In Memory Compute: Transforming Data Processing for Speed and Scalability
This article is a detailed analysis of In-Memory Compute technology, covering its architecture, use cases, recent advancements, and practical implementation strategies to enhance computational efficiency.

15 Jan, 2025. 13 minutes read

Random Access Memory (RAM) strip inserted into the Motherboard
Introduction
In-Memory Compute is revolutionizing data processing by moving data from slower storage devices like disks into the much faster main memory (RAM) for processing. This paradigm shift offers significant advantages in terms of speed and scalability. By eliminating the I/O bottleneck associated with disk access, In-Memory Compute enables applications to execute queries and perform complex computations at lightning speeds. This is crucial for real-time analytics, high-frequency trading, and other applications where rapid data processing is paramount.
Furthermore, In-Memory Compute can handle massive datasets that would overwhelm traditional disk-based systems. This paves the way for advanced analytics and machine learning models that require the processing of large volumes of data in real-time. Resultantly, In-Memory Computing is rapidly gaining traction across various industries, transforming how businesses analyze data and make critical decisions.
Understanding In-Memory Compute
What Is In-Memory Compute?
In-memory compute, or IMC refers to a computational model where data is processed directly in the memory of the system, rather than being read from or written to disk-based storage systems. [1] This processing-in-memory model eliminates the need for data to traverse from slow disk storage to RAM, thereby dramatically reducing latency and enhancing throughput. By prioritizing speed, in-memory compute bridges the gap between growing data volumes and the need for real-time insights.
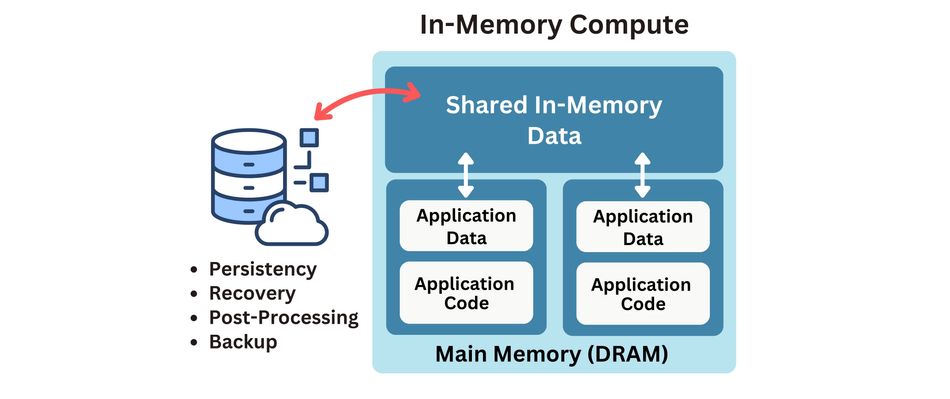
Real-world applications include:
Financial Services leveraging IMC for real-time risk assessments and fraud detection by analyzing vast volumes of transactions instantaneously.
E-commerce Platforms utilise sophisticated machine learning algorithms on in-memory data to enhance recommendation engines, thereby personalizing shopping experiences and increasing customer engagement.
Healthcare Systems employ IMC to process extensive patient data in real time, supporting diagnostics, early intervention, and personalized medicine strategies.
Manufacturing Sectors integrate in-memory compute to enhance efficiency on production lines. By analyzing sensor data in real-time, they can identify and rectify potential issues swiftly, ensuring minimal downtime and maximizing productivity.
Key features include:
Extremely low latency, enabling faster processing and quicker response times essential for time-sensitive applications.
Enhanced real-time analytics capabilities that support immediate decision-making and continuous data analysis are critical for sectors like finance and healthcare.
High scalability and the ability to handle exponentially growing datasets efficiently, without the performance trade-offs typically associated with scaling traditional disk-based systems.
Seamless integration with modern computing architectures, including distributed systems and cloud environments. This facilitates easy scaling across various platforms and significantly improves data centre energy efficiency.
Furthermore, the adaptability of in-memory computing allows it to support diverse workloads from simple query processing to complex artificial intelligence (AI) and deep learning tasks. By leveraging DRAM and potentially other memory technologies like SRAM or phase-change memory, in-memory computing systems can achieve throughput improvements orders of magnitude greater than conventional systems.

Similarly, the use of MRAM (Magnetoresistive Random Access Memory) and other innovative memory devices ensures faster access to stored data, enhancing overall system performance. IEEE standards play a pivotal role in guiding the development and interoperability of these technologies across various platforms, including those that incorporate GPUs for deep neural network processing. This facilitates the seamless interconnect between high-bandwidth components, ensuring that data throughput meets the demands of complex applications such as real-time analytics and AI activations.
How Does It Work?
The core principle of in-memory compute is to keep all active data within the RAM to ensure immediate availability for processing. Traditional computing systems often rely on data being stored on external storage solutions, which can create a bottleneck due to slower data access speeds. In contrast, IMC utilizes high-speed RAM, enabling faster data throughput and minimizing response times, which is critical for real-time processing and analytics. [2] This way, systems can perform operations such as querying, sorting, and analytics with unprecedented efficiency.
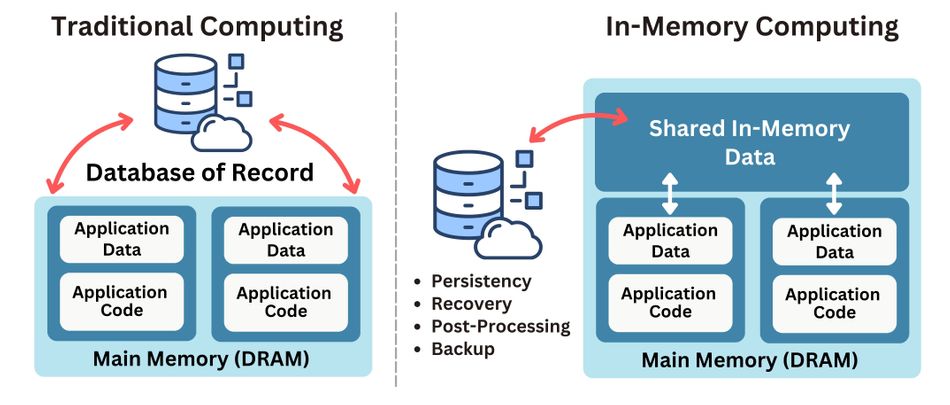
Below is a simplified overview of the data flow in an in-memory compute system:
| Feature | In-Memory Compute | Traditional Compute |
| Data Access Speed | Microseconds | Milliseconds |
| Storage Medium | RAM | Hard Disk/SSD |
| Scalability | High | Moderate |
| Use Cases | Real-Time Analytics | Batch Processing |
Here’s a detailed explanation of the features:
Data Access Speed: IMC systems can access data in microseconds, which is a significant improvement over the milliseconds it typically takes for traditional systems to access data from a hard disk or SSD. This speed enhancement is due to the direct path from RAM to CPU, eliminating any need for mechanical movement or electronic seeking associated with traditional storage.
Storage Medium: The primary storage medium in IMC is volatile RAM, which, while faster, requires a continuous power supply to maintain data integrity. Traditional systems use non-volatile storage solutions like hard disks or SSDs, which retain data without power but are slower in terms of access and write speeds.
Scalability: In-memory computing offers superior scalability compared to traditional computing due to its ability to increase node sizes and scale horizontally across distributed systems. This is particularly beneficial for expanding datasets and growing analytical demands.
Use Cases: The near-instantaneous access speed of IMC makes it ideal for real-time analytics, complex event processing, and dynamic decision-making environments. In contrast, traditional computing systems are better suited for batch processing tasks, where data is processed in large blocks at scheduled times, and immediate data retrieval is less critical.
By transitioning to in-memory computing, businesses and technology infrastructures can enhance their operational efficiency, and improve real-time decision-making capabilities. They can better manage the challenges associated with big data and complex algorithms.
Recommended Reading: Big Data: The 3 V's of Data
Key Benefits of In-Memory Compute
Speed and Performance
In-memory compute dramatically enhances the speed and performance of data processing tasks by sidestepping the latency that plagues disk-based storage systems. By keeping data directly in RAM, it facilitates rapid operations across querying, analytics, and transaction processing, delivering outputs in microseconds. RAM is roughly 5,000 times faster than a traditional spinning disk. [3] This capacity for high-speed computation is essential for handling complex operations swiftly and efficiently.

Performance Metrics:
Latency Reduction: In-memory compute can reduce latency by up to 90% compared to traditional disk-based systems, making it exceptionally responsive.
Throughput Increase: It achieves a throughput increase of up to 5x, particularly beneficial for applications with real-time data workloads that demand quick processing and analysis.
Benchmarks:
Data Processing Speeds: In-memory systems can reach data processing speeds of up to 100 GB/s, depending on the optimization of the hardware and software environments.
Average Query Execution Time: This has been dramatically reduced from several seconds to mere milliseconds, enhancing efficiency and user experience.
The integration of semiconductor technologies, including advanced transistors and CMOS elements, is crucial for handling the massive amount of data processed. These systems often utilize neuromorphic and near-memory computing approaches to optimize data movement and minimize latency. By utilizing analog computing principles in conjunction with digital techniques, such systems achieve greater energy efficiency and low power consumption.
The implementation of in-memory compute transforms traditional business operations by enabling faster decision-making, reducing operational delays, and supporting advanced data-driven strategies. This technology not only speeds up data handling but also improves the overall agility of businesses operating in dynamic and competitive environments.
Scalability for Large-Scale Applications
In-memory compute supports scalability by providing systems with the ability to process increasing volumes of data without compromising speed or efficiency. This is achieved through dynamic resource allocation and parallel data processing capabilities, which ensure consistent and high performance under heavy workloads.

Steps to Scale In-Memory Compute Systems:
Identify and Segment Workloads: Effective scalability starts with categorizing and distributing data across multiple memory nodes. This segmentation helps in managing data more efficiently and ensures balanced resource utilization.
Implement Distributed Computing Frameworks: By utilizing frameworks capable of parallel processing, in-memory compute systems can handle multiple operations simultaneously across different nodes, enhancing processing power and speed.
Utilize Elastic Memory Pools: These pools adjust dynamically, scaling up or down based on real-time data demands. This flexibility is crucial for handling data spikes without the need for constant manual intervention.
Monitor and Optimize System Performance: Continuous analysis of workload and system performance allows for timely optimizations and adjustments, ensuring the system remains efficient as demands evolve.
Examples from Industry Leaders:
Technology Giants: Companies like Google and Facebook employ in-memory computing to efficiently scale their massive real-time analytics operations. This technology underpins their search engines and social media platforms, managing billions of interactions with minimal latency.
Financial Firms: In the finance sector, in-memory compute is instrumental in risk modeling and high-frequency trading, where millions of transactions and data points are processed in mere seconds. This capability allows firms to adapt to market changes almost instantaneously.
Logistics Providers: For logistics companies, in-memory compute facilitates enhanced route optimization and fleet management. By processing large datasets quickly, these firms can reduce delivery times and operational costs, optimizing logistics on a large scale.
In-Memory Compute breaks away from the traditional von Neumann architecture, where data is constantly moved between the processor and separate memory. Integrating computation directly within the memory cells themselves eliminates the on-chip data movement bottleneck.
The scalability of in-memory compute systems makes them an indispensable technology for modern enterprises that require robust data processing capabilities to maintain competitive advantage. This technology supports a range of applications from internet-based services to critical financial operations, providing the backbone for dynamic and data-intensive business environments.
Recommended Reading: What is an Edge Data Center: A Comprehensive Guide for Engineering Professionals
Practical Applications of In-Memory Compute
Real-Time Analytics
In-memory compute enables real-time data analysis by processing massive datasets in milliseconds, allowing organizations to gain immediate insights and make data-driven decisions. This capability is crucial for time-sensitive operations where delays can impact outcomes. [4]

Example Scenario: A retail company is using in-memory computing to enhance inventory management effectively during high-traffic sales events, such as flash sales. This application showcases the ability of in-memory systems to handle and analyze real-time data, ensuring optimal stock levels and customer satisfaction.
Workflow Breakdown:
Real-Time Data Streaming: Data from various sales channels is continuously streamed to the in-memory system, ensuring that all information is current and immediately available for analysis.
Pattern Analysis: The system utilizes advanced algorithms to analyze purchasing patterns and predict which items will be in high demand, enabling proactive inventory adjustments.
Instant Insight Sharing: Insights derived from data analytics are instantly communicated to inventory management systems, allowing for real-time adjustments in stock levels across multiple store locations.
Visualization of Customer Demands: Trends in customer demand are visualized and analyzed, providing valuable insights that guide marketing strategies and future promotions.
Industries Benefiting Most:
Finance: In-memory compute is crucial for finance-related applications such as real-time fraud detection, high-frequency algorithmic trading, and dynamic portfolio optimization. By processing transactions and data instantaneously, financial institutions can mitigate risks and capitalize on market opportunities as they arise.
Healthcare: This technology plays a critical role in healthcare by monitoring patient vitals in real-time, facilitating early intervention, and significantly speeding up the drug discovery process through rapid analysis of research data.
Retail: Retailers use in-memory computing to personalize customer interactions, manage dynamic pricing effectively, and forecast market trends with greater accuracy. This ensures that consumers receive tailored shopping experiences, while retailers maintain optimal inventory levels and pricing strategies.
In-memory compute transforms operational capabilities across these industries by providing the tools to manage data-intensive applications efficiently and effectively. The immediate processing of large-scale data not only supports better business decisions but also enhances the overall responsiveness of services to consumer and market demands.
Enhancing Machine Learning Workflows
In-memory compute significantly enhances machine learning (ML) workflows by streamlining the data preprocessing, model training, and inference stages. This technology enables faster access to vast datasets and minimizes the bottlenecks typically encountered in disk-based storage, thereby optimizing the overall performance of ML pipelines.
Comparison of Processes with and without In-Memory Compute:
| Process | With In-Memory Compute | Without In-Memory Compute |
| Data Preprocessing | Seconds | Minutes |
| Model Training | Hours | Days |
| Inference Latency | Milliseconds | Seconds |
Recommendations for Integration:
Leverage In-Memory Data Grids: Utilize in-memory data grids to store and manage feature datasets used in training models. These grids offer low-latency access and high throughput, essential for handling large volumes of data during the training phase.
Use Distributed In-Memory Systems: Implement distributed in-memory systems to facilitate parallel processing of large datasets. This approach not only speeds up computations but also allows for scaling as data volumes and processing needs grow.
Optimize Hyperparameter Tuning: Enhance the efficiency of hyperparameter tuning by caching intermediate results in memory. This reduces redundant computations and speeds up the process of finding the best model parameters.
Implement Scalable Pipelines: Develop scalable ML pipelines that can dynamically adjust to increasing data volumes and evolving model complexities. In-memory compute helps in maintaining performance without compromising on the speed or accuracy of the models as they scale.
Benefits of Machine Learning:
Speed: In-memory compute reduces the time required for data preprocessing and model training from days to hours, or even minutes, thereby enabling more iterative and experimental approaches to model development.
Efficiency: By minimizing the data retrieval times and streamlining the entire ML workflow, in-memory compute allows for more complex and computationally intensive models to be trained faster.
Scalability: With the ability to handle growing datasets efficiently, in-memory compute systems ensure that ML models can be scaled without significant increases in cost or decreases in performance.
These integration strategies and benefits underscore the transformative impact of in-memory compute on machine learning. This makes it a critical technology for businesses looking to leverage AI and ML for competitive advantage.
Recommended Reading: Reality AI: A Game Changer in Sensor Data Analysis
Challenges and Limitations
Memory Constraints and Cost
While in-memory compute offers significant advantages, it also comes with inherent challenges and limitations that organizations need to consider. Two primary concerns are the memory constraints and the associated costs. [5]

In-memory compute systems require high-capacity RAM to function effectively, which can be a major cost factor, particularly as data volumes scale. The need for extensive RAM capacity increases not only the initial investment in hardware but also the ongoing costs related to energy consumption and system maintenance. As organizations demand more processing power and storage capacity, the financial burden can grow substantially.
Strategies for Optimization:
Use Compression Techniques
Implement data compression techniques to decrease the amount of memory required to store information. This approach helps in maintaining performance levels while reducing the overall memory footprint.
Implement Tiered Storage Systems
Develop a tiered storage strategy that uses in-memory processing for high-priority, time-sensitive data and cost-effective disk storage for less critical information. This hybrid approach balances cost and performance.
Optimize Data Models
Carefully design data models to minimize redundancy. Streamlining data structures and eliminating unnecessary data replication in memory can significantly reduce the required memory capacity.
Leverage Cloud-Based In-Memory Solutions
Consider cloud-based in-memory computing options that offer scalability and flexibility without the need for large upfront investments in physical infrastructure. Cloud providers often provide managed services that can scale dynamically based on demand, which can be more cost-effective and less resource-intensive for companies.
Further Challenges:
Scalability Limitations: Even though in-memory systems are scalable, physical limitations of server memory can pose challenges as data grows beyond the current capacity of the hardware.
Volatility: RAM is volatile, meaning data is lost when the power is turned off. This requires additional strategies to ensure data persistence, such as regular backups to non-volatile storage media.
Security Concerns: Storing sensitive data in memory can increase the risk of data breaches if proper security measures are not in place. Encryption and rigorous access controls are necessary to protect data.
By considering both the benefits and limitations of in-memory compute, organizations can better prepare for the demands of modern data processing. They can make informed decisions that align with their operational goals and budget constraints.
Implementation Complexity
Deploying in-memory compute systems involves addressing various technical and operational challenges, from infrastructure setup to software integration.

Best Practices for Overcoming Implementation Complexities:
Conduct a Thorough Workload Analysis:
Before implementation, perform a detailed analysis of existing workloads to identify which data and processes will benefit most from in-memory computing. This step helps prioritize efforts and resources, ensuring that the most critical applications are enhanced by the speed and efficiency of in-memory technology.
Choose Scalable In-Memory Platforms:
Opt for in-memory computing platforms that not only meet current needs but are also scalable. These platforms should support distributed architectures to facilitate growth and expansion without significant disruptions or performance degradations.
Ensure Compatibility with Existing Systems:
Integration testing is vital to ensure that the new in-memory systems will work seamlessly with existing databases, applications, and middleware. Comprehensive testing helps prevent potential conflicts and minimizes downtime during the transition.
Provide Training for Teams:
Investing in training for IT staff and relevant team members is essential. Proper training enables teams to manage and optimize in-memory environments effectively, which is crucial for maintaining system performance and reliability.
Establish Monitoring Frameworks:
Implement robust monitoring frameworks to continuously track system performance. These frameworks should be capable of identifying and alerting potential bottlenecks and performance issues, allowing for proactive management and optimization.
Additional Considerations:
Security Implementation: Given the sensitive nature of data stored in-memory, implementing advanced security measures to protect data integrity and prevent unauthorized access is imperative.
Data Persistence Strategies: Develop strategies to ensure data persistence, addressing the volatile nature of RAM. This may involve regular snapshots, backups, and integration with persistent storage solutions.
Cost Management: Monitor and manage costs associated with scaling in-memory systems, especially as data volumes grow. This includes not only hardware and software costs but also operational expenses like power consumption and cooling needs.
By adhering to these best practices, organizations can effectively navigate the complexities of implementing in-memory compute systems.
Recommended Reading: 2024 State of Edge AI Report
Conclusion
In-memory compute offers transformative potential by revolutionizing the speed and efficiency of data processing. By leveraging RAM for data storage and operations, organizations can achieve real-time analytics, reduce latency, and unlock opportunities across various industries. For businesses considering its implementation, focusing on scalability, infrastructure optimization, and team training are key steps to maximize its benefits. The ability to process data instantly opens doors to innovation, from enhancing customer experiences to optimizing operational efficiencies.
FAQs
Q. What Are the Key Differences Between In-Memory Compute and Traditional Computing?
A. Below are the key differences:
In-memory compute processes data directly in Random Access Memory, while traditional computing relies on disk storage.
It delivers microsecond-level data access compared to millisecond-level in traditional methods.
In-memory systems support real-time analytics, whereas traditional systems are better suited for batch processing.
Q. Is In-Memory Compute Suitable for Small Businesses?
A. Below are the key considerations:
In-memory compute can be cost-effective for small organizations when applied to critical, high-speed workloads.
Scalability allows businesses to start with smaller implementations and expand as needed.
Cloud-based in-memory solutions offer flexible pricing and lower initial investment.
Smaller businesses benefit from streamlined analytics and faster decision-making capabilities without extensive infrastructure.
Q. How does in-memory computing enhance data analytics?
A. In-memory computing enhances data analytics by significantly reducing the time required to access and process data. This allows for real-time analysis, enabling organizations to generate insights and make data-driven decisions much faster than with traditional disk-based systems. The ability to analyze data on the fly improves the responsiveness and agility of businesses in dynamic environments.
References
[1] Super Micro. What Is In-Memory Computing? [Cited 2025 January 10] Available at: Link
[2] IBM. In-Memory Computing [Cited 2025 January 10] Available at: Link
[3] Grid Gain. Uses, Advantages, and Working Principles of In-Memory Computing [Cited 2025 January 10] Available at: Link
[4] ARXIV. Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference [Cited 2025 January 10] Available at: Link
[5] Science Direct. Efficient and Lightweight In-Memory Computing Architecture for Hardware Security [Cited 2025 January 10] Available at: Link
Table of Contents
IntroductionUnderstanding In-Memory ComputeWhat Is In-Memory Compute?How Does It Work?Key Benefits of In-Memory ComputeSpeed and PerformanceScalability for Large-Scale ApplicationsPractical Applications of In-Memory ComputeReal-Time AnalyticsEnhancing Machine Learning WorkflowsChallenges and LimitationsMemory Constraints and CostImplementation ComplexityConclusionFAQsReferences