Intelligence at Scale Through AI Model Efficiency
Optimizing AI for the Future: Model Efficiency and Scalability

03 Oct, 2023. 8 minutes read

Artificial Intelligence (AI) has become an indispensable tool in the modern era, driving innovations across various sectors and reshaping how we interact with technology. However, ensuring model efficiency remains a significant challenge as AI models become complex. AI's influence is bound to be ubiquitous, from smartphones that predict our next word to autonomous vehicles that navigate our roads.
The promise of AI lies in its ability to process vast amounts of data, learn from it, and make intelligent decisions. This transformative power of AI is evident across a spectrum of applications: from autonomous vehicles navigating complex urban environments to healthcare systems predicting patient outcomes, virtual reality creating immersive experiences, and IoT devices optimizing energy consumption in real-time. Qualcomm, a global leader in wireless and computing technology, has been instrumental in addressing the model scaling challenges.1 Their expertise in mobile technology positions them uniquely to optimize AI for efficiency and to scale it across edge devices. As AI continues to permeate every facet of our lives, understanding and addressing the challenges of model efficiency will be pivotal.
The Need for Efficient AI Models
Artificial Intelligence (AI) is a beacon of innovation in today's digital age, driving advancements across various sectors and reshaping our interactions with technology. However, a closer look reveals a dichotomy: while AI models are growing exponentially, the data they are trained on, primarily sourced online, needs to catch up.2 This disparity underscores the importance of AI in our world today. If we envision AI to enhance our lives ubiquitously, running seamlessly in the background, its efficiency becomes non-negotiable.
The digital universe expands with every click, search, and online interaction. But the rapid growth of AI models, which rely heavily on this data, is outstripping the data's growth rate. This rapid expansion of models, while enabling sophisticated functionalities, is challenging, and one of the most pressing concerns is energy consumption. The brilliance of AI is powered by an energy-intensive process, often leaving a significant carbon footprint.3 For instance, the computing power required to train cutting-edge AI models has increased staggeringly, doubling every 4 months.3
Such energy demands have tangible environmental repercussions. The more complex these AI models become, the more energy they require, increasing greenhouse gas emissions. For instance, a recent study by Google reported that training GPT-3 with 175 billion parameters consumed 1287 MWh of electricity, resulting in 552 metric tons of carbon emissions. This is equivalent to driving 112 gasoline-powered cars for a year.
The increasing carbon footprint of AI models necessitates a shift towards more sustainable practices, such as on-device processing. Innovations such as specialized processing for AI, such as in Qualcomm’s Snapdragon 8 Gen 2 mobile platform, efficient algorithms, and the use of renewable energy in data centers are steps in the right direction. The AI community is also exploring quantization, pruning, and knowledge distillation to reduce the size and energy consumption of AI models.
Qualcomm is at the forefront of making AI more sustainable through its groundbreaking hardware and software technology. On-device AI offers benefits like user privacy, security, immediacy, energy efficiency, personalization, and cost-effectiveness. Moreover, Qualcomm Innovation Center's AI Model Efficiency Toolkit (AIMET) has been open-sourced, offering state-of-the-art quantization and compression techniques, further emphasizing their commitment to efficient AI.
What is Model Efficiency?
Model efficiency refers to the capability of an AI model to produce accurate results using minimal computational resources. The primary objective is to reduce the model's size and optimize its operations for speed, accuracy, and low energy consumption. Efficient models are crucial for real-time applications, where decisions must be made instantaneously, and for devices with limited processing capabilities or battery life.
To gauge the efficiency of AI models, understanding the following metrics is crucial:
FLOPs per Inference: Represent the number of floating-point operations a model performs to process a single piece of data. It measures the computational intensity of the model.2
Latency: The time a model takes to process an input and produce a result. Low latency is crucial for real-time applications like autonomous driving or voice assistants.2
Power Efficiency: Power efficiency, when referring to AI models, is typically measured in terms of the amount of power (usually in watts or milliwatts) consumed per inference or operation.5 For instance, if an AI model running on a specific chip consumes 10 milliwatts of power while processing 100 inferences throughout one second, its power efficiency would be 0.1 mW/Inf.
Inferences per Second: Reflects the number of data inputs a model can process within a second. It measures the model's throughput and is especially important for applications that require rapid responses.5
The efficiency of AI models is more than a technical requirement; it's necessary for the broader adoption of AI in real-world applications.
Innovations in AI Model Efficiency
Over the years, researchers have developed several techniques to optimize model performance without compromising accuracy. Here are some of the most notable innovations:
Quantization: Quantization involves converting continuous-valued parameters into discrete counterparts, typically reducing the precision of the model's weights while retaining most of the model’s accuracy. This reduces the model's memory footprint and speeds up inference, especially on hardware exploiting low-precision arithmetic.8
Pruning removes certain parts of neural networks, like weights or neurons, that contribute little to the model's output. This results in a smaller and faster model while retaining most of its accuracy.9
Knowledge Distillation: Knowledge distillation involves training a smaller model (student) to mimic the behavior of a larger, pre-trained model (teacher). The student model learns from the soft outputs of the teacher, achieving comparable performance with a fraction of the parameters.10
Neural Architecture Search (NAS): NAS automates finding the best neural network architecture. It uses search algorithms to explore a vast space of possible architectures, selecting the one that performs best on a given task.11
Conditional Computing: Conditional computing dynamically adjusts the computation of a neural network based on the input, executing only the necessary parts of the model. This leads to faster inference times without a significant drop in accuracy.12
Compiler Optimizations: Modern compilers for AI models can optimize the execution of models by fusing operations, rearranging computations, and leveraging hardware-specific instructions. These optimizations can lead to significant speed-ups in model inference while saving energy.13
In the race to achieve AI ubiquity, these innovations are crucial in ensuring accurate and computationally efficient models.
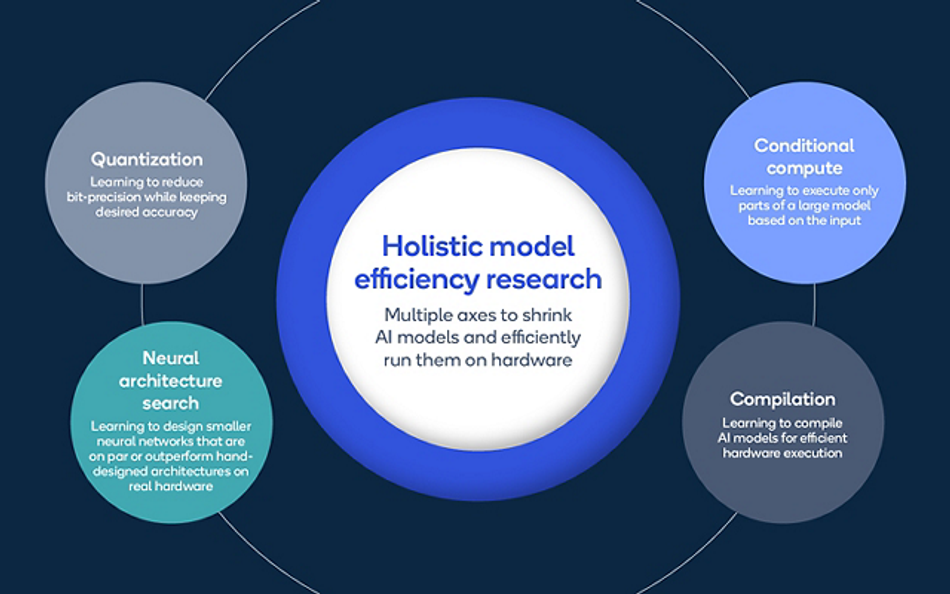
Case Studies
Qualcomm, a pioneer in on-device AI, has been at the forefront of optimizing these models to run efficiently on edge devices. Here are some notable case studies that highlight Qualcomm's achievements in this domain:
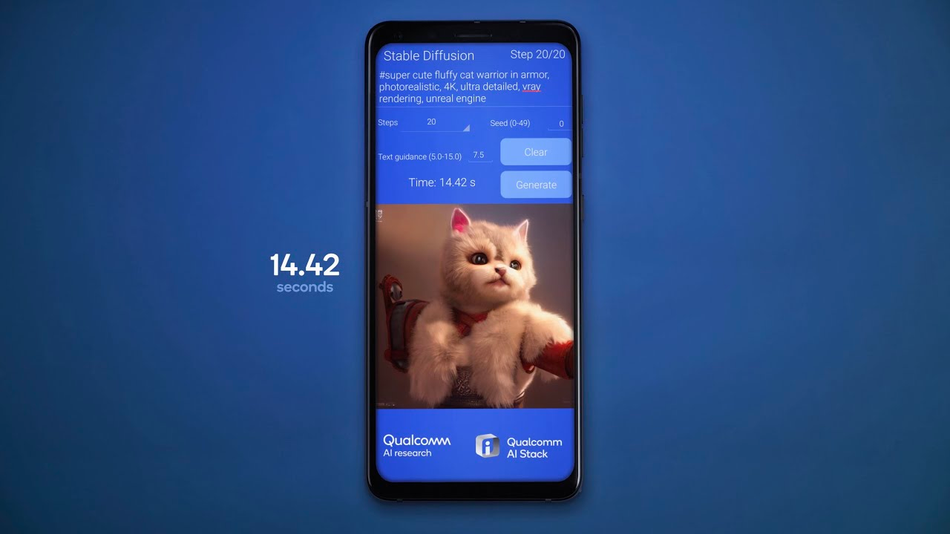
Stable Diffusion on Android Devices: Qualcomm AI Research recently showcased the world's first on-device demonstration of Stable Diffusion on an Android phone.14 Stable Diffusion, a popular foundation model with over 1 billion parameters, is known for generating photorealistic images from textual prompts. Traditionally, such a large model would be confined to cloud-based operations. However, Qualcomm's full-stack AI optimization allowed this model to run on an Android smartphone, producing images in under 15 seconds for 20 inference steps.14 This achievement underscores the potential of edge AI, where large AI models can operate seamlessly on handheld devices without compromising on performance or efficiency.
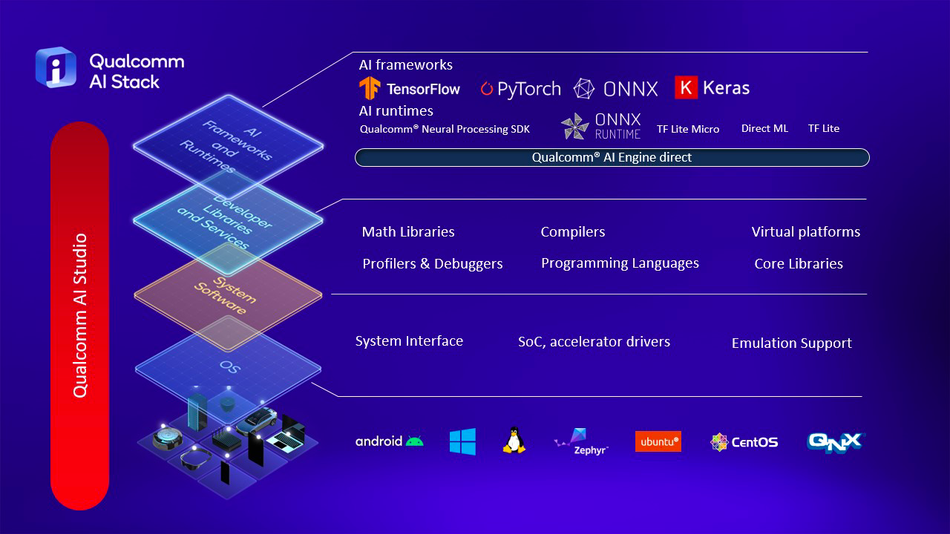
Full-Stack AI Optimization with Qualcomm AI Stack: Qualcomm's approach to AI optimization encompasses applications, neural network models, algorithms, software, and hardware.14 For instance, the Stable Diffusion model was optimized using the Qualcomm AI Stack, which involved quantization techniques from the AI Model Efficiency Toolkit (AIMET) and hardware acceleration on the Snapdragon 8 Gen 2 Mobile Platform.14 Such optimizations ensure that AI models, regardless of size, can run efficiently on devices powered by Qualcomm Technologies.
Qualcomm's commitment to on-device AI is further evidenced by its demonstrations at major conferences. At CVPR 2023, Qualcomm AI Research demonstrated ControlNet, a 1.5 billion parameter image-to-image model, running entirely on a mobile device.15 Similarly, at NeurIPS 2022, Qualcomm presented its cutting-edge research in machine learning, highlighting its efforts to bring AI closer to users, showing demonstrations such as real time INT4 4K super resolution on a smartphone.16
These case studies exemplify Qualcomm's commitment to pushing the boundaries of what's possible with on-device AI. Qualcomm is paving the way for a future where AI is ubiquitous, enhancing user experiences across various sectors by optimizing large and complex AI models to run efficiently on edge devices.
Conclusion
In the dynamic landscape of AI, the emergence of complex models has signaled both progress and challenges. These models, while groundbreaking, necessitate a renewed focus on efficiency to ensure their seamless deployment, especially on edge devices. Model efficiency is necessary for AI's sustainable and widespread adoption. Qualcomm's endeavors, epitomized by innovations like running Stable Diffusion on the device, emphasize the industry's commitment to harnessing AI's potential responsibly. For AI enthusiasts, the message is clear: the future of AI hinges on a delicate balance of power, precision, and pragmatism.
References
[1] Qualcomm: Wireless Technology & Innovation | Mobile Technology
[2] The Real Environmental Impact of AI | Earth.Org
[3] The Environmental Impact of AI
[4] AI’s Growing Carbon Footprint
[5] EENet: Learning to Early Exit for Adaptive Inference
[6] Challenges in Vertical Scaling for Machine Learning Models
[7] Horizontal Scaling in Distributed Deep Learning
[8] Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
[9] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
[10] Distilling the Knowledge in a Neural Network
[11] Neural Architecture Search with Reinforcement Learning
[12] Conditional Computation in Neural Networks for Faster Models
[13] Optimizing Neural Networks with Kronecker-factored Approximate Curvature
[14] World’s first on-device demonstration of Stable Diffusion on an Android phone
[15] Qualcomm at CVPR 2023: Advancing research & bringing generative AI to the edge
[16] NeurIPS 2022: Qualcomm showcases cutting-edge advancements in machine learning