Leveraging Edge Computing for Generative AI
Edge AI Technology Report: Generative AI Edition Chapter 1. Generative AI's demand for real-time insights is driving a shift from cloud to edge computing, enabling faster, local processing on devices and reducing cloud latency and bandwidth constraints.

19 Nov, 2024. 12 minutes read
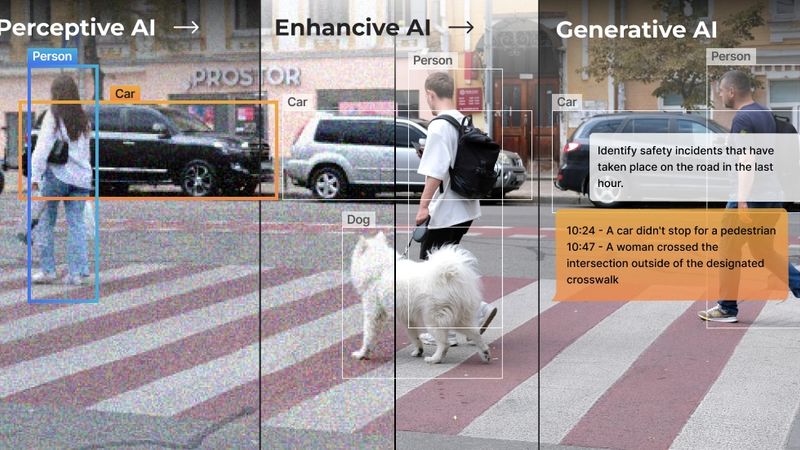
Image credit: hailo.ai
We once believed the cloud was the final frontier for artificial intelligence (AI), but it turns out the real magic happens much closer to home—at the edge, where devices can now think, generate, and respond in real-time. The rapid evolution of AI, particularly generative AI, is fundamentally reshaping industries and challenging the existing computing infrastructure.
Traditional models, especially resource-intensive ones like Large Language Models (LLMs), have long relied on centralized cloud systems for the necessary computational power. However, as the need for AI-driven interactions grows across sectors—from autonomous vehicles to personalized content generation—there is a clear shift toward edge computing.
Our new report, drawing from discussions with industry leaders and technologists, explores how generative AI is being harnessed and integrated into edge environments and what this means for the future of technology.
Below you can read an excerpt from the first chapter of the report, to read the full report download your copy below.

Generative AI has introduced a new wave of technological demands, particularly in infrastructure. Traditionally, AI models—especially resource-intensive ones like LLMs—have relied on centralized cloud computing to provide the computational muscle required for their complex processes. However, as industries push for more real-time interactions, the need to bring these AI capabilities closer to the user has become increasingly evident. This demand for instantaneous, AI-driven insights is fueling a shift toward edge computing, where data can be processed locally on devices, minimizing the latency and bandwidth constraints of cloud dependence.
Generative AI Across Edge Devices
In the convergence of generative AI and edge computing, each type of edge device plays a critical role in creating a seamless, responsive, and intelligent network. Implementing generative AI across these devices transforms how data is generated, processed, and utilized, enabling real-time decision-making and personalized experiences.
Sensors are the frontline in this ecosystem, capturing raw, real-world data that fuels generative AI models. In an industrial context, for example, sensors might continuously monitor machinery and feed data into AI models that predict maintenance needs or optimize operations in real time. The generative AI models at this level can begin making localized, immediate decisions based on the data they receive, adjusting parameters, or triggering alerts before data reaches higher processing layers.
Microcontrollers (MCUs) step in to handle more nuanced processing tasks. They enable on-device inferencing where immediate, low-power decisions are needed. For generative AI, MCUs could run simplified models or early-stage processing to filter or preprocess data before passing it to more capable devices. For example, an MCU in a smart home device could run a lightweight generative AI model that generates personalized voice responses or soundscapes based on user preferences and input data. In addition to recognizing commands, the MCU could generate real-time responses, like dynamically creating a specific ambient background noise to match user moods or generating personalized workout routines, reducing reliance on cloud processing and enhancing privacy.
Gateways bridge the high-volume, low-complexity tasks handled by sensors and MCUs with the more sophisticated processing done by edge servers. Through generative AI, gateways could aggregate and pre-process data from multiple sources, applying intermediate AI models that generate initial predictions or recommendations. For instance, in a smart city environment, a gateway might gather traffic data from various sensors, use generative AI to predict traffic patterns, and then share these insights with higher-level systems or directly with connected vehicles.
Edge Servers represent a critical component of edge computing infrastructure, handling more complex and resource-intensive tasks than smaller edge devices. However, edge servers operate under resource constraints, unlike cloud servers with abundant computational power, making it challenging to simultaneously host large generative AI models like LLMs. Instead, these servers focus on running optimized, smaller versions of models, employing techniques like model pruning and quantization to ensure efficient performance.
In environments such as healthcare, edge servers can process data from multiple medical devices in real time, utilizing optimized generative AI models to provide instant diagnostics or treatment recommendations. This localized processing reduces latency and increases reliability, which is essential for scenarios where rapid decisions are critical. However, deploying large-scale models across multiple edge servers requires careful orchestration and optimization to balance the limited computational resources.
In essence, the convergence of generative AI and edge computing is more than distributing computational tasks—it’s about enhancing the capability of each layer of the edge infrastructure to operate autonomously while contributing to a cohesive, intelligent system. This ensures that AI-driven insights are not only faster and more reliable but also more contextually aware, leading to smarter, more responsive applications across industries.
Advantages of Edge Computing in Real-world Deployments
One of the primary advantages of deploying generative AI at the edge is the significant reduction in latency. Applications requiring real-time responses, such as autonomous driving, robotics, and augmented reality, benefit greatly from processing data locally. Doing so minimizes the time taken to analyze data and execute actions, which is crucial for applications that must respond instantaneously to external stimuli. This reduction in latency is a key factor in the growing adoption of edge computing for AI deployments.
In addition to latency improvements, edge computing enhances data privacy and security. By keeping data processing local, edge computing reduces the need to transmit sensitive information over potentially insecure networks. This is particularly beneficial in sectors like healthcare and finance, where data breaches can have severe consequences. Local processing ensures that sensitive information remains within the device or the geographical boundaries of an organization, helping to comply with data sovereignty regulations.
Moreover, edge computing offers significant bandwidth savings. In cloud-centric models, large amounts of data must be transmitted to and from the cloud, which can be relatively costly and inefficient. Edge computing mitigates this by processing data at the source, reducing the need for extensive data transfer and conserving bandwidth. This is especially advantageous in environments with limited connectivity or where data transmission costs are a concern, such as remote monitoring systems and industrial Internet of Things (IoT) deployments.
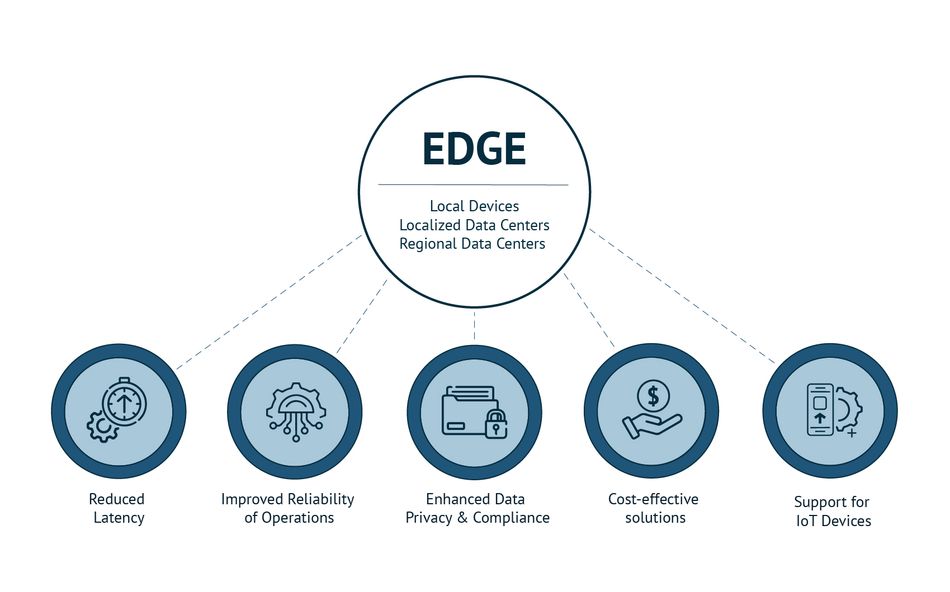
Generative AI Integration with Edge Computing Infrastructure
Integrating generative AI with edge computing involves several practical challenges, particularly optimizing models on resource-constrained devices. Edge devices like IoT sensors and smartphones typically have limited computational power and memory compared to cloud servers. Therefore, deploying large generative models on these devices requires significant optimization of the models themselves.
Model Optimization Techniques
Techniques like model pruning, quantization, and knowledge distillation are essential to make AI models suitable for edge deployments.
Pruning involves reducing the complexity of a model by removing non-essential components, which helps decrease the computational load.
Quantization reduces the precision of the numbers used in models, lowering memory usage and processing requirements.
Knowledge distillation allows a smaller, more efficient model (a “student” model) to learn from a larger, more complex model (a “teacher” model), retaining performance while being optimized for edge devices.
These optimization strategies are crucial but come with trade-offs. For example, while pruning and quantization can reduce the size of a model, they can also affect its accuracy. Therefore, balancing the trade-offs between model size, accuracy, and computational efficiency becomes a significant challenge in deploying generative AI at the edge.

Generative AI is radically changing how we process, analyze, and utilize data, and edge computing is driving this transformation closer to devices and users. To explore this groundbreaking space, join us for The Rise of Generative AI at the Edge: From Data Centers to Devices webinar on Wednesday, January 15th.
Generative AI Deployment Strategies
Deploying generative AI models across a network of edge devices requires orchestration, machine learning operations (MLOps), and carefully planned strategies like model partitioning and federated learning to balance the computational load while ensuring real-time performance.
Model partitioning is a critical strategy that divides larger generative models into smaller sub-tasks distributed across multiple edge devices—whether for inference or early-stage data processing. In this way, partitioned models optimize resource usage across devices, enabling them to function efficiently even when faced with resource limitations. For example, in a multi-device network, the first layer of processing might occur on lower-capacity devices, while more capable edge servers handle more complex layers.
In addition to partitioning, federated learning has emerged as a vital strategy for collaborative model training across edge devices without the need to transfer raw data back to a central location. This decentralized approach to learning allows devices to train local models and share insights, thus enhancing data privacy and security while maintaining model accuracy. Federated learning is particularly effective in environments with multiple heterogeneous edge devices, enabling them to work together to improve model performance while mitigating the risks of cloud dependency.
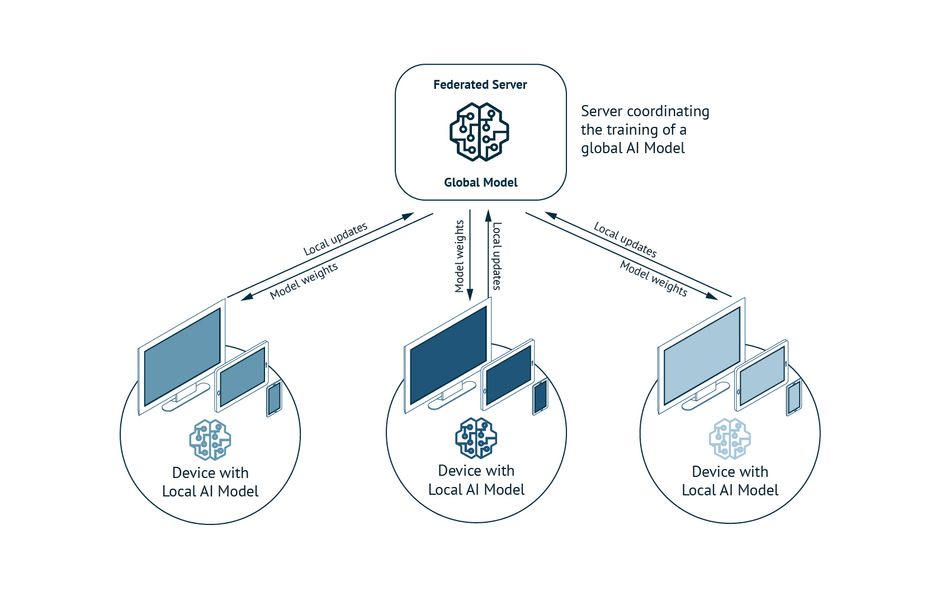
Another key strategy in managing this complex web of devices is orchestration, ensuring that tasks are assigned based on each device's computing power and real-time demands. Intelligent orchestration frameworks ensure that edge devices operate at optimal capacity without being overloaded or underutilized. In such deployments, tools like containerization—where AI workloads are wrapped in standardized packages for easy movement across devices—become essential, helping streamline the transition of tasks from cloud to edge. For instance, platforms like NVIDIA's EGX or Microsoft's AKS with Arc are advancing the orchestration of workloads across cloud-to-edge infrastructures, improving the efficiency of AI deployment.
MLOps further supports the lifecycle of AI models by managing their deployment, monitoring, and scaling across the edge-cloud continuum. As part of this system, AI-driven orchestration tools help ensure that model updates, scaling, and retraining occur seamlessly, which is critical as edge deployments scale in complexity.
Combining model partitioning, federated learning, and orchestration with MLOps solutions ensures that AI workloads remain adaptable to the unique requirements of each edge device while maximizing performance across the network. By implementing these strategies, companies can effectively manage the challenges of deploying large generative AI models at the edge, ensuring scalability, efficiency, and privacy.
How Particle is Transforming AI Deployment at the EdgeThe shift to edge computing is driven by the need for low-latency processing, enhanced privacy, and reduced cloud reliance. Particle’s Tachyon single-board computer makes it possible to perform complex AI workloads at the edge, enabling applications to run advanced models locally without cloud dependencies. This brings significant improvements in speed, privacy, and autonomy to industries relying on real-time decision-making. With 12 TOPS of NPU performance and an eight-core CPU, Tachyon is purpose-built to support demanding AI models, including transformers and GANs, right at the edge. This capability powers a wide range of applications—from adaptive retail displays and autonomous robots to generative design tools—where instant, intelligent responses are essential. Tachyon’s AI Capabilities: Seamless Performance at the EdgeTachyon integrates high-performance AI acceleration with next-generation connectivity to meet the growing demand for edge intelligence. Its 12 TOPS NPU performs real-time tasks like object detection, predictive maintenance, and advanced anomaly detection directly on the device, reducing reliance on the cloud. Connectivity with 5G and Wi-Fi 6E ensures that applications such as drones and collaborative robots can operate without interruption, even in challenging environments. For use cases in manufacturing, delivery, and energy, Tachyon’s ability to process data locally keeps systems running smoothly—whether connected or offline. Its modular Raspberry Pi-based form factor offers flexibility for developers to build custom edge solutions. This versatility enables applications like autonomous delivery robots, industrial sensors, or remote oil rig monitors, all designed with real-time data processing and minimal latency in mind. From Prototype to Production: Streamlining AI DevelopmentParticle’s ecosystem accelerates the development of AI-driven IoT solutions by enabling rapid prototyping and production. Developers can quickly test AI models, iterate algorithms in real-world conditions, and deploy them seamlessly. Tachyon’s over-the-air (OTA) updates allow ongoing model refinement and algorithm updates, ensuring solutions stay relevant and effective long after deployment. Remote troubleshooting tools reduce downtime and maintenance costs, allowing teams to resolve issues instantly from anywhere. By simplifying infrastructure requirements and supporting a faster time-to-market, Tachyon helps developers turn ideas into reality in weeks instead of months—essential in today’s fast-moving industries. Use Cases: Real-World Impact with TachyonTachyon is already making a difference across multiple industries:
These real-world applications demonstrate how Tachyon brings intelligence and reliability to the edge, meeting the needs of businesses across industries. Open Standards for Faster InnovationParticle embraces open-source development to foster innovation and collaboration in the AI community. With support for popular frameworks like TensorFlow Lite and Hugging Face, Tachyon provides a familiar environment for developers to build, customize, and deploy edge AI solutions quickly. By aligning with open standards, Particle ensures developers can leverage community-driven frameworks to reduce time-to-market and avoid vendor lock-in. This approach accelerates development and creates a transparent, collaborative ecosystem where custom AI models can thrive. The Future of Edge AI: Multimodal Intelligence and Privacy by DesignThe future of Tachyon lies in supporting multimodal AI models that can process visual and language data. Picture drones that analyze environments and communicate observations verbally or robots that detect defects and explain them to operators through speech and images. Looking ahead, federated learning will further enhance Tachyon’s value by allowing AI models to learn locally on devices and share improvements across a distributed network, preserving privacy while boosting performance. With 5G connectivity driving fast, secure data exchange, Tachyon is poised to meet the demands of next-generation autonomous systems, ensuring businesses remain at the forefront of edge innovation. |

Industry Perspectives on Edge Deployment
Several industry trends drive the convergence of edge computing and generative AI, including the need for real-time processing, improved privacy, and reduced operational costs. Yet, implementing generative AI at the edge introduces challenges that require strategic solutions.
In healthcare, generative AI at the edge is transforming patient data analysis, particularly in medical imaging. By running generative models on edge devices, healthcare providers can analyze medical images in real time, offering immediate, personalized diagnostic insights without relying on constant cloud connectivity. This significantly reduces latency, improves response time, and enhances privacy by keeping sensitive patient data locally, away from centralized servers.
In manufacturing and industrial IoT, generative AI models deployed on edge devices enable real-time anomaly detection and predictive maintenance, improving productivity by anticipating equipment failures and optimizing operations. These models also leverage synthetic data to simulate equipment behaviors and rare failures, enhancing their training without relying heavily on real-world data. However, the challenge lies in deploying generative models that are efficient enough for resource-constrained devices while being robust enough to operate in harsh industrial environments. Balancing model complexity with edge-device limitations remains crucial.
Telecommunications is another sector where generative AI at the edge holds promise, especially with the rollout of 5G. Low-latency 5G networks can power advanced generative applications like real-time language translation or augmented reality. However, integrating generative AI into 5G infrastructure demands substantial technological investment and new frameworks to address the privacy and security implications of handling vast amounts of data at the edge.
This convergence of generative AI and edge computing is reshaping industries, but its success depends on overcoming challenges related to resource constraints, security, and robust edge deployments.
Distinguishing Training and Reinforcement Learning from Inferencing
A critical aspect of deploying generative AI at the edge is understanding the difference between training, reinforcement learning, and inferencing. Training and reinforcement learning are computationally intensive processes typically performed in cloud or centralized data centers, where vast amounts of data and processing power are available. These processes involve iteratively improving the AI model by exposing it to new data or by allowing it to learn from interactions in simulated environments.
On the other hand, inferencing—the process of applying a trained model to new data to generate predictions or actions—is where edge devices truly shine. By performing inferencing at the edge, AI applications can deliver real-time results without the delays associated with cloud processing. This is crucial for applications like autonomous driving or real-time video analytics, where even a slight delay could have significant consequences. Thus, the role of edge devices in generative AI is primarily focused on inferencing, ensuring that AI-driven insights are delivered swiftly and securely at the point of need.
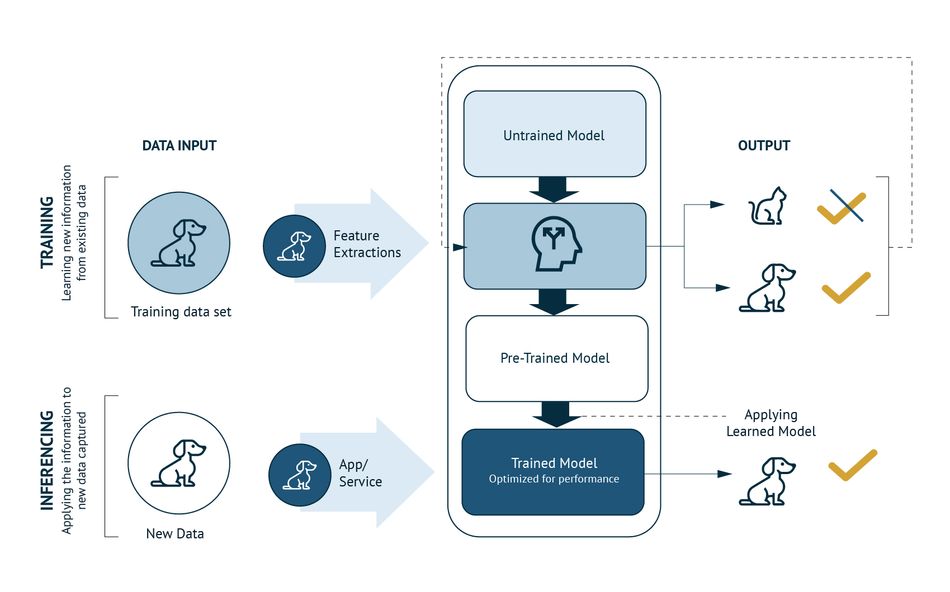
Challenges in Generative AI Deployment
While the benefits of edge computing for generative AI are clear—ranging from reduced latency to enhanced privacy—the industry still faces critical challenges, with model reliability and performance consistency standing out. In sectors such as manufacturing, healthcare, and autonomous systems, real-time accuracy is non-negotiable, making the degradation of AI models over time a significant concern. Without regular updates and retraining on fresh data, models can lose accuracy, leading to poor decision-making—something that can result in costly errors or safety risks. This is particularly important for industrial IoT applications where downtime or faulty predictions can disrupt entire production lines.
Furthermore, managing a distributed network of edge devices adds layers of complexity. Each device must maintain synchronization, receive updates, and continue operating efficiently despite limited computational power and memory. For businesses, ensuring these devices function seamlessly across different locations and environments is critical to successfully scaling generative AI.
Addressing these challenges will require developing new tools and techniques that can automate updates, streamline device management, and ensure models remain accurate over time. As industries increasingly rely on AI at the edge, understanding these complexities is essential for achieving long-term operational success and reliability.
Read an excerpt from the report's chapters here:
Introduction Chapter
Chapter 1

Generative AI and edge computing are transforming industries by enabling low-latency, real-time AI on edge devices, allowing efficient, private, and personalized applications without reliance on data centers.
Chapter 3
Chapter 4


Sponsored this article
About Particle
Particle is the leading application infrastructure for intelligent devices, helping thousands of companies bring intelligence to the edge. Particle provides everything you need to deploy software and...
16 Posts

Sponsored this article
About Syntiant
Syntiant’s ultra-low-power, high performance, deep neural network processors are making AI at the edge possible. Founded in 2017 and led by a veteran management team of accomplished tech executives,...
12 Posts

Sponsored this article
About Edge Impulse
Edge Impulse offers the latest machine learning tooling, enabling all enterprises to build smarter edge products. Our technology empowers developers to bring more AI products to market faster and...
17 Posts