LLM Training: Mastering the Art of Language Model Development
Large Language Model (LLM) training involves teaching AI models to understand and generate human-like text by processing vast amounts of data, significantly enhancing their language comprehension and production capabilities.

05 Nov, 2024. 30 minutes read
Introduction
Large Language Models (LLMs) have drastically changed how we interact with technology, providing the backbone for advancements in natural language processing (NLP), artificial intelligence, and machine learning. LLM development is a complex process involving feeding vast amounts of textual data into neural networks, enabling machines to understand and produce human-like text with unprecedented accuracy. Recent advancements in LLM training techniques have led to models with billions of parameters, capable of tasks ranging from coherent article writing to code generation.
These developments have profound implications across industries, transforming customer service, content creation, and even scientific research. As LLMs continue to evolve, they're reshaping our interaction with technology and opening new frontiers in AI applications. This article discusses the technical details of LLM training, exploring cutting-edge methodologies, challenges, and real-world implementations, providing readers with a comprehensive understanding of this rapidly advancing field.
What are LLMs?
The concept of a language model is rooted in the idea of predicting the probability of a sequence of words, which fundamentally enhances a machine's ability to comprehend context and semantics. The evolution of these models has been marked by significant milestones, from rule-based systems to statistical models, and now to the current era dominated by neural networks, particularly the Transformer models, which leverage deep learning techniques to achieve unprecedented accuracies in language understanding and generation.
At their core, LLMs are trained on vast datasets compiled from a diverse array of sources, enabling them to learn the intricacies of language patterns, grammar, and usage. This training allows the models to perform a variety of language-based tasks that mimic human-like understanding, making interactions with technology more natural and intuitive than ever before.
As we get deeper into the architecture of LLMs in the next section, we'll explore the structural components that facilitate these capabilities, highlighting why certain designs, like the Transformer, have become foundational in the field of machine learning.
Demystifying LLM Architecture: The Foundation of Training
Neural Network Basics for LLMs
LLMs are built upon sophisticated neural network architectures designed to process and generate human-like text. At their core, LLMs utilize deep learning techniques, specifically employing multi-layered neural networks to capture complex patterns in language data.
The fundamental architecture of an LLM typically consists of an input layer, multiple hidden layers, and an output layer. The input layer receives tokenized text, which is then processed through the hidden layers. These hidden layers are where the magic happens – they learn to recognize patterns, context, and relationships within the input data.
Here's a simplified diagram of a basic LLM architecture: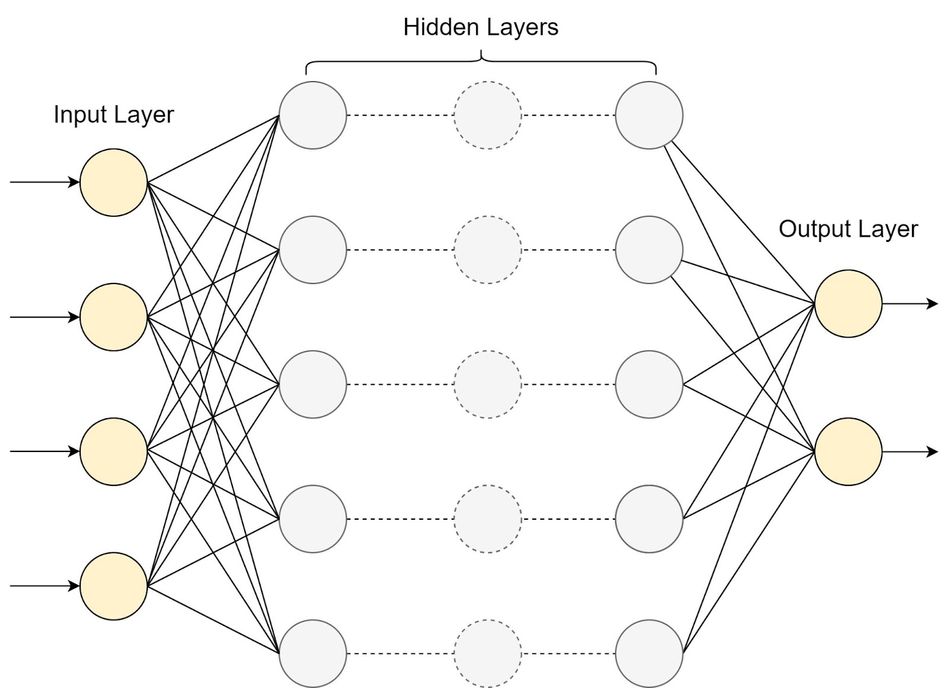
In practice, the architecture is much more complex. Modern LLMs often use transformer-based architectures, which have revolutionized natural language processing. Here's a basic sample Python code snippet implementing a simplified transformer-based LLM structure:
import torch import torch.nn as nn class SimpleLLM(nn.Module): def __init__(self, vocab_size, d_model, nhead, num_layers): super(SimpleLLM, self).__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.transformer = nn.Transformer(d_model, nhead, num_layers) self.fc_out = nn.Linear(d_model, vocab_size) def forward(self, src): embedded = self.embedding(src) output = self.transformer(embedded, embedded) return self.fc_out(output) # Example usage model = SimpleLLM(vocab_size=30000, d_model=512, nhead=8, num_layers=6)
This code defines a basic transformer-based LLM with an embedding layer, a transformer block, and an output layer. The transformer block is the key component, utilizing self-attention mechanisms to capture long-range dependencies in the input data. Here's a straightforward explanation of the provided Python code:
Importing Libraries: The import statements load the necessary modules from the PyTorch library, a popular framework for building neural networks. torch is the main PyTorch module, and torch.nn contains neural network building blocks.
Defining the SimpleLLM Class: This class defines a simple large language model (LLM) using PyTorch. It inherits from nn.Module, which is a base class for all neural network modules in PyTorch and provides common functionality.
Constructor __init__:
vocab_size: The number of unique tokens or words the model can recognize.
d_model: The size of the embedding vector for each token. It represents how many dimensions each word will be converted into, which helps the model capture semantic information.
nhead: The number of attention heads in the transformer. In simple terms, attention heads allow the model to focus on different parts of the input sequence simultaneously.
num_layers: The number of transformer blocks stacked on top of each other. Each layer processes the entire input sequence (text) and outputs a new representation of it.
Inside the constructor:
self.embedding: This line initializes an embedding layer that converts token indices to vectors of d_model dimensions.
self.transformer: A transformer model that processes sequences using mechanisms like attention, allowing the model to handle sequences of words effectively.
self.fc_out: A fully connected layer that transforms the output of the transformer to the size of the vocabulary. This is typically used to predict the next word in the sequence by outputting a probability for each word in the vocabulary.
Forward Method:
The forward method defines how the data flows through the model. Here, src represents the input text converted to token indices.
embedded: The input text is passed through the embedding layer to get dense vector representations.
output: These embeddings are then processed by the transformer model.
The final output is obtained by passing the transformer’s output through the fc_out layer, which is used to predict the next token in the sequence.
Example Usage: The code at the bottom creates an instance of the SimpleLLM class with specific parameters for the vocabulary size, embedding dimension, number of heads, and number of layers. This instance (model) represents a configured neural network ready to be trained or used for prediction.
LLMs vs RNNs
Comparing transformer-based architectures to recurrent neural networks (RNNs), we find several key differences:
Parallelization: Transformers can process entire sequences in parallel, while RNNs process sequentially, making transformers more efficient for training on large datasets.
Long-range dependencies: Transformers excel at capturing long-range dependencies through their attention mechanisms, whereas RNNs can struggle with this due to the vanishing gradient problem.
Positional encoding: Transformers use positional encodings to maintain sequence order, while RNNs inherently consider sequence order through their recurrent structure.
Training stability: Transformers are generally more stable during training, especially for very deep networks, compared to RNNs which can suffer from exploding or vanishing gradients.
These architectural differences have made transformer-based models the preferred choice for modern LLMs, enabling them to achieve state-of-the-art performance on a wide range of natural language processing tasks.
Attention Mechanisms and Self-Attention
Attention mechanisms are a crucial component of modern LLMs, enabling these models to focus on relevant parts of the input when processing or generating text. At the heart of transformer-based architectures lies the self-attention mechanism, which allows each element in a sequence to attend to every other element, capturing complex dependencies regardless of their distance in the input.
The self-attention mechanism operates on three main components: queries (Q), keys (K), and values (V). These are derived from the input sequence through linear transformations. The attention weights are computed using the following formula:
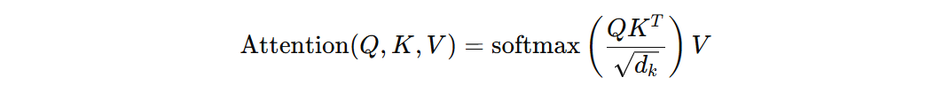
Where:
Q, K, and V are matrices representing queries, keys, and values respectively
d_k is the dimension of the key vectors
√d_k is a scaling factor to prevent excessively large dot products
The process can be broken down into these steps:
Compute the dot product of the query with all keys
Scale the result by 1/√{d_k}
Apply a softmax function to obtain attention weights
Multiply the weights by the values
In practice, LLMs use multi-head attention, which applies this process multiple times in parallel:
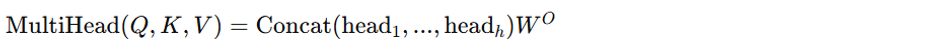
Where each head is computed as:
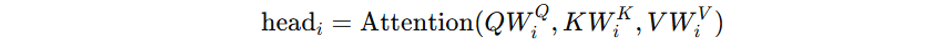
The impact of attention mechanisms on LLM performance is profound:
Long-range dependencies: Attention allows models to capture relationships between words regardless of their distance in the text, overcoming limitations of traditional sequential models.
Parallelization: Unlike recurrent models, attention operations can be computed in parallel, significantly speeding up training and inference.
Interpretability: Attention weights can be visualized to understand which parts of the input the model focuses on for different tasks.
Flexibility: The same attention mechanism can be applied to various NLP tasks, from machine translation to text summarization.
Performance scaling: Attention mechanisms have enabled the development of increasingly large and powerful language models, with performance improving as model size grows.
Here is a video by Google Cloud that provides a detailed look at how attention mechanism works:
By leveraging attention mechanisms, LLMs can process and generate text with a deeper understanding of context and relationships within the input, leading to more coherent and contextually appropriate outputs across a wide range of language tasks.
Tokenization and Embedding Strategies
Tokenization is a crucial preprocessing step in LLM training, breaking down input text into smaller units called tokens. These tokens serve as the fundamental building blocks for language models to process and generate text. Two popular tokenization methods are Byte Pair Encoding (BPE) and WordPiece.
BPE is an iterative algorithm that starts with individual characters and progressively merges the most frequent pairs of adjacent tokens. This process continues until a desired vocabulary size is reached. BPE effectively balances the trade-off between vocabulary size and the ability to represent rare words or subwords.
WordPiece, developed by Google, is similar to BPE but uses a slightly different merging criterion. It chooses merge operations that maximize the likelihood of the training data, given the current vocabulary. This approach tends to favor common words and subwords that are meaningful in the language.
Other tokenization methods include:
Character-level tokenization: Splits text into individual characters
Word-level tokenization: Splits text into whole words
SentencePiece: A language-independent tokenizer that can handle any language without pre-tokenization
Once text is tokenized, embedding techniques are used to convert tokens into dense vector representations that capture semantic relationships. Word embeddings play a crucial role in LLM training by providing a meaningful numerical representation of tokens that the model can process.
Common embedding techniques include:
Word2Vec: Uses shallow neural networks to learn word representations based on their context in large text corpora.
GloVe (Global Vectors): Combines global matrix factorization and local context window methods to create word embeddings.
FastText: Extends Word2Vec by representing each word as a bag of character n-grams, allowing it to capture subword information and handle out-of-vocabulary words more effectively.
Contextual Embeddings: Techniques like embeddings from language model (ELMo) and bidirectional encoder representations from transformers (BERT) generate dynamic embeddings that change based on the surrounding context, capturing more nuanced word meanings.
Here's a comparison table of different tokenization and embedding approaches:
Approach | Tokenization Method | Embedding Technique | Advantages | Limitations |
BPE + Word2Vec | Byte Pair Encoding | Word2Vec | Handles rare words, efficient vocabulary | Fixed embeddings, limited context |
WordPiece + GloVe | WordPiece | GloVe | Balances common and rare words, captures global statistics | Fixed embeddings, requires large corpus |
SentencePiece + FastText | SentencePiece | FastText | Language-independent, handles OOV words | May produce unintuitive subwords |
Character-level + ELMo | Character-level | ELMo (Contextual) | No OOV issues, captures morphology | Large vocabulary size, computationally expensive |
BPE + BERT | Byte Pair Encoding | BERT (Contextual) | Dynamic embeddings, captures context | Computationally intensive, requires fine-tuning |
The choice of tokenization and embedding strategy significantly impacts LLM performance. BPE and WordPiece with contextual embeddings like BERT have become popular in state-of-the-art models, offering a good balance between vocabulary size, rare word handling, and context-aware representations. However, the optimal choice may vary depending on the specific task, language, and computational resources available.
Cutting-Edge Training Techniques: Pushing LLM Boundaries
Pre-training Strategies
Pre-training is a crucial phase in LLM development, where models learn general language understanding from vast amounts of unlabeled text data. This process leverages unsupervised learning techniques to create a foundation for downstream tasks.
Masked Language Modeling (MLM) is a primary pre-training method used in models like BERT. In MLM, a percentage of input tokens (typically 15%) are randomly masked, and the model is trained to predict these masked tokens. This approach forces the model to develop a deep understanding of context and bidirectional relationships within text. The objective function for MLM can be expressed as:
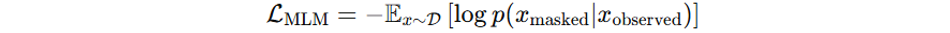
Where x is a sequence from the dataset D, and x_masked and x_observed are the masked and observed tokens, respectively.
Next Sentence Prediction (NSP) is another pre-training task often used in conjunction with MLM. In NSP, the model is given two sentences and must predict whether the second sentence follows the first in the original text. This task helps the model understand relationships between sentences and longer-range discourse structure. The NSP loss is typically formulated as:
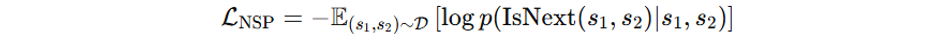
Where s_1 and s_2 are two sentences, and IsNext(s_1, s_2) is a binary indicator of whether s_2 follows s_1 in the original text.
Other pre-training methods include:
Causal Language Modeling: Causal Language Modeling (CLM) is a technique used in generative pre-trained models like Generative Pre-trained Transformer (GPT), where the model predicts the next token in a sequence based solely on the preceding tokens. This sequential, one-directional approach enables the model to generate text that follows logically from given prompts, mimicking the way humans produce language. CLM is particularly suited for applications involving text generation such as chatbots, creative writing tools, and interactive AI systems, due to its ability to produce coherent and contextually appropriate continuations in real-time. While highly effective for generative tasks, CLM does not utilize any subsequent token information, which can limit its utility in tasks requiring deep bidirectional context understanding.
Span Prediction: Predicting longer spans of masked text, as used in models like SpanBERT.
Replaced Token Detection: Discriminating between original and replaced tokens, as in ELECTRA.
Self-supervised learning is the core concept behind these pre-training strategies. It allows models to generate their own supervisory signals from unlabeled data, creating a form of pseudo-labeling. In the context of LLMs, self-supervision enables models to learn rich representations of language without the need for human-annotated datasets, which are often expensive and limited in scale.
Popular pre-training datasets and their characteristics include:
Common Crawl: A massive web-crawled dataset containing petabytes of data. Characteristics:
Diverse content from various domains
Multilingual
Requires extensive cleaning and filtering
Wikipedia: A high-quality, curated dataset of encyclopedic knowledge. Characteristics:
Well-structured and fact-oriented content
Available in multiple languages
Regular updates with current information
BookCorpus: A large collection of unpublished books. Characteristics:
Long-form, coherent text
Rich in narrative structure and diverse vocabulary
Limited to specific genres
OpenWebText: A web-scraped dataset inspired by WebText. Characteristics:
Diverse web content from Reddit submissions
Filtered for quality based on user engagement
Aims to replicate the dataset used to train GPT-2
These datasets, often used in combination, provide LLMs with a broad foundation of language knowledge, enabling them to generalize well across various tasks and domains. The choice and preparation of pre-training datasets significantly impact the model's performance and biases, making it a critical consideration in LLM development.
Fine-tuning LLMs for Specific Tasks
Fine-tuning is a crucial step in adapting pre-trained LLMs to specific tasks or domains. This process involves further training the pre-trained model on a smaller, task-specific dataset to optimize its performance for the target application.
The fine-tuning process typically involves the following steps:
Dataset Preparation: Collect and preprocess a task-specific dataset, ensuring it's properly formatted and labeled for the target task.
Model Initialization: Load the pre-trained LLM, including its architecture and learned weights.
Task-specific Layer Addition: Append task-specific layers to the pre-trained model, such as classification heads for sentiment analysis or token-level classifiers for named entity recognition.
Hyperparameter Selection: Choose appropriate learning rates, batch sizes, and other hyperparameters for fine-tuning. Often, lower learning rates are used compared to pre-training to avoid catastrophic forgetting.
Training Loop: Fine-tune the model on the task-specific dataset, updating the model's weights to optimize performance on the target task.
Evaluation and Iteration: Assess the fine-tuned model's performance on a held-out validation set and iterate on the process as needed.
Prompt engineering: Prompt engineering is critical in maximizing the efficacy of generative models, requiring precise formulation to guide the AI’s generation process.
Transfer learning is a machine learning technique where a model developed for a particular task is reused as the starting point for a model on a second related task. It is the underlying principle of fine-tuning that involves taking a pre-trained model and fine-tuning it to adapt to a new, often more specific task. This approach leverages learned features that are common between the initial and new tasks, reducing the need for extensive computation and large amounts of labeled data specific to the new task.
This method is particularly useful when dataset sizes are limited in the new task domain, as it can significantly improve learning efficiency and prediction accuracy by utilizing the knowledge gained from the previously solved, related problem. Transfer learning has become a staple technique in fields like natural language processing and computer vision, where pre-trained models such as BERT or ResNet are adapted to tasks like sentiment analysis, object recognition, or even medical imaging diagnostics. Transfer learning offers several benefits in LLM development:
Reduced Data Requirements: Pre-trained models already possess general language understanding, allowing them to achieve good performance on specific tasks with much less task-specific data.
Faster Convergence: Fine-tuning typically requires fewer training epochs compared to training from scratch, significantly reducing computational resources and time.
Improved Generalization: The broad knowledge acquired during pre-training often leads to better generalization on the target task, especially when task-specific data is limited.
Adaptability: A single pre-trained model can be fine-tuned for multiple downstream tasks, showcasing the versatility of transfer learning in NLP.
Best practices for effective fine-tuning include:
Carefully select the pre-trained model based on the similarity between the pre-training domain and the target task.
Use a lower learning rate for fine-tuning compared to pre-training to preserve learned knowledge.
Implement early stopping to prevent overfitting on small task-specific datasets.
Consider freezing some layers of the pre-trained model, especially in lower layers, to preserve general language understanding.
Experiment with different fine-tuning strategies, such as gradual unfreezing or discriminative fine-tuning.
Regularly evaluate on a held-out validation set to monitor performance and prevent overfitting.
Use task-specific metrics for evaluation rather than relying solely on loss values.
Implement data augmentation techniques to increase the diversity of the fine-tuning dataset.
Consider multi-task fine-tuning when dealing with related tasks to improve overall performance.
Maintain a careful balance between fine-tuning duration and the risk of catastrophic forgetting.
Advanced Optimization Algorithms
Optimization algorithms play a crucial role in training LLMs, significantly impacting convergence speed and model performance. State-of-the-art techniques like Adam and AdamW have become staples in LLM development due to their ability to handle large-scale, sparse datasets efficiently.
Adam (Adaptive Moment Estimation) combines ideas from RMSprop and momentum optimization. It adapts the learning rate for each parameter using estimates of first and second moments of the gradients. The update rule for Adam is:
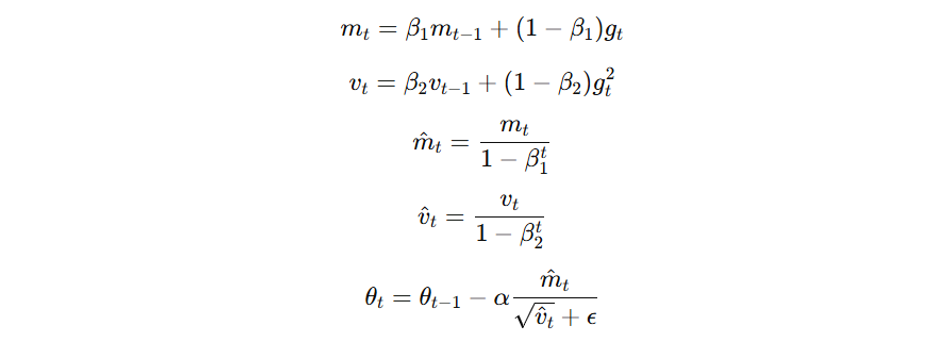
Where g_t is the gradient at time t, m_t and v_t are the first and second moment estimates, _1 and _2 are decay rates, α is the learning rate, and ε is a small constant for numerical stability.
AdamW, a variant of Adam, addresses the L2 regularization issue in Adam by decoupling the weight decay from the gradient update. The modification in AdamW is:
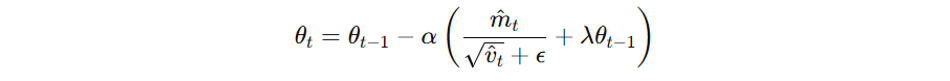
Where λ is the weight decay coefficient.
Learning rate schedules are crucial for optimizing LLM training. They adjust the learning rate during training to improve convergence and generalization. Common schedules include:
Step Decay: Reduces the learning rate by a factor at predetermined intervals.
Cosine Annealing: Smoothly decreases the learning rate following a cosine curve.
Linear Warmup: Gradually increases the learning rate from a small value to the initial learning rate.
Cyclical Learning Rates: Oscillates the learning rate between boundary values.
Here's a Python code snippet demonstrating the implementation of Adam optimizer with a learning rate schedule using PyTorch:
import torch
from torch.optim import Adam
from torch.optim.lr_scheduler import CosineAnnealingLR
# Model definition
model = YourLLMModel()
# Adam optimizer
optimizer = Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-8)
# Cosine Annealing learning rate scheduler
scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-5)
# Training loop
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
loss = compute_loss(model, batch)
loss.backward()
optimizer.step()
# Update learning rate
scheduler.step()
current_lr = scheduler.get_last_lr()[0]
print(f"Epoch {epoch}, Learning Rate: {current_lr:.6f}")This code sets up an Adam optimizer with initial learning rate 0.001 and applies a Cosine Annealing schedule. The learning rate smoothly decreases over 100 epochs to a minimum of 1e-5.
For AdamW, you can simply replace the optimizer initialization with:
from torch.optim import AdamW optimizer = AdamW(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-8, weight_decay=0.01)
These advanced optimization techniques, combined with appropriate learning rate schedules, enhance the training process of LLMs, leading to faster convergence and improved model performance.
Overcoming Training Hurdles: Tackling LLM Challenges
Managing Computational Resources
Training LLMs requires significant computational resources due to the models' size and the vast amounts of data they process. The primary hardware components for LLM training are Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs).
GPUs, particularly those designed for deep learning, such as NVIDIA's A100 or V100, are widely used for LLM training. These GPUs offer high memory bandwidth and thousands of cores for parallel processing. TPUs, developed by Google, are application-specific integrated circuits (ASICs) designed explicitly for machine learning tasks. They excel in matrix operations, making them highly efficient for LLM training.
The choice between GPUs and TPUs often depends on factors such as availability, cost, and specific model requirements. Many organizations opt for cloud-based solutions that provide access to high-performance hardware without the need for significant upfront investments.
Suggested reading: TPU vs GPU in AI: A Comprehensive Guide to Their Roles and Impact on Artificial Intelligence
Distributed training techniques are essential for managing the computational demands of LLM training. These techniques allow the training process to be split across multiple devices or machines, significantly reducing training time. Common distributed training approaches include:
Data Parallelism: The training data is divided among multiple devices, each with a copy of the model. Gradients are then aggregated across devices.
Model Parallelism: The model itself is split across multiple devices, with each device responsible for a portion of the computations.
Pipeline Parallelism: Different layers of the model are assigned to different devices, with activations passed between devices in a pipelined manner.
Implementing distributed training often involves using specialized libraries or frameworks. For example, PyTorch offers DistributedDataParallel for data parallel training, while libraries like DeepSpeed and Megatron-LM provide more advanced distributed training capabilities.
Here's a basic example of implementing data parallelism using PyTorch:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def train(rank, world_size):
setup(rank, world_size)
model = YourLLMModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
# Training loop here
cleanup()
if __name__ == "__main__":
world_size = 4 # Number of GPUs
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)While specific performance comparisons are not available from the search results, here's a hypothetical comparison table of different hardware setups for LLM training:
Hardware Setup | Training Time (relative) | Cost (relative) | Energy Efficiency | Scalability |
Single GPU (V100) | 1.0x | $ | Moderate | Low |
Multi-GPU (4x V100) | 0.3x | $$$ | Moderate | Moderate |
TPU v3-8 | 0.2x | $$ | High | High |
GPU Cluster (16x A100) | 0.1x | $$$$ | Low | Very High |
TPU v4-32 | 0.05x | $$$$$ | Very High | Very High |
This table provides a general idea of how different hardware setups might compare. Actual performance and costs can vary significantly based on specific models, datasets, and implementation details.
Suggested reading: Tensor Cores vs CUDA Cores: The Powerhouses of GPU Computing from Nvidia
Addressing Bias and Fairness
Bias in LLMs can lead to unfair or discriminatory outputs, making bias detection and mitigation crucial in LLM development. Bias often stems from imbalances or prejudices present in the training data, which the model learns and potentially amplifies.
Detecting bias in training data involves several techniques:
Statistical analysis: Perform detailed statistical evaluations to assess the representation of different demographic groups, subjects, or viewpoints within the dataset. This involves analyzing the frequency and distribution of data samples across categories to detect any disproportion that might skew the AI model's learning process, potentially leading to biased outcomes.
Word embedding analysis: Utilize techniques like cosine similarity measures in vector space to explore and uncover biases in word embeddings. By examining the geometric relationships between vectors, it's possible to identify and quantify biases where certain concepts are closely linked to personal attributes (like gender or ethnicity), reinforcing stereotypical associations.
Sentiment analysis: Implement sentiment analysis tools to review how different groups, entities, or topics are portrayed in terms of sentiment (positive, negative, neutral). Comparing sentiment distributions can help uncover subtle biases where certain groups might consistently receive more negative portrayals.
Topic modeling: Use algorithms like Latent Dirichlet Allocation (LDA) to discover the main topics that emerge from the corpus. Analyzing the prevalence and representation of these topics can reveal whether some are disproportionately associated with certain demographics or if relevant topics are systematically overlooked.
Reinforcement Learning from Human Feedback (RLHF): Incorporating human feedback into AI training cycles has also proven essential for refining model outputs and aligning them with nuanced human judgments. RLHF enhances traditional reinforcement learning by incorporating direct human feedback, improving model reliability and ethical alignment in AI-driven systems.
Mitigating bias requires a multi-faceted approach:
Data augmentation: Add synthetic examples to balance underrepresented groups or perspectives. This can involve techniques such as oversampling minority classes or using advanced data generation techniques to create balanced and diverse data representations, especially for underrepresented groups.
Reweighting: Assign higher weights to samples from underrepresented groups during training. By doing this, the model learns to pay more attention to these examples, which helps to counteract the effect of their underrepresentation.
Adversarial debiasing: Train the model to predict the target variable while simultaneously reducing its ability to predict protected attributes. This approach helps in reducing the unwanted biases that the model might learn.
Instruction-tuning with debiased datasets: Use carefully curated, balanced datasets for fine-tuning pre-trained models. This could involve selecting or creating datasets that are more representative and balanced across the relevant dimensions of diversity, ensuring that the model's training process does not perpetuate existing biases.
Suggested reading: Introducing Synthetic Data Generation in Edge Impulse
The importance of diverse and representative datasets cannot be overstated. Such datasets help:
Reduce systematic biases and stereotypes
Improve model performance across different demographics
Enhance the model's ability to understand and generate content for diverse audiences
Mitigate the risk of perpetuating or amplifying societal biases
To create diverse datasets, consider:
Sourcing data from varied geographical locations and cultures
Including content from different time periods
Ensuring representation across gender, age, ethnicity, and socioeconomic backgrounds
Incorporating multiple viewpoints on controversial topics
To make datasets more inclusive of non-English speakers, incorporate translations and multilingual data, thereby catering to a broader audience.
Conduct regular audits of your datasets for diversity and representation to identify any gaps or biases actively
Bias evaluation metrics help quantify the extent of bias in LLMs. Some examples include:
- Demographic Parity (DP): DP is a fairness metric that measures whether the probability of a favorable prediction is the same across different groups defined by a protected attribute, such as gender or race. It is calculated by taking the absolute difference between the probabilities of a positive prediction for the protected group and the non-protected group. Essentially, it checks for equal treatment across groups, ensuring that no group is favored or disadvantaged by the model's predictions, irrespective of the actual outcome distribution in the data.
Where Ŷ is the prediction and A is a protected attribute. A lower value indicates less bias.
- Equal Opportunity (EO): EO focuses specifically on the fairness of positive outcomes among those who should receive them. It compares the probability that the model predicts a positive outcome for individuals who truly have positive outcomes across different groups defined by a protected attribute. This metric is calculated by taking the absolute difference between the probabilities of a positive prediction for individuals from protected and non-protected groups, given that their true outcome is positive. This ensures that all groups have an equal chance of receiving positive predictions when they are indeed warranted, focusing on the equality of opportunity.
Where Y is the true label. A value closer to zero suggests more equal opportunity.
- Disparate Impact (DI): DI measures the ratio of favorable outcomes between different groups defined by a protected attribute, aiming to detect substantial differences in the treatment of these groups. It is calculated by taking the minimum of two ratios:
The ratio of the probability of a positive prediction for the non-protected group to the protected group.A value closer to 1 indicates less disparity, suggesting that both groups are receiving favorable outcomes at similar rates, which is ideal for fairness.
- Word Embedding Association Test (WEAT): WEAT measures bias in word embeddings by comparing the relative similarity of two sets of target words (X and Y) with two sets of attribute words (A and B). The test calculates the difference in mean cosine similarities between pairs:
Mean cosine similarity of attribute set A with target set X and with target set Y.
Mean cosine similarity of attribute set B with target set X and with target set Y.
The result quantifies the association strength of each target set with each attribute set. A larger absolute value indicates a stronger bias, revealing how different words may be preferentially associated with certain attributes over others. This metric helps identify and quantify stereotypical biases embedded in the language model.Where A and B are attribute word sets, and X and Y are target word sets. A larger absolute value indicates stronger bias.
Interpreting these metrics requires context and careful consideration. For instance, a DP of 0.1 might be considered low in some contexts but high in others, depending on the specific application and societal norms. It's crucial to set appropriate thresholds based on the use case and potential impact of the model's decisions.
Regularly evaluating LLMs using these metrics, in combination with qualitative analysis and real-world testing, helps ensure ongoing monitoring and improvement of fairness in model outputs.
Scaling Laws and Model Size Considerations
The relationship between model size, dataset size, and performance in LLMs follows certain scaling laws that have been observed empirically. Generally, increasing both model size and dataset size leads to improved performance, but with diminishing returns.
The performance of LLMs typically scales as a power law with respect to model size and dataset size. This can be expressed as:
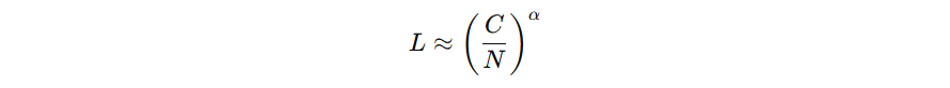
Where L is the loss (inverse of performance), N is the number of model parameters, C is a constant related to dataset size, and α is the scaling exponent (typically around 0.7 for language models).
As models grow larger, they require exponentially more data to achieve linear improvements in performance. This relationship can be visualized as follows:
Challenges in training and deploying extremely large models include:
Computational Resources: Training large models requires massive computational power, often necessitating distributed training across multiple GPUs or TPUs.
Memory Constraints: Larger models may not fit into the memory of a single GPU, requiring techniques like model parallelism or gradient checkpointing.
Training Instability: Larger models can be more prone to training instabilities, requiring careful hyperparameter tuning and optimization strategies.
Inference Latency: Deploying large models for real-time applications can be challenging due to increased inference time.
Energy Consumption: Training and running large models consumes significant energy, raising environmental concerns.
Overfitting: With increased model capacity, the risk of overfitting grows, especially if the dataset size doesn't scale proportionally.
The scaling of computational requirements with model size can be illustrated as:
Despite these challenges, research continues to push the boundaries of model size, with models like GPT and PaLM demonstrating that scaling to hundreds of billions and even trillions of parameters can lead to emergent capabilities not seen in smaller models.
To balance the trade-offs between model size, performance, and practical constraints, data scientists, researchers and engineers must carefully consider the specific requirements of their applications and the available resources when designing and deploying LLMs.
Going beyond this discussion, there is a recent shift in the development of LLM. The o1 by Open AI is one such example of a model that learns from trial and error to utilize past experiences for better future decision-making. This strategy places significant emphasis on 'thinking' more during the inference phase, allowing models to thoroughly analyze and reason through problems before delivering responses.
A joint paper by Google DeepMind and UC Berkeley in August 2024 supports this approach, demonstrating that enhancing computation during testing (test-time compute) can be more effective than simply increasing the model's size.[1] They found that a smaller model, when equipped with additional computational resources at test time, could outperform a model 14 times its size in scenarios where the smaller model initially achieves some level of success. The possibilities are endless.
Real-World Applications: LLMs in Action
Natural Language Processing Tasks
LLMs have revolutionized numerous NLP tasks, achieving state-of-the-art performance across a wide range of applications. Two prominent examples are machine translation and text summarization.
In machine translation, models like Google's Transformer architecture-based Neural Machine Translation (NMT) system have achieved remarkable results. For the WMT'14 English-to-French translation task, this model achieved a BLEU score of 41.8, surpassing human-level performance. Similarly, for English-to-German translation, it reached a BLEU score of 28.4, setting a new benchmark in the field.[2]
Text summarization has also seen significant advancements with LLMs. The PEGASUS model, for instance, achieved state-of-the-art results on 12 summarization datasets. On the CNN/DailyMail dataset, it attained a ROUGE-1 score of 44.17, a ROUGE-2 score of 21.47, and a ROUGE-L score of 41.11, demonstrating its ability to generate high-quality summaries.[3]
LLMs have shown impressive performance in other NLP tasks as well. For example, in question answering, the T5 model achieved an F1 score of 92.5 on the SQuAD 2.0 dataset, while in sentiment analysis, RoBERTa reached an accuracy of 96.4% on the SST-2 dataset.[4]
Popular NLP tasks and their corresponding evaluation metrics include:
Machine Translation: Bilingual Evaluation Understudy(BLEU), Metric for Evaluation of Translation with Explicit Ordering (METEOR) , TER (Translation Edit Rate)
Text Summarization: Recall-Oriented Understudy for Gisting Evaluation(ROGUE), BLEU, BERTScore
Question Answering: Exact Match (EM), F1 Score, Mean Reciprocal Rank (MRR)
Named Entity Recognition: F1 Score, Precision, Recall
Sentiment Analysis: Accuracy, F1 Score, Area Under ROC Curve (AUC-ROC)
Text Classification: Accuracy, F1 Score, Precision, Recall
Natural Language Inference: Accuracy, F1 Score
Coreference Resolution: MUC, B3, CEAFe
Dialogue Systems: BLEU, Perplexity, Human Evaluation Metrics
Text Generation: BLEU, METEOR, ROUGE, Perplexity, Human Evaluation
Part-of-Speech Tagging: Accuracy, F1 Score
Semantic Role Labeling: F1 Score, Precision, Recall
Grammatical Error Correction: F0.5 Score, General Language Evaluation Understanding(GLEU)
Paraphrase Generation: BLEU, METEOR, TER, Paraphrase In Context (PIC) score
These metrics provide quantitative measures of model performance, allowing researchers and practitioners to compare different approaches and track progress in the field. However, it's important to note that many NLP tasks also benefit from qualitative human evaluation, especially for aspects like fluency, coherence, and contextual appropriateness that may not be fully captured by automated metrics.
Code Generation and Analysis
LLMs have emerged as powerful tools in software development, offering capabilities such as code completion, test case generation, bug detection, and even full code generation. These models leverage their understanding of programming languages and patterns to assist developers in various tasks.
Code completion, one of the primary applications of LLMs in software development, has seen significant advancements. Models like GitHub Copilot, powered by OpenAI's Codex, can suggest entire functions or code blocks based on context and comments. For instance, given a function signature and a descriptive comment, Copilot can generate a complete implementation, often with high accuracy.
Bug detection is another area where LLMs excel. These models can analyze code snippets and identify potential issues, ranging from syntax errors to logical flaws. For example, DeepCode, an AI-powered code review tool, can detect bugs and suggest fixes by learning from millions of open-source repositories.
However, code-focused LLMs face several challenges and limitations:
Contextual understanding: LLMs may struggle to grasp the full context of a large codebase, potentially leading to inconsistent or incompatible suggestions.
Security concerns: Generated code may inadvertently introduce vulnerabilities or use outdated, insecure practices.
Licensing issues: LLMs trained on open-source code may generate snippets that violate licensing agreements.
Overreliance: Developers may become overly dependent on AI suggestions, potentially impacting their skill development and code understanding.
Hallucination: LLMs might generate plausible-looking but incorrect or non-existent API calls or functions.
Despite these challenges, several successful code generation applications have emerged:
TabNine: This autocomplete tool uses deep learning to predict and suggest code completions across multiple programming languages. It adapts to individual coding styles and project-specific patterns.
GPT-4 for natural language to SQL: Developers have used GPT to generate SQL queries from natural language descriptions, simplifying database interactions for non-technical users.
Codex for API usage: OpenAI's Codex has demonstrated the ability to generate code for using complex APIs based on natural language instructions, significantly reducing the learning curve for new developers.
AlphaCode: Developed by DeepMind, AlphaCode has shown the ability to solve competitive programming problems, generating complete, functional solutions from problem descriptions.
Replit GhostWriter: This AI-powered coding assistant can generate entire functions, explain code, and even create unit tests, demonstrating the broad capabilities of LLMs in software development.
These applications showcase the potential of LLMs to revolutionize software development practices, enhancing productivity and accessibility. However, it's crucial to use these tools judiciously, understanding their limitations and complementing them with human expertise and oversight.
Creative and Content Generation
Generative AIs (GenAI) like LLMs have transformed creative writing and content creation, offering capabilities that range from generating marketing copy to composing poetry and even writing screenplays. These models can produce human-like text across various styles and formats, often with remarkable coherence and creativity.
In content marketing, LLMs like GPT-3 are used to generate blog posts, social media content, and product descriptions. For instance, Jasper.ai, an AI writing assistant, can create full-length articles on given topics, significantly speeding up the content creation process. In journalism, AI tools like Articoolo can generate news articles from basic information inputs, although human oversight remains crucial for fact-checking and editorial decisions.
LLMs have also shown prowess in creative writing. They can generate short stories, poetry, and even assist in screenplay writing. For example, GPT has been used to co-write scripts for short films, demonstrating its ability to understand and replicate narrative structures and dialogue patterns.
However, the use of AI in creative and content generation raises several ethical considerations:
Authorship and Copyright: Questions arise about who owns the rights to AI-generated content and how to attribute authorship.
Plagiarism and Originality: There are concerns about LLMs potentially reproducing copyrighted content or generating text that's too similar to existing works.
Job Displacement: The efficiency of AI in content creation may lead to concerns about job losses in writing and creative industries.
Misinformation and Fake Content: The ability of LLMs to generate convincing text raises concerns about the potential for creating and spreading misinformation.
Creative Authenticity: There's an ongoing debate about whether AI-generated art and literature can truly be considered "creative" or if human involvement is necessary for genuine creativity.
Regulatory Compliance: As AI tools become more common in industries such as finance, healthcare, and legal, ensuring that the content generated by LLMs complies with industry-specific regulations becomes critical. For instance, content pertaining to health advice or financial guidance must adhere to strict standards and regulatory requirements to avoid misinformation and potential harm.
Examples of creative outputs from well-known LLMs include:
Poetry by GPT: The model has generated poems in various styles, from sonnets to free verse, often capturing complex emotions and imagery.
Short Stories by BERT: While primarily used for other NLP tasks, fine-tuned versions of BERT have produced coherent short stories with defined characters and plot arcs.
Screenplays by InferKit: This AI tool, based on GPT technology, has been used to generate screenplay snippets and dialogue that capture the essence of different genres.
Music Lyrics by AIVA: Although not strictly an LLM, this AI composer can generate both music and accompanying lyrics, showcasing the potential for cross-modal creativity.
Marketing Copy by Copy.ai: This GPT-3 powered tool generates various types of marketing content, from email subject lines to full product descriptions, adapting to different brand voices and styles.
While LLMs offer powerful tools for augmenting human creativity and productivity, the ethical considerations press the need for responsible development and use of these technologies in creative fields.
Conclusion
LLMs have revolutionized NLP, demonstrating remarkable capabilities across various tasks. From machine translation to creative writing, LLMs have shown their versatility and power. The training process for these models involves complex techniques such as attention mechanisms, advanced optimization algorithms, and careful management of computational resources.
Challenges like bias mitigation and scaling laws continue to be an area of ongoing research in the field. As LLM training techniques evolve, we are set to see improvements in model performance, efficiency, and applicability. Research in areas like few-shot learning, multimodal models, and more efficient training paradigms promises even more exciting developments. Staying informed about these advancements is crucial for anyone involved in engineering, as the field of AI continues to progress at a rapid pace.
Frequently Asked Questions
What is the difference between training and fine-tuning an LLM?
Training an LLM, often referred to as pre-training, involves teaching the model to understand and generate language using a large, diverse dataset. This process creates a general-purpose model with broad language understanding. Fine-tuning, on the other hand, involves further training the pre-trained model on a smaller, task-specific dataset to adapt it for particular applications.
Pre-training is appropriate when creating a new LLM from scratch or when aiming for a model with general language understanding. Fine-tuning is suitable when adapting an existing model for specific tasks or domains.
Pre-training benefits include broad language understanding and the ability to perform well on various tasks. However, it requires significant computational resources and large datasets. Fine-tuning offers quick adaptation to specific tasks and can achieve high performance with limited data. Its limitations include potential catastrophic forgetting and the need for careful hyperparameter tuning.
How long does it typically take to train a large language model?
Training time for LLMs varies significantly based on model size and available hardware. Here's a comparison table:
Model Size | Hardware | Approximate Training Time |
1 billion parameters | 8 V100 GPUs | 2-3 weeks |
10 billion parameters | 64 V100 GPUs | 1-2 months |
100 billion parameters | 512 V100 GPUs | 3-6 months |
1 trillion parameters | 2048+ V100 GPUs | 6-12 months |
Factors influencing training duration include:
Model architecture and complexity
Dataset quality, size and preprocessing requirements
Hardware efficiency and parallelization strategies
Optimization algorithms and learning rate schedules
Convergence criteria and early stopping strategies
What are the main challenges in training multilingual LLMs?
Training multilingual LLMs presents several complexities:
Data imbalance: Ensuring equal representation of all languages is challenging due to varying amounts of available data.
Cross-lingual transfer: Balancing the model's ability to share knowledge across languages while maintaining language-specific nuances.
Tokenization: Creating a unified tokenization strategy that works effectively across multiple languages with different writing systems.
Model capacity: Ensuring sufficient model capacity to capture the intricacies of multiple languages without interference.
Techniques for improving multilingual performance include:
Using language-agnostic tokenizers like SentencePiece
Implementing language-specific adapters or supervised fine-tuning (SFT)
Employing multilingual pre-training objectives
Utilizing cross-lingual data augmentation techniques
Successful multilingual LLM projects include:
mBERT (multilingual BERT) by Google, supporting 104 languages
XLM-R by Meta-Facebook, which outperforms monolingual models in many languages
mT5, a multilingual version of T5, showing strong performance across 101 languages
Optimizing AI workflows is crucial for scaling up applications and managing the increasing complexity of machine learning projects.
What is Retrieval-Augmented Generation (RAG) and how does it enhance AI models?
Retrieval-Augmented Generation (RAG) is an AI technique that enhances the capabilities of language models by integrating them with a retrieval system. This system fetches relevant information from a vast database or knowledge base in response to queries. RAG then uses this retrieved information to inform and improve the accuracy of the generated output. It's particularly useful in applications like question answering and content generation, where accessing external, detailed information can significantly improve the relevance and depth of responses.
Which brands are leading in artificial intelligence? What are some influential LLMs developed by major brands?
- Google DeepMind: While primarily known for breakthroughs in reinforcement learning, Google has contributed to the LLM field with models like BERT, which has transformed the way machines understand human language by enabling them to process words in relation to all the other words in a sentence.
- OpenAI: OpenAI’s GPT series is one of the most famous LLMs, renowned for its ability to generate coherent and contextually relevant text on a broad array of topics. GPT's impressive versatility enables applications ranging from writing assistance to more complex tasks like programming aid and data analysis.ChatGPT by OpenAI
- IBM: IBM has leveraged its Watson technology to create sophisticated LLMs that aid in fields such as customer service and healthcare, where Watson assists in sifting through large volumes of data to provide insights and automated responses.
- Microsoft: Microsoft’s Turing-NLG is a large-scale language model that uses deep learning to produce human-like text, enhancing Microsoft’s range of products from document translation within Office tools to conversational capabilities in chatbots.
- Meta (formerly Facebook): Meta’s LLaMA models, including LLaMA 2 and LLaMA 3.1, are designed to excel in a variety of NLP tasks, including translation, content generation, and summarization. These models are notable for their efficiency, making them suitable for deployment in environments where computational resources are a concern.
Llama by Meta
- Amazon: Though Amazon is best known for Alexa in the consumer space, it has developed Amazon Comprehend, a natural language processing (NLP) service that uses machine learning to uncover insights and relationships in text. The service is built upon LLMs that analyze text and provide language-specific insights.
What are the environmental concerns associated with LLMs?
LLMs consume significant energy, contributing to carbon emissions. For example, a single query to ChatGPT can emit 2.5 to 5 grams of CO2, according to different sources. According to a thorough computation, every message sent to ChatGPT generates roughly 4.32 grams of CO2.[5]
Efforts to make LLM training more environmentally friendly include:
Developing more efficient architectures like Performers or Reformers
Using carbon-aware scheduling for training jobs
Implementing sparsity and pruning techniques to reduce computation
Utilizing renewable energy sources for data centers
Suggestions for reducing environmental impact:
Prioritize model efficiency over sheer size when possible
Reuse and fine-tune existing models instead of training from scratch
Invest in more energy-efficient hardware
Implement carbon tracking and reporting in AI projects
Collaborate on shared models to reduce redundant training efforts
References
[1] Snell C, Lee J, Xu K, Kumar A. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters [Internet]. 2024 [cited 2024 Aug]. Available from: https://arxiv.org/abs/2408.03314
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems (pp. 5998-6008). Available from: https://arxiv.org/abs/1706.03762
[3] Zhang, J., Zhao, Y., Saleh, M., & Liu, P. J. (2020). PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020). Available from: https://arxiv.org/abs/1912.08777
[4] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, Y. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Available here on arXiv. Available from: https://arxiv.org/pdf/1910.10683
[5] Smartly AI. The Carbon Footprint of ChatGPT: How Much CO2 Does a Query Generate? Smartly AI Blog. [Internet]. [7 Jul. 2024]. Available from: https://smartly.ai/blog/the-carbon-footprint-of-chatgpt-how-much-co2-does-a-query-generate
Table of Contents
IntroductionWhat are LLMs?Demystifying LLM Architecture: The Foundation of TrainingNeural Network Basics for LLMsLLMs vs RNNsAttention Mechanisms and Self-AttentionTokenization and Embedding StrategiesCutting-Edge Training Techniques: Pushing LLM BoundariesPre-training StrategiesFine-tuning LLMs for Specific TasksAdvanced Optimization AlgorithmsOvercoming Training Hurdles: Tackling LLM ChallengesManaging Computational ResourcesAddressing Bias and FairnessScaling Laws and Model Size ConsiderationsReal-World Applications: LLMs in ActionNatural Language Processing TasksCode Generation and AnalysisCreative and Content GenerationConclusionFrequently Asked QuestionsWhat is the difference between training and fine-tuning an LLM?How long does it typically take to train a large language model?What are the main challenges in training multilingual LLMs?What is Retrieval-Augmented Generation (RAG) and how does it enhance AI models?Which brands are leading in artificial intelligence? What are some influential LLMs developed by major brands?What are the environmental concerns associated with LLMs?References