Tensor Cores vs CUDA Cores: The Powerhouses of GPU Computing from Nvidia
CUDA Cores and Tensor Cores are specialized units within NVIDIA GPUs; the former are designed for a wide range of general GPU tasks, while the latter are specifically optimized to accelerate AI and deep learning through efficient matrix operations.

25 Jul, 2024. 23 minutes read

Introduction
In the rapidly evolving landscape of modern engineering, graphics processing units (GPU) computing is revolutionizing computational capabilities across diverse fields. At the heart of this transformation lie two critical components of NVIDIA GPUs: Tensor Cores/Tensor processing units (TPU) and CUDA Cores. These specialized processing units, differing fundamentally from traditional CPU cores, have become indispensable tools for engineers tackling complex problems in artificial intelligence, machine learning, scientific simulations, and high-performance computing.
As the demands for computational power continue to grow, understanding Tensor Cores and CUDA Cores has become crucial for engineers seeking to optimize performance and push the boundaries of what's possible in their respective domains. The distinction between these two types of cores often raises questions among professionals, and we'll address a common inquiry about their relationship in the following section. By delving into the intricacies of these GPU powerhouses, engineers can harness their full potential and drive innovation in their fields.
CUDA Cores vs Tensor Cores: Clearing the Confusion
CUDA cores and Tensor Cores are not the same. While both are integral components of NVIDIA graphic cards, they serve distinct purposes and are designed for different types of computational tasks.
CUDA (Compute Unified Device Architecture) cores, developed by NVIDIA in 2007, are the fundamental processing units of their GPUs. They are versatile, general-purpose cores capable of handling a wide range of parallel computing tasks. CUDA cores excel at sequential processing and are the workhorses for traditional graphics rendering, physics simulations, and general-purpose GPU computing.
Recommended reading: Understanding Nvidia CUDA Cores: A Comprehensive Guide
Tensor Cores, on the other hand, are specialized processing units introduced in NVIDIA's Volta architecture in 2017 and further refined in subsequent generations. These cores are specifically designed to accelerate deep learning and AI workloads, particularly matrix multiplication and convolution operations that are prevalent in neural network computations.
Key differences between CUDA cores and Tensor Cores:
Aspect | CUDA Cores | Tensor Cores |
Purpose | General-purpose parallel computing | Specialized for AI and deep learning acceleration |
Introduced | 2007 | 2017 with NVIDIA's Volta architecture |
Precision | Primarily FP32 and FP64 | Mixed precision (FP16, FP32, INT8, INT4) |
Workload | Wide range of GPU computing tasks | Optimized for matrix multiplication and convolution operations |
Programming Model | CUDA programming model | Accessible through high-level AI frameworks and CUDA |
Architecture | Based on Single Instruction, Multiple Thread (SIMT) model | Designed around a matrix multiply-accumulate engine |
Ideal Use Cases | Traditional graphics rendering, physics simulations | Deep learning training and inferencing, large neural networks |
Performance | High performance in general-purpose GPU computing | Exceptionally high throughput for matrix operations |
While CUDA cores provide the foundation for NVIDIA's GPU computing capabilities, Tensor Cores offer a significant performance boost for specific AI and deep learning tasks. The combination of these two core types in modern NVIDIA GPUs allows for efficient handling of diverse workloads, from traditional graphics rendering to cutting-edge AI applications.
Understanding the distinction between CUDA cores and Tensor Cores is crucial for developers and engineers to optimize their applications and leverage the full potential of NVIDIA GPUs. By utilizing the appropriate core types and APIs for specific tasks, developers can achieve significant performance improvements and energy efficiency in their computational workflows.
The Building Blocks of GPU Acceleration
Decoding CUDA Cores: The Versatile Workhorses
CUDA Cores form the fundamental processing units of NVIDIA GPUs. These cores are designed to execute parallel computations efficiently, making them the backbone of GPU acceleration. Each CUDA Core is essentially a small, programmable processor capable of performing floating-point and integer operations.
The architecture of CUDA Cores is based on the Single Instruction, Multiple Thread (SIMT) model. This design allows multiple threads to execute the same instruction simultaneously on different data, enabling massive parallelism. CUDA Cores are organized into Streaming Multiprocessors (SMs), which share resources like cache and memory, further enhancing computational efficiency.
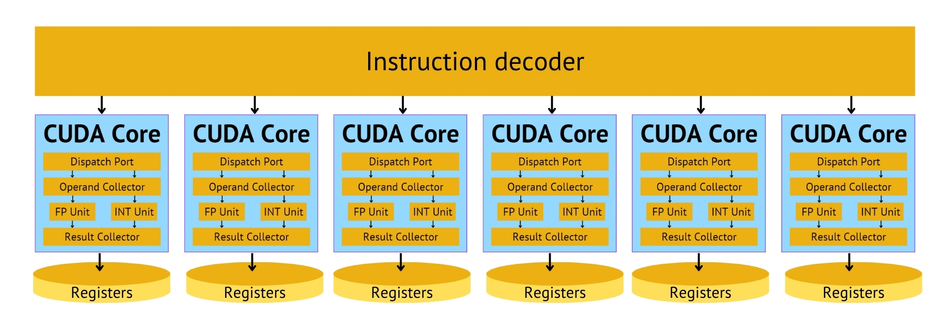
In parallel processing and general-purpose GPU computing, CUDA Cores excel at handling diverse workloads. They can process thousands of threads concurrently, making them ideal for tasks that can be broken down into smaller, independent computations. This parallel processing capability is particularly beneficial for applications in scientific simulations, computer vision, and data analysis.
Key features that make CUDA Cores efficient for a wide range of tasks include:
Flexible precision support, allowing for FP32 (single-precision) and FP64 (double-precision) computations
Advanced scheduling and load-balancing mechanisms
Hardware-accelerated atomic operations for efficient parallel algorithms
Support for complex branching and flow control
The primary capabilities of CUDA Cores include:
Parallel execution of arithmetic and logical operations
Efficient memory access and management
Support for various data types and precision levels
Execution of complex algorithms and control structures
Seamless integration with graphics rendering pipelines
Acceleration of general-purpose computing tasks across multiple domains
As highlighted in the previous section, CUDA Cores differ from Tensor Cores in their versatility and general-purpose nature. While Tensor Cores specialize in matrix operations for AI and deep learning, CUDA Cores handle a broader spectrum of computational tasks, reinforcing their unique role as the versatile workhorses of NVIDIA GPUs. This flexibility allows CUDA Cores to adapt to various computational challenges, from traditional graphics rendering to complex scientific simulations.
Tensor Cores: Precision Engineered for AI and high-performance computing (HPC)
Tensor Cores represent a revolutionary advancement in GPU architecture, specifically designed to accelerate deep learning and high-performance computing (HPC) workloads. These specialized processing units feature a unique matrix multiply-accumulate engine that operates on small matrices, typically 4x4 for FP16 inputs and FP32 accumulate.
The primary function of Tensor Cores is to dramatically accelerate matrix multiplication and convolution operations, which form the backbone of many deep learning algorithms. By performing these operations in a single clock cycle, Tensor Cores achieve significantly higher throughput compared to traditional CUDA cores. This acceleration is crucial for training and inferencing large neural networks, where millions of these operations are performed repeatedly.
In deep learning and scientific computing, Tensor Cores play a pivotal role in reducing training times and enabling more complex models. They excel in applications such as image and speech recognition, natural language processing, and autonomous systems. In HPC, Tensor Cores accelerate simulations in fields like climate modeling, molecular dynamics, and financial risk analysis.
The evolution of Tensor Cores across different NVIDIA GPU generations has brought significant improvements in performance and capabilities:
Generation | Architecture | Key Features | Performance Improvement |
1st Gen | Volta | FP16 and FP32 support | Baseline |
2nd Gen | Turing | INT8 and INT4 support | 2x FP16 performance vs. Volta |
3rd Gen | Ampere | TF32 format, sparse matrix support | 5x FP16 performance vs. Volta |
4th Gen | Hopper | FP8 support, Transformer Engine | 6x FP16 performance vs. Ampere |
In contrast to CUDA Cores, Tensor Cores are highly specialized units optimized for specific mathematical operations. While CUDA Cores offer flexibility for a wide range of parallel computing tasks, Tensor Cores provide unparalleled performance for matrix operations common in AI and HPC workloads. This specialization allows Tensor Cores to achieve orders of magnitude higher throughput for these specific operations, making them indispensable for cutting-edge AI research and development.
The introduction of Tensor Cores has accelerated existing AI applications but has also enabled the development of more sophisticated models and techniques that were previously computationally infeasible. As AI and HPC continue to advance, the role of Tensor Cores in pushing the boundaries of what's possible in these fields becomes increasingly crucial.
Architectural Face-off: Tensor Cores vs CUDA Cores
Design Philosophy and Computational Approach
The architectural design of Tensor Cores and CUDA Cores reflects their distinct roles in modern GPU computing. CUDA Cores embody a design philosophy centered on versatility and general-purpose computation. At the same time, Tensor Cores represent a specialized approach optimized for specific mathematical operations crucial to AI and HPC workloads.
CUDA Cores are built on the Single Instruction, Multiple Thread (SIMT) model, allowing them to execute the same instruction across multiple data points simultaneously. This design enables efficient parallel processing for a wide range of computational tasks. The architecture of CUDA Cores includes:
Arithmetic Logic Units (ALUs) for integer and floating-point operations
Special Function Units (SFUs) for complex mathematical functions
Load/Store Units for memory operations
Register files for fast data access
Tensor Cores, in contrast, are designed with a matrix multiply-accumulate engine at their core. This specialized architecture allows them to perform matrix operations with exceptional efficiency. The key components of a Tensor Core include:
Matrix Multiply Units (MMUs) for rapid matrix computations
Accumulation Units for precise sum operations
Data Formatting Units for handling various precision levels
The instruction sets for CUDA Cores are more diverse, supporting a wide range of operations, including arithmetic, logical, and control flow instructions. This allows CUDA Cores to handle complex algorithms and varied workloads. The execution model for CUDA Cores involves:
Warp-based execution (32 threads per warp): CUDA Cores utilize what is known as "warp-based execution." In this context, a warp is a group of 32 threads that are executed simultaneously by a CUDA Core. This grouping method allows for highly parallel processing, as multiple operations across the 32 threads can be carried out simultaneously. This is especially effective for operations that can be parallelized, enhancing the processing speed for tasks that involve large data sets or repetitive calculations.
Dynamic scheduling of warps: CUDA Cores dynamically schedule warps to different streaming multiprocessors based on availability and workload demands. Dynamic scheduling helps optimize the utilization of the GPU’s resources by ensuring that all multiprocessors are kept as busy as possible. This adaptive scheduling can also mitigate the impact of delays caused by slower operations in some threads, as other warps can be processed while those threads are waiting.
Branch divergence handling: Branch divergence occurs when different threads of the same warp need to execute different instructions, typically due to conditional branches in the code (like if statements). When this happens, the CUDA architecture can handle divergence efficiently. It does this by executing each branch path required by any thread in the warp, but only the threads that need to execute that particular branch will be active while the others are idle. This ensures all possible paths are covered without forcing all threads to execute all paths, thus managing divergences smartly and reducing unnecessary computations.
Tensor Cores, however, have a more focused instruction set primarily centered around matrix operations. Their execution model is optimized for:
Rapid matrix multiplication and accumulation: Tensor Cores are specifically engineered to perform very fast matrix multiplication and accumulation operations, which are central to many AI algorithms, particularly neural networks. Each Tensor Core can perform operations like A * B + C, where A, B, and C are matrices. This ability to perform complex matrix operations in a single step dramatically speeds up the training and inference processes in deep learning models.
Mixed-precision operations: Mixed-precision refers to the use of different numerical precisions within a computational process. Tensor Cores are designed to support mixed-precision computing, which allows them to operate at lower precision (like FP16) for multiplying matrices while using higher precision (like FP32) for accumulation. This approach maintains high computational throughput and energy efficiency while preserving the necessary numerical accuracy of the results. Mixed-precision is particularly beneficial in speeding up deep learning computations and reducing the memory footprint during training.
Efficient data movement between matrix operations: Efficient data movement is crucial in high-performance computing to avoid bottlenecks associated with data transfer between different parts of the hardware. Tensor Cores optimize the movement of data between operations, reducing the time and energy spent on moving data around. This is achieved through sophisticated memory hierarchy designs and direct data paths that connect Tensor Cores to GPU memory and caches. As a result, data required for successive operations is rapidly available, enhancing the overall efficiency of the GPU.
The distinct roles of these core types are evident in their design and computational approach. CUDA Cores provide the flexibility and broad applicability needed for general-purpose GPU computing, tackling diverse tasks from graphics rendering to scientific simulations. Tensor Cores, with their specialized architecture, deliver unprecedented performance for the specific matrix operations that dominate AI and HPC workloads, enabling breakthroughs in deep learning and complex numerical simulations.
Precision and Data Types: Balancing Act
In GPU computing, precision and data types play crucial roles in determining the accuracy of computations and the overall performance of applications. CUDA Cores and Tensor Cores offer different precision capabilities, catering to a wide range of computational needs.
CUDA Cores traditionally excel in single-precision (FP32) and double-precision (FP64) floating-point operations, which are essential for many scientific computing applications requiring high accuracy. They also support integer operations (INT32, INT64) for general-purpose computing tasks. Recent NVIDIA architectures have expanded CUDA Core capabilities to include half-precision (FP16) support, enhancing performance for applications that can tolerate lower precision.
Tensor Cores, designed primarily for AI and deep learning workloads, offer a more diverse range of precision options. They support FP16, FP32, and in newer architectures, even FP64 operations. Additionally, Tensor Cores can work with lower precision formats like INT8 and INT4, which are particularly useful for inference tasks in deep learning. The latest generations of Tensor Cores also support the TensorFloat32 (TF32) format, which provides near-FP32 accuracy with FP16-like performance.
Mixed-precision computing is a technique that combines different levels of precision in a single workflow. This approach allows applications to leverage the speed of lower precision operations where possible while maintaining the accuracy of higher precision computations where necessary. Mixed-precision computing is particularly relevant in deep learning, where training often requires higher precision (FP32 or FP16) for weight updates. In comparison, inference can often be performed with lower precision (INT8 or INT4) without significant loss of accuracy.The trade-offs between precision and performance vary depending on the application. Higher precision generally offers greater accuracy but at the cost of increased computational time and energy consumption. For example:
Scientific simulations often require FP64 precision to maintain accuracy over many iterations, making CUDA Cores more suitable despite the performance penalty.
Deep learning training typically uses FP32 or FP16, benefiting from Tensor Cores' optimized performance for these precisions.
Inference tasks in AI can often use INT8 or even INT4 precision, dramatically improving performance and energy efficiency with Tensor Cores, albeit with a small accuracy trade-off.
Computer graphics usually employ FP32 for most calculations, balancing visual quality and performance using CUDA Cores.
Financial applications may require FP64 for specific calculations to meet regulatory requirements, necessitating the use of CUDA Cores or newer generation Tensor Cores with FP64 support.
The choice of precision and core type ultimately depends on the specific requirements of the application, balancing the need for accuracy with the demands for performance and energy efficiency. Understanding these trade-offs is crucial for optimizing GPU-accelerated applications across various domains.
Performance Metrics: Crunching the Numbers: Benchmarking Tensor Cores and CUDA Cores
Benchmarking Tensor Cores and CUDA Cores provides crucial insights into their performance characteristics across various computational tasks. These benchmarks help developers and researchers decide which core type is best suited for specific applications.
In a series of tests comparing the latest generation of NVIDIA GPUs, Tensor Cores consistently outperform CUDA Cores in matrix multiplication and deep learning workloads. For instance, in a benchmark using a large-scale matrix multiplication task (10,000 x 10,000 matrices), Tensor Cores achieve up to 6x higher performance than CUDA Cores when using mixed-precision (FP16) computations.
When evaluating specific performance metrics, its necessary to understand the following terms:
FLOPS (Floating Point Operations Per Second)
Throughput: Tensor Cores excel in processing large batches of data, achieving up to 3x higher throughput in deep learning inference tasks than CUDA Cores.
Latency: CUDA Cores generally offer lower latency for single, small computations due to their more general-purpose design.Tensor Cores may introduce slightly higher latency for individual operations but compensate with significantly higher throughput for larger workloads.
In real-world scenarios, these benchmark results translate to significant performance gains in specific applications:
Deep Learning Training: A popular image classification model (ResNet-50) trained on the ImageNet dataset showed a 3x speedup when utilizing Tensor Cores compared to CUDA Cores alone.[1]
Scientific Simulations: While CUDA Cores still dominate in double-precision (FP64) computations, Tensor Cores with TF32 precision offer a compelling alternative for many simulations, providing near-FP32 accuracy with up to 2x performance improvement.
Computer Vision: In real-time object detection tasks, Tensor Cores demonstrated a 2.5x performance boost over CUDA Cores, enabling higher frame rates and more complex models in edge devices.
It's important to note that these benchmarks represent performance under optimal conditions. Real-world performance can vary based on factors such as problem size, memory bandwidth utilization, and the specific algorithms used. Additionally, the effectiveness of Tensor Cores heavily depends on the ability to leverage their specialized matrix multiplication capabilities within the application's computational workflow.
For developers, these benchmarks underscore the importance of algorithm design and optimization techniques that can fully utilize the strengths of each core type. While Tensor Cores offer unprecedented performance for specific operations, CUDA Cores remain essential for their flexibility and performance in a wide range of general-purpose computing tasks.
Harnessing the Power: Applications and Use Cases
AI and Deep Learning: The Tensor Core Domain
Tensor Cores have revolutionized the field of AI and deep learning by providing unprecedented computational power for matrix operations, which form the backbone of most neural network architectures. These specialized processing units excel in AI tasks due to their ability to perform mixed-precision matrix multiply-accumulate operations in a single clock cycle, dramatically accelerating the training and inference of deep learning models.
Recommended reading: TPU vs GPU in AI: A Comprehensive Guide to Their Roles and Impact on Artificial Intelligence
The architecture of Tensor Cores is specifically optimized for the following deep-learning operations:
Matrix Multiplication: The fundamental operation in neural network layers, particularly in fully connected layers.
Convolutions: Essential for Convolutional Neural Networks (CNNs) used in image and video processing tasks.
Attention Mechanisms: Critical for Transformer architectures in Natural Language Processing (NLP) models.
Tensor Contractions: Important for advanced neural network architectures and scientific computing applications.
These operations benefit from Tensor Cores' ability to perform rapid, low-precision calculations while maintaining accuracy through techniques like mixed-precision training and automatic loss scaling.
Several popular AI frameworks and libraries have been optimized to leverage Tensor Cores:
TensorFlow: Utilizes Tensor Cores through the XLA (Accelerated Linear Algebra) compiler and optimized CUDA kernels.
PyTorch: Integrates Tensor Core acceleration via NVIDIA's cuDNN and cuBLAS libraries.
NVIDIA TensorRT: An SDK for high-performance deep learning inference, extensively utilizing Tensor Cores.
RAPIDS: A suite of open-source software libraries for executing end-to-end data science and analytics pipelines entirely on GPUs.
MXNet: Supports Tensor Cores through the TensorCore operator and automatic mixed precision (AMP).
Key AI applications leveraging Tensor Core technology include:
Natural Language Processing
Machine translation systems
Sentiment analysis engines
Text summarization tools
Large language models (e.g., GPT, BERT)
Computer Vision
Object detection and recognition in real-time video streams
Image segmentation for medical imaging
Facial recognition systems
Autonomous vehicle perception systems
Speech Technologies
Speech recognition for virtual assistants
Text-to-speech synthesis
Voice cloning and audio generation
Generative AI
Image generation models (e.g., DALL-E, Stable Diffusion)
Text-to-image synthesis
Style transfer algorithms
Recommender Systems
E-commerce product recommendations
Content personalization for streaming services
Social media feed curation
Scientific and Medical AI
Drug discovery and molecular modeling
Protein structure prediction
Medical image analysis and diagnosis
Financial Services
High-frequency trading algorithms
Fraud detection systems
Risk assessment models
The adoption of Tensor Cores in these applications has led to significant improvements in model accuracy, training speed, and inference performance, enabling the development of more complex and capable AI systems across various industries.
Recommended reading: 2024 State of Edge AI Report
Scientific Computing and Simulation: CUDA's Forte
CUDA Cores have become indispensable in scientific computing and simulation, offering unprecedented computational power for a wide range of complex scientific problems. These versatile processing units excel in areas that require high-precision calculations, complex algorithmic implementations, and the ability to handle large datasets efficiently.
Key areas where CUDA Cores shine in scientific computing include:
Computational Fluid Dynamics (CFD): Simulating fluid flow in aerospace, automotive, and climate modeling.
Molecular Dynamics: Studying the physical movements of atoms and molecules in biological and materials science.
Quantum Chemistry: Performing electronic structure calculations for molecular systems.
Astrophysics: Modeling galactic evolution, gravitational wave analysis, and cosmological simulations.
Financial Modeling: Running Monte Carlo simulations for risk analysis and option pricing.
Geophysics: Processing seismic data and modeling subsurface structures.
The versatility of CUDA Cores in handling diverse scientific workloads stems from several factors:
Precision Flexibility: CUDA Cores support single-, double-, and half-precision floating-point operations, allowing scientists to balance accuracy and performance as needed.
Algorithmic Adaptability: CUDA Cores' general-purpose nature enables the implementation of complex, custom algorithms specific to various scientific domains.
Scalability: CUDA's programming model allows for efficient scaling of computations across multiple GPUs, enabling the tackling of increasingly large and complex problems.
Memory Hierarchy Utilization: CUDA Cores can efficiently leverage different levels of GPU memory, optimizing data access patterns crucial for scientific computations.
Examples of scientific simulations heavily relying on CUDA technology include:
GROMACS (GROningen MAchine for Chemical Simulations): A molecular dynamics package used for simulating proteins, lipids, and nucleic acids.
NAMD (Nanoscale Molecular Dynamics): Designed for high-performance simulation of large biomolecular systems.
ANSYS Fluent: A computational fluid dynamics software used in aerospace, automotive, and energy sectors.
WRF (Weather Research and Forecasting): A next-generation mesoscale numerical weather prediction system.
Table of scientific domains and corresponding CUDA-accelerated applications:
Scientific Domain | CUDA-Accelerated Application |
Bioinformatics | BLAST+ (Basic Local Alignment Search Tool) |
Quantum Chemistry | GAMESS (General Atomic and Molecular Electronic Structure System) |
Geosciences | SPECFEM3D (Spectral Finite Element Method in 3D) |
Particle Physics | GEANT4 (GEometry ANd Tracking) |
Electromagnetic Simulations | FDTD Solutions (Finite-Difference Time-Domain) |
Computational Chemistry | LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) |
Signal Processing | cuSignal (GPU-accelerated signal processing) |
Financial Engineering | QuantLib (Quantitative Finance Library) |
The adoption of CUDA Cores in these scientific applications has led to dramatic reductions in computation times, often by orders of magnitude. This acceleration has not only improved the efficiency of existing research but has also enabled scientists to tackle problems of unprecedented scale and complexity, pushing the boundaries of scientific discovery across multiple disciplines.
Graphics and Rendering: The Hybrid Approach
Modern graphics rendering in NVIDIA GPUs leverages a hybrid approach, utilizing both Tensor Cores and CUDA Cores to achieve unprecedented levels of visual fidelity and performance. This synergy between specialized and general-purpose cores has revolutionized real-time rendering techniques, enabling advanced features like ray tracing and AI-enhanced upscaling.
Tensor Cores contribute to graphics rendering primarily through AI-accelerated tasks:
- Denoising in ray-traced scenes: Ray tracing generates highly realistic lighting by simulating the physical behavior of light. However, it can produce noisy images if not enough rays are sampled. Tensor Cores accelerate the process of denoising these images by using deep learning algorithms to predict and fill in gaps, enhancing image clarity without compromising on the detail that ray tracing provides.
- Deep Learning Super Sampling (DLSS): DLSS is a revolutionary feature that uses neural networks to analyze thousands of frames and learn how to optimally enhance the resolution of rendered images. By employing DLSS, games can run at lower native resolutions and then upscale intelligently to higher resolutions, improving frame rates without a noticeable loss in image quality. Tensor Cores are essential here as they perform the intensive matrix multiplications required by the deep learning models at high speeds.
- AI-enhanced texture synthesis: In texture synthesis, AI models can generate high-quality textures from smaller datasets or enhance existing textures. Tensor Cores speed up this process by efficiently handling the computations needed for the neural networks that analyze and generate these textures.
- Motion vector generation for temporal anti-aliasing: Temporal Anti-Aliasing (TAA) is a technique that reduces flickering and smoothens the motion in animated scenes. AI-driven approaches to TAA, supported by Tensor Cores, involve generating motion vectors that predict the movement of pixels between frames. This prediction allows for smoother transitions and reduces visual artifacts.
CUDA Cores, being more versatile, handle a broader range of graphics tasks:
- Traditional rasterization: Rasterization is the process of converting 3D vector graphics into a 2D image, and it involves several steps including vertex processing, shape assembly, and pixel output. CUDA Cores handle the pixel shading and other raster operations efficiently, making them fundamental to the process of rendering most of the graphics seen in video games and applications.
- Geometry processing: This involves calculations to process the shapes that make up a 3D scene, such as vertices and polygons. CUDA Cores perform the mathematical operations needed to transform the geometry into different perspectives and to calculate the effects of lighting and other environmental factors on these objects.
- Pixel shading: Pixel shaders are used to add depth, color, texture, and more detailed characteristics to each pixel. CUDA Cores are used extensively to compute these shaders, which define how pixels appear on the screen, including effects like blur, shadow, and light refraction.
- Physics simulations for particle effects and cloth dynamics: CUDA Cores are adept at handling the complex mathematical computations required for simulating physical phenomena in real-time. This includes simulations for particle systems used in effects like smoke, fire, and explosions, as well as cloth dynamics that simulate the realistic movement of fabric in video games and animations.
In ray tracing, CUDA Cores are responsible for ray generation, traversal, and intersection tests. Tensor Cores then come into play for AI-accelerated denoising of the noisy ray-traced image. This division of labor allows for real-time ray tracing in complex scenes.
DLSS showcases the power of this hybrid approach. CUDA Cores handle the initial lower-resolution rendering, while Tensor Cores run the AI upscaling model that intelligently reconstructs a higher-resolution image. This technique significantly boosts frame rates while maintaining visual quality.
In modern graphics pipelines, the workflow typically follows this pattern:
- CUDA Cores perform initial scene setup and geometry processing.
- Rasterization is carried out by dedicated fixed-function units.
- CUDA Cores handle pixel shading and initial lighting calculations.
- If ray tracing is enabled, CUDA Cores and Ray Tracing cores trace rays and gather lighting information.
- Tensor Cores denoise the ray-traced elements and apply AI-enhanced post-processing.
- For DLSS, Tensor Cores upscale the rendered image to the target resolution.
- CUDA Cores apply final compositing and output processing.
When rendering images in games, Nvidia GPUs, especially those from the RTX series, leverage several types of cores—CUDA, Tensor, and RT Cores—each serving distinct roles in the process. Here’s a breakdown of the steps involved in this rendering process:
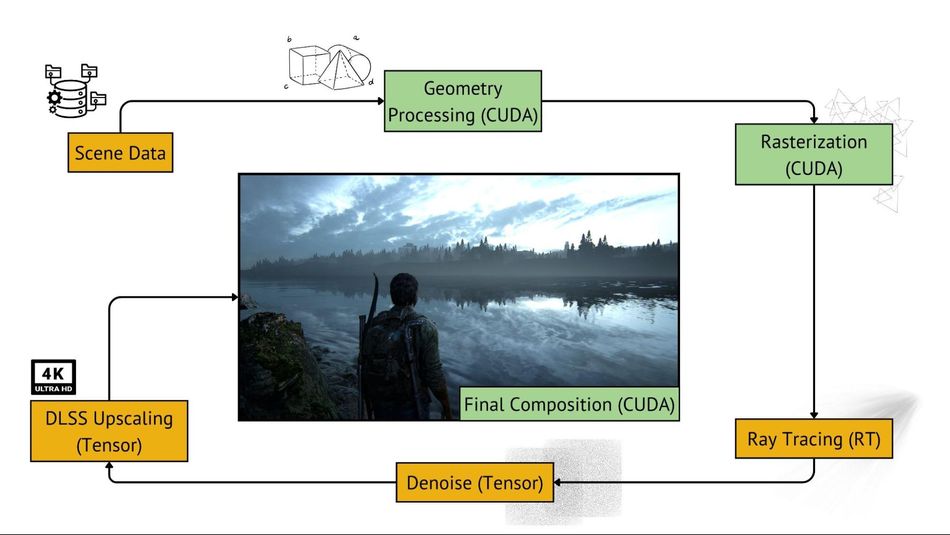
This approach allows for a flexible rendering pipeline that can adapt to different graphics techniques. For instance, in path tracing, CUDA Cores might handle path generation and intersection tests, while Tensor Cores could be used for importance sampling and final image reconstruction.
The collaboration between Tensor Cores and CUDA Cores extends to other advanced graphics techniques as well. In real-time global illumination solutions, CUDA Cores might compute light propagation volumes, while Tensor Cores could enhance the resulting indirect lighting through learned light transport models.
RT cores, while not the focus of the broader CUDA and Tensor core discussion, play a crucial role in Nvidia's GPUs by accelerating ray and bounding volume intersection tests for real-time ray tracing. These specialized cores enable realistic lighting and shadows, enhancing dynamic, physically accurate environments in games. They complement CUDA and Tensor cores by optimizing performance and visual fidelity through integrated hybrid rendering techniques.
By leveraging the strengths of all the core types, modern GPUs can deliver unprecedented levels of realism and performance in real-time graphics rendering. This hybrid approach improves current rendering techniques and opens up possibilities for new AI-enhanced graphics algorithms that were previously computationally infeasible.
Recommended reading: Revolutionizing Edge AI Model Training and Testing with Nvidia Omniverses Virtual Environments
Challenges and Limitations: Understanding the Trade-offs
Programming Complexity and Optimization Hurdles
Programming and optimizing for Tensor Cores and CUDA Cores present distinct challenges, each requiring specialized knowledge and techniques. The complexity arises from the need to understand not only the hardware architecture but also the specific programming models and optimization strategies for each core type.
For CUDA Cores, the primary challenge lies in effectively parallelizing algorithms to exploit the massive number of cores available. This often involves rethinking traditional sequential algorithms and adapting them to a parallel computing paradigm. Developers must carefully manage memory access patterns, thread synchronization, and load balancing to achieve optimal performance.
Tensor Cores, while offering exceptional performance for specific operations, introduce additional complexity. Programming for Tensor Cores requires understanding matrix multiplication and convolution operations at a deep level. Developers must structure their algorithms to leverage these specialized units effectively, which often involves reshaping data and computations to fit the Tensor Core's preferred formats and sizes.
The learning curve for each technology is steep but differs in focus:
CUDA Core programming requires mastering parallel computing concepts, CUDA C/C++ or other CUDA-enabled languages, and understanding GPU architecture.
Tensor Core optimization involves deep knowledge of linear algebra, deep learning frameworks, and mixed-precision arithmetic techniques.
Several tools and frameworks are available to aid development:
NVIDIA CUDA Toolkit: Provides the fundamental tools for CUDA development.
NVIDIA NSight: Offers profiling and debugging capabilities for both CUDA and Tensor Core applications.
TensorRT: Optimizes deep learning models for inference on Tensor Cores.
PyTorch and TensorFlow: High-level frameworks with built-in support for Tensor Core operations.
NVIDIA DALI: Optimizes data loading and preprocessing pipelines for GPU acceleration.
Common optimization techniques for CUDA Cores:
Coalesced memory access to maximize memory bandwidth utilization
Use of shared memory to reduce global memory accesses
Proper thread block sizing to maximize occupancy
Loop unrolling and instruction-level parallelism
Asynchronous memory transfers and stream-based concurrency
Minimizing thread divergence within warps
Common optimization techniques for Tensor Cores:
Structuring matrix operations to match Tensor Core dimensions (e.g., 16x16 for FP16)
Leveraging mixed-precision arithmetic for optimal performance-accuracy trade-offs
Using specialized libraries like cuBLAS and cuDNN that are optimized for Tensor Cores
Employing automatic mixed precision (AMP) in deep learning frameworks
Optimizing data layout and memory access patterns for Tensor Core operations
Balancing Tensor Core utilization with other GPU resources for overall performance
The complexity of optimizing for both core types simultaneously in applications that leverage the hybrid approach adds another layer of challenge. Developers must carefully profile their applications to identify bottlenecks and determine which operations should be directed to each core type for optimal overall performance.
Hardware Constraints and Compatibility Issues
The implementation of Tensor Cores and CUDA Cores in GPU architectures comes with specific hardware constraints and compatibility considerations that significantly impact their performance and applicability across different use cases.
Tensor Cores, while offering exceptional performance for specific operations, face limitations in terms of precision and flexibility. Early generations of Tensor Cores were limited to FP16 and INT8 operations, which, while suitable for many AI workloads, could be insufficient for applications requiring higher precision. More recent architectures have expanded this to include FP32 and even FP64 operations, but at the cost of increased die area and power consumption.
CUDA Cores, being more general-purpose, offer greater flexibility but may not achieve the same level of performance as Tensor Cores for specific operations like matrix multiplication. They also typically consume more power per operation compared to Tensor Cores when performing compatible tasks.
Compatibility across GPU architectures and generations presents another challenge. Tensor Cores were introduced with the Volta architecture and have evolved significantly with each subsequent generation. This means that code optimized for Tensor Cores on one architecture may not be fully compatible or may perform suboptimally on others. For instance, an application leveraging Tensor Cores on an Ampere GPU might not run or could experience reduced performance on a Pascal GPU that lacks Tensor Cores entirely.
CUDA Cores have maintained better backward compatibility, with CUDA code generally running across multiple generations of GPUs. However, newer CUDA capabilities and optimizations may not be available on older hardware, potentially leading to performance disparities.
The choice between Tensor Cores and CUDA Cores significantly impacts power consumption and thermal management. Tensor Cores, when utilized for appropriate workloads, can offer higher performance per watt compared to CUDA Cores. However, their specialized nature means that for general-purpose computing tasks, they may sit idle, potentially leading to inefficient power usage in mixed workloads.
Thermal management becomes particularly crucial when dealing with high-utilization scenarios. The dense computational capabilities of Tensor Cores can lead to localized hot spots on the GPU die, requiring sophisticated cooling solutions. CUDA Cores, while generally producing more heat overall for equivalent computations, tend to distribute this heat more evenly across the die.
Table comparing hardware specifications across different GPU models:
GPU Model | Architecture | CUDA Cores | Tensor Cores | FP32 Performance | Tensor Core Performance (FP16) | TDP |
RTX 4090 | Ada Lovelace | 16,384 | 512 | 82.6 TFLOPS | 330 TFLOPS | 450W |
RTX 3090 | Ampere | 10,496 | 328 | 35.6 TFLOPS | 142 TFLOPS | 350W |
RTX 2080 Ti | Turing | 4,352 | 544 | 13.4 TFLOPS | 108 TFLOPS | 250W |
Tesla V100 | Volta | 5,120 | 640 | 14.0 TFLOPS | 112 TFLOPS | 300W |
GTX 1080 Ti | Pascal | 3,584 | N/A | 11.3 TFLOPS | N/A | 250W |
A100 | Ampere | 6,912 | 432 | 19.5 TFLOPS | 312 TFLOPS | 400W |
This table illustrates the evolution of GPU architectures, highlighting the introduction of Tensor Cores and the significant performance boost they provide for specific workloads. It also demonstrates the trade-offs between computational capability and power consumption across different models and generations.
Conclusion
Tensor Cores and CUDA Cores represent two distinct approaches to GPU computing, each with its own strengths and applications. Tensor Cores excel in accelerating a vast array of specific mathematical operations crucial for AI and deep learning, offering unprecedented performance for matrix multiplication and convolution. CUDA Cores, on the other hand, provide versatility and broad applicability across a wide range of computational tasks, from graphics rendering to scientific simulations.
The choice between leveraging Tensor Cores or CUDA Cores can significantly impact the performance and efficiency of engineering applications, particularly in fields like AI, computer vision, and high-performance computing.
When selecting the appropriate core type for specific engineering tasks, consider the nature of the computations involved. For applications heavily reliant on matrix operations or deep learning inference, Tensor Cores offer superior performance. For more general-purpose computations or tasks requiring high precision, CUDA Cores remain the go-to solution.
To reiterate, CUDA cores and Tensor Cores are not the same. While both reside on NVIDIA GPUs, they serve distinct purposes and excel in different types of computations, reflecting the ongoing specialization in GPU architecture to meet diverse computing needs.
Frequently Asked Questions
- How do Tensor Cores achieve their high performance in matrix operations?
Tensor Cores use a specialized architecture that performs matrix multiply-accumulate operations in a single clock cycle, leveraging mixed-precision arithmetic and optimized data flow to achieve significantly higher throughput compared to traditional floating-point units. - Can CUDA Cores perform the same operations as Tensor Cores?
While CUDA Cores can theoretically perform the same operations, they are not optimized for the specific matrix computations that Tensor Cores excel at. CUDA Cores offer more flexibility but at lower performance for these specialized tasks. - How does the precision of Tensor Cores compare to CUDA Cores?
Early Tensor Cores were limited to FP16 and INT8 precision, while CUDA Cores typically support FP32 and FP64. However, newer generations of Tensor Cores have expanded to support FP32 and even FP64 operations, narrowing this gap. - What are the main programming differences when targeting Tensor Cores vs CUDA Cores?
Programming for Tensor Cores often involves using high-level deep learning frameworks or specialized libraries that automatically leverage these cores. CUDA Core programming typically requires more low-level control and explicit parallelism management using CUDA C/C++ or other CUDA-enabled languages. The tools are available for all major operating systems including Linux, Windows and MacOS. - How do Tensor Cores and CUDA Cores affect power consumption in GPUs?
Tensor Cores generally offer higher performance per watt for compatible operations. However, their specialized nature means they may be idle during general-purpose computations, potentially leading to less efficient overall power usage in mixed workloads compared to the more versatile CUDA Cores. - What future developments can we expect in GPU core architecture?
Future GPU architectures may see further integration of specialized cores for tasks like ray tracing, AI, and physics simulations. We might also see more flexible core designs that can dynamically adapt to different computational needs, blending the strengths of both Tensor and CUDA Cores. - How do Tensor Cores contribute to advancements in computer graphics?
Tensor Cores play a crucial role in AI-enhanced graphics techniques such as DLSS (Deep Learning Super Sampling) and AI-accelerated denoising in ray tracing. These applications leverage the cores' ability to quickly process neural networks, enabling real-time, high-quality rendering enhancements.
References
[1] NVIDIA. ResNet-50 v1.5 for TensorFlow [Internet]. Available from: https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_tensorflow
[2] Buck I, Foley T, Horn D, Sugerman J, Fatahalian K, Houston M, Hanrahan P. Brook for GPUs: stream computing on graphics hardware. [Internet]. 2004. Available from: https://graphics.stanford.edu/papers/brookgpu/brookgpu.pdf
Table of Contents
CUDA Cores vs Tensor Cores: Clearing the ConfusionThe Building Blocks of GPU AccelerationDecoding CUDA Cores: The Versatile WorkhorsesTensor Cores: Precision Engineered for AI and high-performance computing (HPC)Architectural Face-off: Tensor Cores vs CUDA CoresDesign Philosophy and Computational ApproachPrecision and Data Types: Balancing ActPerformance Metrics: Crunching the Numbers: Benchmarking Tensor Cores and CUDA CoresHarnessing the Power: Applications and Use CasesAI and Deep Learning: The Tensor Core DomainChallenges and Limitations: Understanding the Trade-offsProgramming Complexity and Optimization HurdlesHardware Constraints and Compatibility Issues