastest, reducing latency in real-time AI applications.
Application-Aware Load Balancers: Use application metadata (e.g., model version, resource needs) to prioritize critical tasks—ideal for multi-model AI platforms.
Capacity Planning Methods:
Workload Profiling: Analyze workloads under various conditions to understand resource spikes and bottlenecks.
Historical Usage Trends: Use machine learning to forecast future demand and avoid overprovisioning.
Reserve Pooling: Allocate a buffer zone of unused resources for mission-critical services to avoid downtimes during spikes.
Technical Benchmarks:
Scaling Time: Should not exceed 30 seconds for horizontal scaling in cloud environments.
Load Distribution Efficiency: At least 90% even workload distribution across nodes.
Resource Utilization: Maintain CPU and memory utilization between 60-80% to ensure headroom for surges.
Throughput: Minimum of 10,000 requests per second for large-scale AI technology inference systems.
Integrating these scaling methods into AI infrastructure helps support continuous delivery pipelines, automatic failovers, and surge handling in production-grade AI applications.
Recommended Reading: Harnessing AI Platforms for Rapid Development and Deployment of Predictive Maintenance Systems in Industrial Applications
Operational Excellence
Monitoring and Observability
Monitoring and observability are cornerstones of sustainable AI operations, providing deep visibility into system behavior, detecting anomalies in real-time, and enabling swift response to emerging issues. These practices are crucial for scalable, production-grade deployments where thousands of GPUs, containers, and apps work in tandem across distributed data centers.

Monitoring Stack Components:
1. Centralized Logging with ELK Stack:
Elasticsearch: Indexes and searches logs across microservices.
Logstash: Ingests logs from sources like Kubernetes, containers, and application runtimes.
Kibana: Provides rich visualization for trends and error correlation.
2. Prometheus for Metrics Collection:
Pulls metrics at custom intervals from endpoints exposed by services (e.g., /metrics)
Monitors CPU, GPU, memory, disk I/O, and real-time throughput of AI workloads
3. Grafana for Visualization:
Custom dashboards displaying infrastructure health, training job performance, latency charts, and anomaly trends
Supports alerts, annotations, and templating for live monitoring of machine learning pipelines
Metrics Collection Methods:
1. Agent-Based Collection: Tools like Node Exporter, DCGM Exporter, and Telegraf run as DaemonSets in Kubernetes, collecting node-level and GPU-specific metrics.
2. Push-Based Monitoring: Suitable for custom apps and automation scripts, where metrics are pushed to a central time-series database using APIs.
3. Sampling Techniques:
Adaptive sampling for high-frequency metrics (e.g., GPU temps, inference latency)
Fixed-rate sampling for stable metrics (e.g., disk usage, network throughput)
Alerting Strategies:
1. Threshold-Based Alerts: Trigger alerts when metrics cross predefined thresholds—e.g., GPU memory usage > 90%, or inference latency > 200ms
2. Escalation Policies:
Tiered Notifications: DevOps first, then on-call engineers, then escalation to SRE leads
Supports integration with PagerDuty, Slack, Opsgenie, or Microsoft Teams
3. Automated Response: Trigger remediation scripts (e.g., auto-restart pod, scale-out nodes) based on alert severity
Table of Monitoring Tools:
| Tool | Purpose | Key Features |
| Prometheus | Metrics collection | Real-time data scraping and alerting |
| Grafana | Visualization | Custom dashboards and analytics |
| ELK Stack | Centralized logging | Full-text search and filtering |
| PagerDuty | Incident management | Automated alert escalation |
Technical Specifications for Monitoring Requirements:
Sampling Rate: Minimum of 1-second intervals for high-priority metrics.
Alert Latency: Ensure alerts are delivered within 5 seconds of threshold breaches.
Storage Retention: Retain logs and metrics for a minimum of 30 days to enable historical analysis.
System Coverage: Monitor 100% of compute nodes and at least 95% of network traffic.
With real-time insights and automated alerts, operational teams can maintain the availability and performance of AI applications, regardless of scale or complexity.
Security and Access Control
With sensitive data, critical models, and high-value intellectual property at stake, security and access control are non-negotiable pillars of modern AI infrastructure. As organizations adopt cloud-based, hybrid, and on-premises AI solutions, the security surface expands—making consistent enforcement of access policies, encryption standards, and compliance protocols essential.
A robust security strategy covers everything from secure authentication to data encryption, RBAC, and traffic control across the entire AI lifecycle—from development to deployment.
Security Architecture:
1. Layered Defense (Defense-in-Depth):
Application Layer: WAFs, input validation, secure code
Network Layer: Firewalls, VLAN isolation, IP whitelisting
Infrastructure Layer: OS hardening, access control, patch management
2. Zero-Trust Architecture:
No default trust within the network—even internal systems must authenticate
Continuous verification of identity, location, device health
3. Role-Based Access Control (RBAC):
Define roles like data scientist, ML engineer, platform admin
Assign granular permissions for dataset access, model deployment, and cluster configuration
Authentication Mechanisms:
1. Multi-Factor Authentication (MFA): Adds a second layer to password-based login, reducing brute-force and phishing risks.
2. OAuth 2.0 Integration: Enables token-based access control for REST APIs, CLI tools, and microservices in AI platforms.
3. Single Sign-On (SSO): Streamlines user access across the ecosystem while centralizing user management and auditing.
Encryption Protocols:
1. At Rest:
Encrypt all stored data with AES-256
Use Key Management Services (KMS) for centralized encryption key rotation
2. In Transit:
Enforce TLS 1.3 for all data movement between nodes, external APIs, and cloud services
Use mutual TLS (mTLS) for service-to-service authentication in containerized environments
3. End-to-End Encryption (E2EE):
Protect sensitive model predictions and real-time inference data exchanged between edge devices and central inference servers
Technical Specifications for Security Requirements:
Access Logs: Retain logs for at least 90 days, with automated alerts for unauthorized access attempts.
Key Management: Use a centralized key management service (KMS) with automated rotation.
Compliance Standards: Ensure adherence to industry standards such as GDPR, HIPAA, or ISO 27001.
Firewall Rules: Define inbound and outbound traffic rules to restrict unauthorized connections.
By implementing layered security, enforcing zero-trust principles, and integrating encryption into every level of the stack, organizations can mitigate risks while maintaining speed and agility in AI development.
Recommended Reading: Building an Edge AI Ecosystem
Conclusion
The development of enterprise-scale AI systems requires careful architectural planning to ensure robust performance and scalability. Key decisions include leveraging distributed storage systems for high-throughput data access, adopting auto-scaling mechanisms for dynamic workload management, and implementing comprehensive monitoring stacks for operational visibility. Success hinges on strategic resource allocation, secure data transmission, and seamless integration of network and compute resources. Actionable next steps include conducting a thorough infrastructure audit to identify bottlenecks, deploying containerized solutions for improved deployment efficiency, and implementing proactive alerting mechanisms to maintain system reliability.
Frequently Asked Questions
Q. What are the key considerations for scaling AI systems?
A. Scaling AI systems involves balancing compute, storage, and networking resources. Auto-scaling and load-balancing strategies are essential for handling dynamic workloads.
Q. How does advanced AI differ from traditional AI models?
A. Advanced AI includes deep neural networks, generative models, and ML models capable of complex tasks such as autonomous navigation, natural language understanding, and predictive decision-making in real-time environments.
Q. How can resource utilization be optimized in AI infrastructure?
A. Optimization involves using advanced algorithms for dynamic allocation, setting resource quotas, and employing monitoring tools like Prometheus to track real-time performance metrics.
Q. What factors influence the pricing of AI infrastructure for enterprise deployment?
A. Pricing depends on hardware specifications (e.g., GPUs, TPUs), scalability requirements, data management needs, and software licensing—especially when combining open source tools with proprietary orchestration or security layers.
Q. What are the core components of AI infrastructure?
A. They include compute resources (CPUs/GPUs/TPUs), storage systems (e.g., object stores), network interconnects, orchestration platforms, monitoring tools, and secure APIs to manage the AI lifecycle efficiently.
References
[1] NVIDIA. Tensor Cores: Versatility for HPC & AI [Cited 2025 April 10] Available at: Link
[2] MDPI. Distributed File System to Leverage Data Locality for Large-File Processing [Cited 2025 April 10] Available at: Link
[3] MDPI. Arithmetic Study about Efficiency in Network Topologies for Data Centers [Cited 2025 April 10] Available at: Link
[4] IRE Journal. Building Scalable Data Pipelines for Machine Learning [Cited 2025 April 10] Available at: Link
in this article
1. Introduction2. Core Architecture Components3. Implementation and Deployment4. Performance Optimization5. Operational Excellence6. Conclusion7. Frequently Asked Questions8. ReferencesNo time now? Save for later.
We only use your email to send this link. Privacy Policy.